 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Global and Fine-Grained Perceptual Fusion for MLLM Embeddings Compatible with Hard Negative Amplification
Feb 05, 2026Multimodal embeddings serve as a bridge for aligning vision and language, with the two primary implementations -- CLIP-based and MLLM-based embedding models -- both limited to capturing only global semantic information. Although numerous studies have focused on fine-grained understanding, we observe that complex scenarios currently targeted by MLLM embeddings often involve a hybrid perceptual pattern of both global and fine-grained elements, thus necessitating a compatible fusion mechanism. In this paper, we propose Adaptive Global and Fine-grained perceptual Fusion for MLLM Embeddings (AGFF-Embed), a method that prompts the MLLM to generate multiple embeddings focusing on different dimensions of semantic information, which are then adaptively and smoothly aggregated. Furthermore, we adapt AGFF-Embed with the Explicit Gradient Amplification (EGA) technique to achieve in-batch hard negatives enhancement without requiring fine-grained editing of the dataset. Evaluation on the MMEB and MMVP-VLM benchmarks shows that AGFF-Embed comprehensively achieves state-of-the-art performance in both general and fine-grained understanding compared to other multimodal embedding models.
Explicit Discovery of Nonlinear Symmetries from Dynamic Data
Oct 02, 2025Symmetry is widely applied in problems such as the design of equivariant networks and the discovery of governing equations, but in complex scenarios, it is not known in advance. Most previous symmetry discovery methods are limited to linear symmetries, and recent attempts to discover nonlinear symmetries fail to explicitly get the Lie algebra subspace. In this paper, we propose LieNLSD, which is, to our knowledge, the first method capable of determining the number of infinitesimal generators with nonlinear terms and their explicit expressions. We specify a function library for the infinitesimal group action and aim to solve for its coefficient matrix, proving that its prolongation formula for differential equations, which governs dynamic data, is also linear with respect to the coefficient matrix. By substituting the central differences of the data and the Jacobian matrix of the trained neural network into the infinitesimal criterion, we get a system of linear equations for the coefficient matrix, which can then be solved using SVD. On top quark tagging and a series of dynamic systems, LieNLSD shows qualitative advantages over existing methods and improves the long rollout accuracy of neural PDE solvers by over 20% while applying to guide data augmentation. Code and data are available at https://github.com/hulx2002/LieNLSD.
Governing Equation Discovery from Data Based on Differential Invariants
May 24, 2025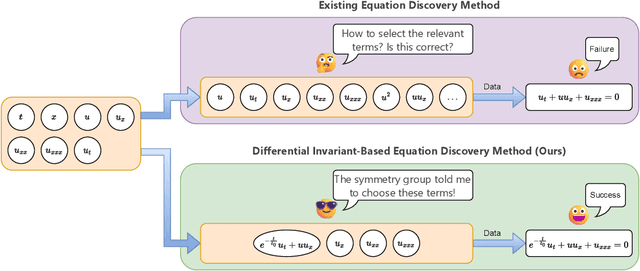

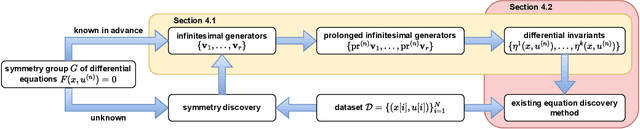
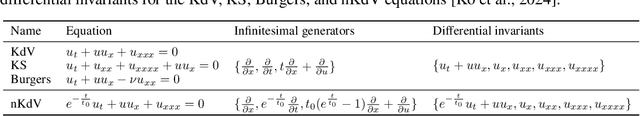
The explicit governing equation is one of the simplest and most intuitive forms for characterizing physical laws. However, directly discovering partial differential equations (PDEs) from data poses significant challenges, primarily in determining relevant terms from a vast search space. Symmetry, as a crucial prior knowledge in scientific fields, has been widely applied in tasks such as designing equivariant networks and guiding neural PDE solvers. In this paper, we propose a pipeline for governing equation discovery based on differential invariants, which can losslessly reduce the search space of existing equation discovery methods while strictly adhering to symmetry. Specifically, we compute the set of differential invariants corresponding to the infinitesimal generators of the symmetry group and select them as the relevant terms for equation discovery. Taking DI-SINDy (SINDy based on Differential Invariants) as an example, we demonstrate that its success rate and accuracy in PDE discovery surpass those of other symmetry-informed governing equation discovery methods across a series of PDEs.
Symmetry Discovery for Different Data Types
Oct 13, 2024Equivariant neural networks incorporate symmetries into their architecture, achieving higher generalization performance. However, constructing equivariant neural networks typically requires prior knowledge of data types and symmetries, which is difficult to achieve in most tasks. In this paper, we propose LieSD, a method for discovering symmetries via trained neural networks which approximate the input-output mappings of the tasks. It characterizes equivariance and invariance (a special case of equivariance) of continuous groups using Lie algebra and directly solves the Lie algebra space through the inputs, outputs, and gradients of the trained neural network. Then, we extend the method to make it applicable to multi-channel data and tensor data, respectively. We validate the performance of LieSD on tasks with symmetries such as the two-body problem, the moment of inertia matrix prediction, and top quark tagging. Compared with the baseline, LieSD can accurately determine the number of Lie algebra bases without the need for expensive group sampling. Furthermore, LieSD can perform well on non-uniform datasets, whereas methods based on GANs fail.
EKAN: Equivariant Kolmogorov-Arnold Networks
Oct 01, 2024Kolmogorov-Arnold Networks (KANs) have seen great success in scientific domains thanks to spline activation functions, becoming an alternative to Multi-Layer Perceptrons (MLPs). However, spline functions may not respect symmetry in tasks, which is crucial prior knowledge in machine learning. Previously, equivariant networks embed symmetry into their architectures, achieving better performance in specific applications. Among these, Equivariant Multi-Layer Perceptrons (EMLP) introduce arbitrary matrix group equivariance into MLPs, providing a general framework for constructing equivariant networks layer by layer. In this paper, we propose Equivariant Kolmogorov-Arnold Networks (EKAN), a method for incorporating matrix group equivariance into KANs, aiming to broaden their applicability to more fields. First, we construct gated spline basis functions, which form the EKAN layer together with equivariant linear weights. We then define a lift layer to align the input space of EKAN with the feature space of the dataset, thereby building the entire EKAN architecture. Compared with baseline models, EKAN achieves higher accuracy with smaller datasets or fewer parameters on symmetry-related tasks, such as particle scattering and the three-body problem, often reducing test MSE by several orders of magnitude. Even in non-symbolic formula scenarios, such as top quark tagging with three jet constituents, EKAN achieves comparable results with EMLP using only $26\%$ of the parameters, while KANs do not outperform MLPs as expected.