 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSidewalkBench: Benchmarking Visual Navigation on Urban Sidewalks
Jun 15, 2026Urban sidewalk navigation presents significant challenges due to complex structural layouts, dynamic pedestrian behaviors, and long distances. While recent visual navigation models offer a promising solution, the lack of a unified benchmark hinders quantitative and reproducible evaluation. To bridge this gap, we propose SidewalkBench, a comprehensive benchmark designed for visual navigation on urban sidewalks. Built upon NVIDIA Isaac Sim, SidewalkBench brings GPU-accelerated simulation of diverse, high-fidelity sidewalk environments, including both procedurally generated and real-world scanned scenes. We further populate the scenes with rich, reactive event-based pedestrian behaviors and flexible, efficient animation, enabling standardized model evaluation under realistic real-world settings. We conduct a comprehensive evaluation of 9 visual navigation models on 330 unit-test scenarios, 800 pedestrian-reactive scenarios, and 105 long-horizon scenarios. Our findings highlight that pedestrian interaction and long-horizon robustness remain critical bottlenecks for existing models, and scaling up sidewalk training with synthetic data emerges as a promising solution.
From Imitation to Alignment: Human-Preference Flow Policies for Long-Horizon Sidewalk Navigation
Jun 10, 2026Autonomous long-horizon sidewalk navigation is essential for micro-mobility applications such as robotic food delivery and assistive electronic wheelchairs. Unlike autonomous driving on the road, long-horizon sidewalk navigation requires precise maneuvering through unpredictable sidewalk terrains and pedestrians, with a lightweight perception stack as minimal as a single monocular RGB camera. While imitation learning (IL) from demonstrations offers a practical solution, the resulting autopilot policy often suffers from compounding errors, a lack of social compliance on sidewalks, and deficiencies in counterfactual reasoning to handle complex situations. To address these challenges, we introduce FlowPilot, a mapless navigation policy that achieves robust and efficient long-horizon navigation performance using only a monocular RGB camera. We first propose to use anchored flow matching as an action representation for policy pre-training on large-scale robot fleet data and to capture the diverse, complex, multimodal distribution of sidewalk navigation behaviors. To bridge the gap between imitation and alignment, we further design a human-in-the-loop preference learning scheme to tune the policy on a small amount of human intervention data. It strengthens the model's counterfactual reasoning and social compliance on sidewalks. We evaluate FlowPilot through extensive simulation and real-world experiments in diverse sidewalk environments. FlowPilot achieves 42% success rate and 66% route completion in simulation, while FlowPilot-HP further improves real-world robustness and social compliance, reducing IR by 40.0% and NIR by 52.1% relative to the base model.
Vista4D: Video Reshooting with 4D Point Clouds
Apr 23, 2026We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and failing to maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition. See our project page for results, code, and models: https://eyeline-labs.github.io/Vista4D
Data-Efficient Learning from Human Interventions for Mobile Robots
Mar 06, 2025



Mobile robots are essential in applications such as autonomous delivery and hospitality services. Applying learning-based methods to address mobile robot tasks has gained popularity due to its robustness and generalizability. Traditional methods such as Imitation Learning (IL) and Reinforcement Learning (RL) offer adaptability but require large datasets, carefully crafted reward functions, and face sim-to-real gaps, making them challenging for efficient and safe real-world deployment. We propose an online human-in-the-loop learning method PVP4Real that combines IL and RL to address these issues. PVP4Real enables efficient real-time policy learning from online human intervention and demonstration, without reward or any pretraining, significantly improving data efficiency and training safety. We validate our method by training two different robots -- a legged quadruped, and a wheeled delivery robot -- in two mobile robot tasks, one of which even uses raw RGBD image as observation. The training finishes within 15 minutes. Our experiments show the promising future of human-in-the-loop learning in addressing the data efficiency issue in real-world robotic tasks. More information is available at: https://metadriverse.github.io/pvp4real/
Vid2Sim: Realistic and Interactive Simulation from Video for Urban Navigation
Jan 14, 2025Sim-to-real gap has long posed a significant challenge for robot learning in simulation, preventing the deployment of learned models in the real world. Previous work has primarily focused on domain randomization and system identification to mitigate this gap. However, these methods are often limited by the inherent constraints of the simulation and graphics engines. In this work, we propose Vid2Sim, a novel framework that effectively bridges the sim2real gap through a scalable and cost-efficient real2sim pipeline for neural 3D scene reconstruction and simulation. Given a monocular video as input, Vid2Sim can generate photorealistic and physically interactable 3D simulation environments to enable the reinforcement learning of visual navigation agents in complex urban environments. Extensive experiments demonstrate that Vid2Sim significantly improves the performance of urban navigation in the digital twins and real world by 31.2% and 68.3% in success rate compared with agents trained with prior simulation methods.
Joint Optimization for 4D Human-Scene Reconstruction in the Wild
Jan 04, 2025



Reconstructing human motion and its surrounding environment is crucial for understanding human-scene interaction and predicting human movements in the scene. While much progress has been made in capturing human-scene interaction in constrained environments, those prior methods can hardly reconstruct the natural and diverse human motion and scene context from web videos. In this work, we propose JOSH, a novel optimization-based method for 4D human-scene reconstruction in the wild from monocular videos. JOSH uses techniques in both dense scene reconstruction and human mesh recovery as initialization, and then it leverages the human-scene contact constraints to jointly optimize the scene, the camera poses, and the human motion. Experiment results show JOSH achieves better results on both global human motion estimation and dense scene reconstruction by joint optimization of scene geometry and human motion. We further design a more efficient model, JOSH3R, and directly train it with pseudo-labels from web videos. JOSH3R outperforms other optimization-free methods by only training with labels predicted from JOSH, further demonstrating its accuracy and generalization ability.
Learning to Generate Diverse Pedestrian Movements from Web Videos with Noisy Labels
Oct 10, 2024



Understanding and modeling pedestrian movements in the real world is crucial for applications like motion forecasting and scene simulation. Many factors influence pedestrian movements, such as scene context, individual characteristics, and goals, which are often ignored by the existing human generation methods. Web videos contain natural pedestrian behavior and rich motion context, but annotating them with pre-trained predictors leads to noisy labels. In this work, we propose learning diverse pedestrian movements from web videos. We first curate a large-scale dataset called CityWalkers that captures diverse real-world pedestrian movements in urban scenes. Then, based on CityWalkers, we propose a generative model called PedGen for diverse pedestrian movement generation. PedGen introduces automatic label filtering to remove the low-quality labels and a mask embedding to train with partial labels. It also contains a novel context encoder that lifts the 2D scene context to 3D and can incorporate various context factors in generating realistic pedestrian movements in urban scenes. Experiments show that PedGen outperforms existing baseline methods for pedestrian movement generation by learning from noisy labels and incorporating the context factors. In addition, PedGen achieves zero-shot generalization in both real-world and simulated environments. The code, model, and data will be made publicly available at https://genforce.github.io/PedGen/ .
MetaUrban: A Simulation Platform for Embodied AI in Urban Spaces
Jul 11, 2024



Public urban spaces like streetscapes and plazas serve residents and accommodate social life in all its vibrant variations. Recent advances in Robotics and Embodied AI make public urban spaces no longer exclusive to humans. Food delivery bots and electric wheelchairs have started sharing sidewalks with pedestrians, while diverse robot dogs and humanoids have recently emerged in the street. Ensuring the generalizability and safety of these forthcoming mobile machines is crucial when navigating through the bustling streets in urban spaces. In this work, we present MetaUrban, a compositional simulation platform for Embodied AI research in urban spaces. MetaUrban can construct an infinite number of interactive urban scenes from compositional elements, covering a vast array of ground plans, object placements, pedestrians, vulnerable road users, and other mobile agents' appearances and dynamics. We design point navigation and social navigation tasks as the pilot study using MetaUrban for embodied AI research and establish various baselines of Reinforcement Learning and Imitation Learning. Experiments demonstrate that the compositional nature of the simulated environments can substantially improve the generalizability and safety of the trained mobile agents. MetaUrban will be made publicly available to provide more research opportunities and foster safe and trustworthy embodied AI in urban spaces.
COOLer: Class-Incremental Learning for Appearance-Based Multiple Object Tracking
Oct 05, 2023



Continual learning allows a model to learn multiple tasks sequentially while retaining the old knowledge without the training data of the preceding tasks. This paper extends the scope of continual learning research to class-incremental learning for multiple object tracking (MOT), which is desirable to accommodate the continuously evolving needs of autonomous systems. Previous solutions for continual learning of object detectors do not address the data association stage of appearance-based trackers, leading to catastrophic forgetting of previous classes' re-identification features. We introduce COOLer, a COntrastive- and cOntinual-Learning-based tracker, which incrementally learns to track new categories while preserving past knowledge by training on a combination of currently available ground truth labels and pseudo-labels generated by the past tracker. To further exacerbate the disentanglement of instance representations, we introduce a novel contrastive class-incremental instance representation learning technique. Finally, we propose a practical evaluation protocol for continual learning for MOT and conduct experiments on the BDD100K and SHIFT datasets. Experimental results demonstrate that COOLer continually learns while effectively addressing catastrophic forgetting of both tracking and detection. The code is available at https://github.com/BoSmallEar/COOLer.
ScenarioNet: Open-Source Platform for Large-Scale Traffic Scenario Simulation and Modeling
Jul 02, 2023
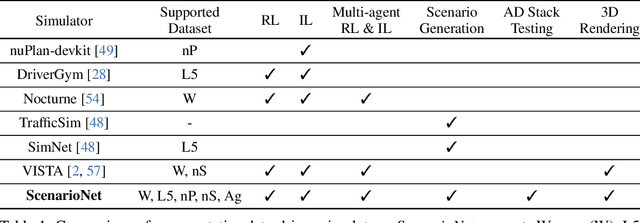

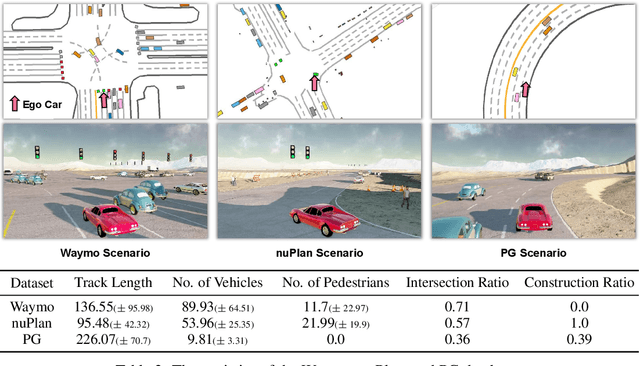
Large-scale driving datasets such as Waymo Open Dataset and nuScenes substantially accelerate autonomous driving research, especially for perception tasks such as 3D detection and trajectory forecasting. Since the driving logs in these datasets contain HD maps and detailed object annotations which accurately reflect the real-world complexity of traffic behaviors, we can harvest a massive number of complex traffic scenarios and recreate their digital twins in simulation. Compared to the hand-crafted scenarios often used in existing simulators, data-driven scenarios collected from the real world can facilitate many research opportunities in machine learning and autonomous driving. In this work, we present ScenarioNet, an open-source platform for large-scale traffic scenario modeling and simulation. ScenarioNet defines a unified scenario description format and collects a large-scale repository of real-world traffic scenarios from the heterogeneous data in various driving datasets including Waymo, nuScenes, Lyft L5, and nuPlan datasets. These scenarios can be further replayed and interacted with in multiple views from Bird-Eye-View layout to realistic 3D rendering in MetaDrive simulator. This provides a benchmark for evaluating the safety of autonomous driving stacks in simulation before their real-world deployment. We further demonstrate the strengths of ScenarioNet on large-scale scenario generation, imitation learning, and reinforcement learning in both single-agent and multi-agent settings. Code, demo videos, and website are available at https://metadriverse.github.io/scenarionet.