 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Micromobility through Scalable Urban Simulation
May 01, 2025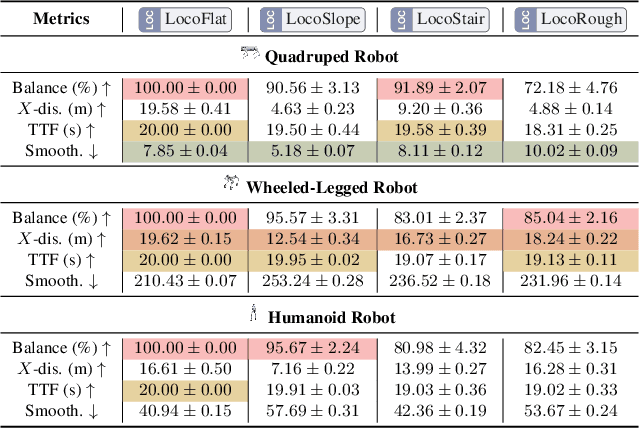

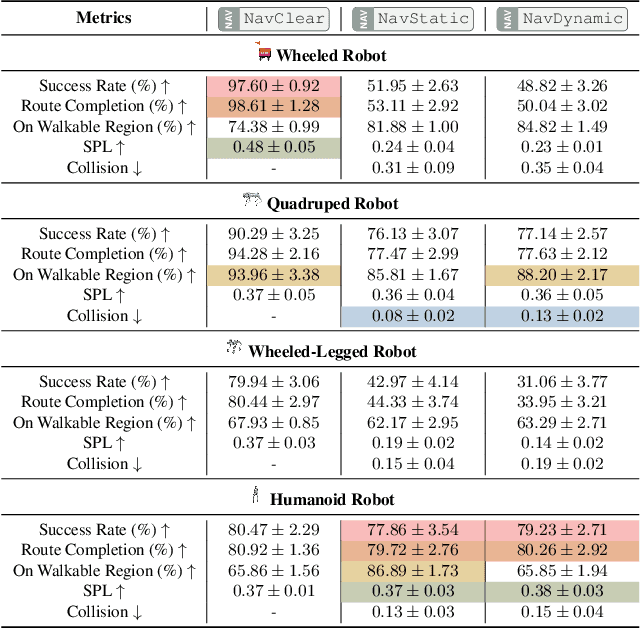
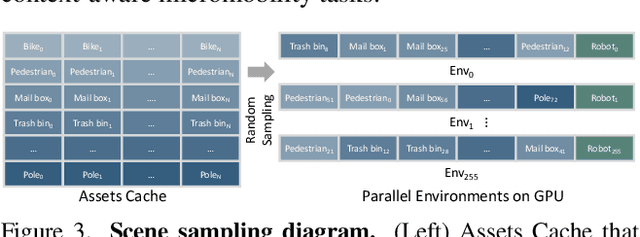
Micromobility, which utilizes lightweight mobile machines moving in urban public spaces, such as delivery robots and mobility scooters, emerges as a promising alternative to vehicular mobility. Current micromobility depends mostly on human manual operation (in-person or remote control), which raises safety and efficiency concerns when navigating busy urban environments full of unpredictable obstacles and pedestrians. Assisting humans with AI agents in maneuvering micromobility devices presents a viable solution for enhancing safety and efficiency. In this work, we present a scalable urban simulation solution to advance autonomous micromobility. First, we build URBAN-SIM - a high-performance robot learning platform for large-scale training of embodied agents in interactive urban scenes. URBAN-SIM contains three critical modules: Hierarchical Urban Generation pipeline, Interactive Dynamics Generation strategy, and Asynchronous Scene Sampling scheme, to improve the diversity, realism, and efficiency of robot learning in simulation. Then, we propose URBAN-BENCH - a suite of essential tasks and benchmarks to gauge various capabilities of the AI agents in achieving autonomous micromobility. URBAN-BENCH includes eight tasks based on three core skills of the agents: Urban Locomotion, Urban Navigation, and Urban Traverse. We evaluate four robots with heterogeneous embodiments, such as the wheeled and legged robots, across these tasks. Experiments on diverse terrains and urban structures reveal each robot's strengths and limitations.
Embedding Space Selection for Detecting Memorization and Fingerprinting in Generative Models
Jul 30, 2024In the rapidly evolving landscape of artificial intelligence, generative models such as Generative Adversarial Networks (GANs) and Diffusion Models have become cornerstone technologies, driving innovation in diverse fields from art creation to healthcare. Despite their potential, these models face the significant challenge of data memorization, which poses risks to privacy and the integrity of generated content. Among various metrics of memorization detection, our study delves into the memorization scores calculated from encoder layer embeddings, which involves measuring distances between samples in the embedding spaces. Particularly, we find that the memorization scores calculated from layer embeddings of Vision Transformers (ViTs) show an notable trend - the latter (deeper) the layer, the less the memorization measured. It has been found that the memorization scores from the early layers' embeddings are more sensitive to low-level memorization (e.g. colors and simple patterns for an image), while those from the latter layers are more sensitive to high-level memorization (e.g. semantic meaning of an image). We also observe that, for a specific model architecture, its degree of memorization on different levels of information is unique. It can be viewed as an inherent property of the architecture. Building upon this insight, we introduce a unique fingerprinting methodology. This method capitalizes on the unique distributions of the memorization score across different layers of ViTs, providing a novel approach to identifying models involved in generating deepfakes and malicious content. Our approach demonstrates a marked 30% enhancement in identification accuracy over existing baseline methods, offering a more effective tool for combating digital misinformation.
MetaUrban: A Simulation Platform for Embodied AI in Urban Spaces
Jul 11, 2024



Public urban spaces like streetscapes and plazas serve residents and accommodate social life in all its vibrant variations. Recent advances in Robotics and Embodied AI make public urban spaces no longer exclusive to humans. Food delivery bots and electric wheelchairs have started sharing sidewalks with pedestrians, while diverse robot dogs and humanoids have recently emerged in the street. Ensuring the generalizability and safety of these forthcoming mobile machines is crucial when navigating through the bustling streets in urban spaces. In this work, we present MetaUrban, a compositional simulation platform for Embodied AI research in urban spaces. MetaUrban can construct an infinite number of interactive urban scenes from compositional elements, covering a vast array of ground plans, object placements, pedestrians, vulnerable road users, and other mobile agents' appearances and dynamics. We design point navigation and social navigation tasks as the pilot study using MetaUrban for embodied AI research and establish various baselines of Reinforcement Learning and Imitation Learning. Experiments demonstrate that the compositional nature of the simulated environments can substantially improve the generalizability and safety of the trained mobile agents. MetaUrban will be made publicly available to provide more research opportunities and foster safe and trustworthy embodied AI in urban spaces.