 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-iEEG: A Large-Scale, Comprehensive iEEG Dataset and Benchmark for Epilepsy Research
Feb 19, 2026Epilepsy affects over 50 million people worldwide, and one-third of patients suffer drug-resistant seizures where surgery offers the best chance of seizure freedom. Accurate localization of the epileptogenic zone (EZ) relies on intracranial EEG (iEEG). Clinical workflows, however, remain constrained by labor-intensive manual review. At the same time, existing data-driven approaches are typically developed on single-center datasets that are inconsistent in format and metadata, lack standardized benchmarks, and rarely release pathological event annotations, creating barriers to reproducibility, cross-center validation, and clinical relevance. With extensive efforts to reconcile heterogeneous iEEG formats, metadata, and recordings across publicly available sources, we present $\textbf{Omni-iEEG}$, a large-scale, pre-surgical iEEG resource comprising $\textbf{302 patients}$ and $\textbf{178 hours}$ of high-resolution recordings. The dataset includes harmonized clinical metadata such as seizure onset zones, resections, and surgical outcomes, all validated by board-certified epileptologists. In addition, Omni-iEEG provides over 36K expert-validated annotations of pathological events, enabling robust biomarker studies. Omni-iEEG serves as a bridge between machine learning and epilepsy research. It defines clinically meaningful tasks with unified evaluation metrics grounded in clinical priors, enabling systematic evaluation of models in clinically relevant settings. Beyond benchmarking, we demonstrate the potential of end-to-end modeling on long iEEG segments and highlight the transferability of representations pretrained on non-neurophysiological domains. Together, these contributions establish Omni-iEEG as a foundation for reproducible, generalizable, and clinically translatable epilepsy research. The project page with dataset and code links is available at omni-ieeg.github.io/omni-ieeg.
Panini: Continual Learning in Token Space via Structured Memory
Feb 16, 2026Language models are increasingly used to reason over content they were not trained on, such as new documents, evolving knowledge, and user-specific data. A common approach is retrieval-augmented generation (RAG), which stores verbatim documents externally (as chunks) and retrieves only a relevant subset at inference time for an LLM to reason over. However, this results in inefficient usage of test-time compute (LLM repeatedly reasons over the same documents); moreover, chunk retrieval can inject irrelevant context that increases unsupported generation. We propose a human-like non-parametric continual learning framework, where the base model remains fixed, and learning occurs by integrating each new experience into an external semantic memory state that accumulates and consolidates itself continually. We present Panini, which realizes this by representing documents as Generative Semantic Workspaces (GSW) -- an entity- and event-aware network of question-answer (QA) pairs, sufficient for an LLM to reconstruct the experienced situations and mine latent knowledge via reasoning-grounded inference chains on the network. Given a query, Panini only traverses the continually-updated GSW (not the verbatim documents or chunks), and retrieves the most likely inference chains. Across six QA benchmarks, Panini achieves the highest average performance, 5%-7% higher than other competitive baselines, while using 2-30x fewer answer-context tokens, supports fully open-source pipelines, and reduces unsupported answers on curated unanswerable queries. The results show that efficient and accurate structuring of experiences at write time -- as achieved by the GSW framework -- yields both efficiency and reliability gains at read time. Code is available at https://github.com/roychowdhuryresearch/gsw-memory.
Beyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces
Nov 10, 2025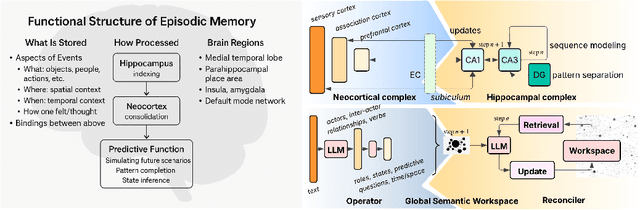
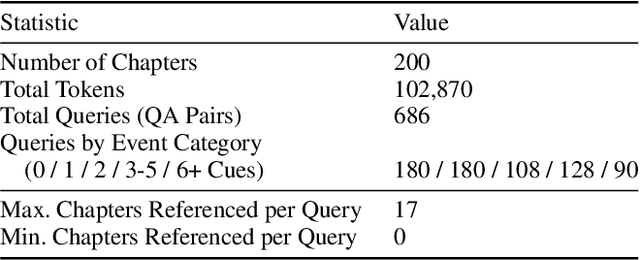
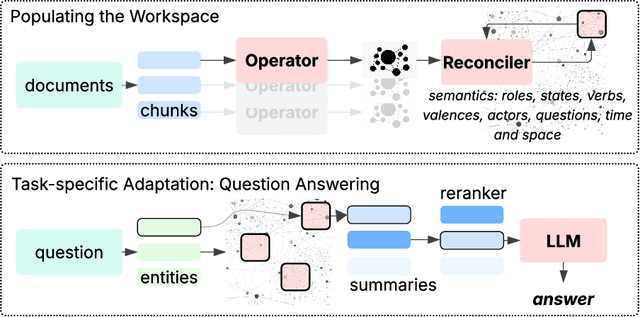
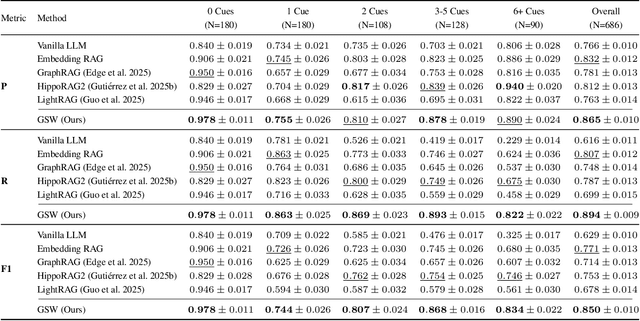
Large Language Models (LLMs) face fundamental challenges in long-context reasoning: many documents exceed their finite context windows, while performance on texts that do fit degrades with sequence length, necessitating their augmentation with external memory frameworks. Current solutions, which have evolved from retrieval using semantic embeddings to more sophisticated structured knowledge graphs representations for improved sense-making and associativity, are tailored for fact-based retrieval and fail to build the space-time-anchored narrative representations required for tracking entities through episodic events. To bridge this gap, we propose the \textbf{Generative Semantic Workspace} (GSW), a neuro-inspired generative memory framework that builds structured, interpretable representations of evolving situations, enabling LLMs to reason over evolving roles, actions, and spatiotemporal contexts. Our framework comprises an \textit{Operator}, which maps incoming observations to intermediate semantic structures, and a \textit{Reconciler}, which integrates these into a persistent workspace that enforces temporal, spatial, and logical coherence. On the Episodic Memory Benchmark (EpBench) \cite{huet_episodic_2025} comprising corpora ranging from 100k to 1M tokens in length, GSW outperforms existing RAG based baselines by up to \textbf{20\%}. Furthermore, GSW is highly efficient, reducing query-time context tokens by \textbf{51\%} compared to the next most token-efficient baseline, reducing inference time costs considerably. More broadly, GSW offers a concrete blueprint for endowing LLMs with human-like episodic memory, paving the way for more capable agents that can reason over long horizons.
Learning from Active Human Involvement through Proxy Value Propagation
Feb 05, 2025Learning from active human involvement enables the human subject to actively intervene and demonstrate to the AI agent during training. The interaction and corrective feedback from human brings safety and AI alignment to the learning process. In this work, we propose a new reward-free active human involvement method called Proxy Value Propagation for policy optimization. Our key insight is that a proxy value function can be designed to express human intents, wherein state-action pairs in the human demonstration are labeled with high values, while those agents' actions that are intervened receive low values. Through the TD-learning framework, labeled values of demonstrated state-action pairs are further propagated to other unlabeled data generated from agents' exploration. The proxy value function thus induces a policy that faithfully emulates human behaviors. Human-in-the-loop experiments show the generality and efficiency of our method. With minimal modification to existing reinforcement learning algorithms, our method can learn to solve continuous and discrete control tasks with various human control devices, including the challenging task of driving in Grand Theft Auto V. Demo video and code are available at: https://metadriverse.github.io/pvp
Embodied Scene Understanding for Vision Language Models via MetaVQA
Jan 15, 2025



Vision Language Models (VLMs) demonstrate significant potential as embodied AI agents for various mobility applications. However, a standardized, closed-loop benchmark for evaluating their spatial reasoning and sequential decision-making capabilities is lacking. To address this, we present MetaVQA: a comprehensive benchmark designed to assess and enhance VLMs' understanding of spatial relationships and scene dynamics through Visual Question Answering (VQA) and closed-loop simulations. MetaVQA leverages Set-of-Mark prompting and top-down view ground-truth annotations from nuScenes and Waymo datasets to automatically generate extensive question-answer pairs based on diverse real-world traffic scenarios, ensuring object-centric and context-rich instructions. Our experiments show that fine-tuning VLMs with the MetaVQA dataset significantly improves their spatial reasoning and embodied scene comprehension in safety-critical simulations, evident not only in improved VQA accuracies but also in emerging safety-aware driving maneuvers. In addition, the learning demonstrates strong transferability from simulation to real-world observation. Code and data will be publicly available at https://metadriverse.github.io/metavqa .
MetaUrban: A Simulation Platform for Embodied AI in Urban Spaces
Jul 11, 2024



Public urban spaces like streetscapes and plazas serve residents and accommodate social life in all its vibrant variations. Recent advances in Robotics and Embodied AI make public urban spaces no longer exclusive to humans. Food delivery bots and electric wheelchairs have started sharing sidewalks with pedestrians, while diverse robot dogs and humanoids have recently emerged in the street. Ensuring the generalizability and safety of these forthcoming mobile machines is crucial when navigating through the bustling streets in urban spaces. In this work, we present MetaUrban, a compositional simulation platform for Embodied AI research in urban spaces. MetaUrban can construct an infinite number of interactive urban scenes from compositional elements, covering a vast array of ground plans, object placements, pedestrians, vulnerable road users, and other mobile agents' appearances and dynamics. We design point navigation and social navigation tasks as the pilot study using MetaUrban for embodied AI research and establish various baselines of Reinforcement Learning and Imitation Learning. Experiments demonstrate that the compositional nature of the simulated environments can substantially improve the generalizability and safety of the trained mobile agents. MetaUrban will be made publicly available to provide more research opportunities and foster safe and trustworthy embodied AI in urban spaces.
ScenarioNet: Open-Source Platform for Large-Scale Traffic Scenario Simulation and Modeling
Jul 02, 2023
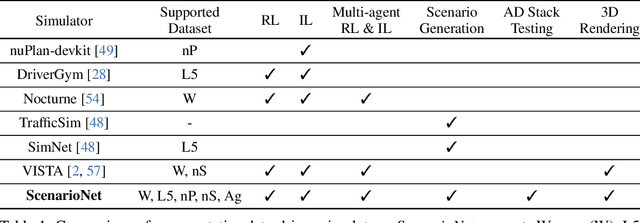

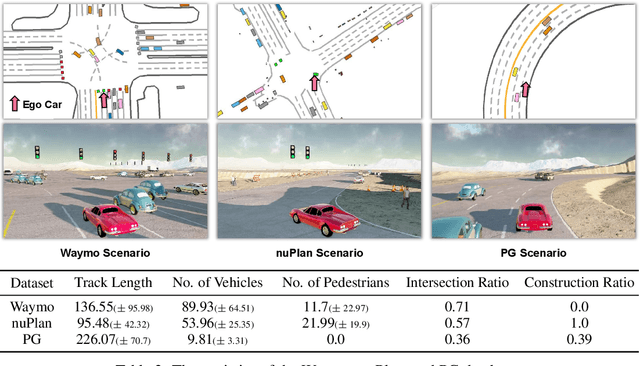
Large-scale driving datasets such as Waymo Open Dataset and nuScenes substantially accelerate autonomous driving research, especially for perception tasks such as 3D detection and trajectory forecasting. Since the driving logs in these datasets contain HD maps and detailed object annotations which accurately reflect the real-world complexity of traffic behaviors, we can harvest a massive number of complex traffic scenarios and recreate their digital twins in simulation. Compared to the hand-crafted scenarios often used in existing simulators, data-driven scenarios collected from the real world can facilitate many research opportunities in machine learning and autonomous driving. In this work, we present ScenarioNet, an open-source platform for large-scale traffic scenario modeling and simulation. ScenarioNet defines a unified scenario description format and collects a large-scale repository of real-world traffic scenarios from the heterogeneous data in various driving datasets including Waymo, nuScenes, Lyft L5, and nuPlan datasets. These scenarios can be further replayed and interacted with in multiple views from Bird-Eye-View layout to realistic 3D rendering in MetaDrive simulator. This provides a benchmark for evaluating the safety of autonomous driving stacks in simulation before their real-world deployment. We further demonstrate the strengths of ScenarioNet on large-scale scenario generation, imitation learning, and reinforcement learning in both single-agent and multi-agent settings. Code, demo videos, and website are available at https://metadriverse.github.io/scenarionet.