 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPUS: A Lightweight and Parameter-Efficient Foundation Model for PDEs
Oct 01, 2025We introduce Small PDE U-Net Solver (SPUS), a compact and efficient foundation model (FM) designed as a unified neural operator for solving a wide range of partial differential equations (PDEs). Unlike existing state-of-the-art PDE FMs-primarily based on large complex transformer architectures with high computational and parameter overhead-SPUS leverages a lightweight residual U-Net-based architecture that has been largely underexplored as a foundation model architecture in this domain. To enable effective learning in this minimalist framework, we utilize a simple yet powerful auto-regressive pretraining strategy which closely replicates the behavior of numerical solvers to learn the underlying physics. SPUS is pretrained on a diverse set of fluid dynamics PDEs and evaluated across 6 challenging unseen downstream PDEs spanning various physical systems. Experimental results demonstrate that SPUS using residual U-Net based architecture achieves state-of-the-art generalization on these downstream tasks while requiring significantly fewer parameters and minimal fine-tuning data, highlighting its potential as a highly parameter-efficient FM for solving diverse PDE systems.
LLM-Assisted Translation of Legacy FORTRAN Codes to C++: A Cross-Platform Study
Apr 21, 2025Large Language Models (LLMs) are increasingly being leveraged for generating and translating scientific computer codes by both domain-experts and non-domain experts. Fortran has served as one of the go to programming languages in legacy high-performance computing (HPC) for scientific discoveries. Despite growing adoption, LLM-based code translation of legacy code-bases has not been thoroughly assessed or quantified for its usability. Here, we studied the applicability of LLM-based translation of Fortran to C++ as a step towards building an agentic-workflow using open-weight LLMs on two different computational platforms. We statistically quantified the compilation accuracy of the translated C++ codes, measured the similarity of the LLM translated code to the human translated C++ code, and statistically quantified the output similarity of the Fortran to C++ translation.
Posterior Mean Matching: Generative Modeling through Online Bayesian Inference
Dec 17, 2024This paper introduces posterior mean matching (PMM), a new method for generative modeling that is grounded in Bayesian inference. PMM uses conjugate pairs of distributions to model complex data of various modalities like images and text, offering a flexible alternative to existing methods like diffusion models. PMM models iteratively refine noisy approximations of the target distribution using updates from online Bayesian inference. PMM is flexible because its mechanics are based on general Bayesian models. We demonstrate this flexibility by developing specialized examples: a generative PMM model of real-valued data using the Normal-Normal model, a generative PMM model of count data using a Gamma-Poisson model, and a generative PMM model of discrete data using a Dirichlet-Categorical model. For the Normal-Normal PMM model, we establish a direct connection to diffusion models by showing that its continuous-time formulation converges to a stochastic differential equation (SDE). Additionally, for the Gamma-Poisson PMM, we derive a novel SDE driven by a Cox process, which is a significant departure from traditional Brownian motion-based generative models. PMMs achieve performance that is competitive with generative models for language modeling and image generation.
How Robust Are Energy-Based Models Trained With Equilibrium Propagation?
Jan 21, 2024Deep neural networks (DNNs) are easily fooled by adversarial perturbations that are imperceptible to humans. Adversarial training, a process where adversarial examples are added to the training set, is the current state-of-the-art defense against adversarial attacks, but it lowers the model's accuracy on clean inputs, is computationally expensive, and offers less robustness to natural noise. In contrast, energy-based models (EBMs), which were designed for efficient implementation in neuromorphic hardware and physical systems, incorporate feedback connections from each layer to the previous layer, yielding a recurrent, deep-attractor architecture which we hypothesize should make them naturally robust. Our work is the first to explore the robustness of EBMs to both natural corruptions and adversarial attacks, which we do using the CIFAR-10 and CIFAR-100 datasets. We demonstrate that EBMs are more robust than transformers and display comparable robustness to adversarially-trained DNNs on gradient-based (white-box) attacks, query-based (black-box) attacks, and natural perturbations without sacrificing clean accuracy, and without the need for adversarial training or additional training techniques.
DeepPatent2: A Large-Scale Benchmarking Corpus for Technical Drawing Understanding
Nov 07, 2023Recent advances in computer vision (CV) and natural language processing have been driven by exploiting big data on practical applications. However, these research fields are still limited by the sheer volume, versatility, and diversity of the available datasets. CV tasks, such as image captioning, which has primarily been carried out on natural images, still struggle to produce accurate and meaningful captions on sketched images often included in scientific and technical documents. The advancement of other tasks such as 3D reconstruction from 2D images requires larger datasets with multiple viewpoints. We introduce DeepPatent2, a large-scale dataset, providing more than 2.7 million technical drawings with 132,890 object names and 22,394 viewpoints extracted from 14 years of US design patent documents. We demonstrate the usefulness of DeepPatent2 with conceptual captioning. We further provide the potential usefulness of our dataset to facilitate other research areas such as 3D image reconstruction and image retrieval.
Robustness to Label Noise Depends on the Shape of the Noise Distribution in Feature Space
Jun 02, 2022

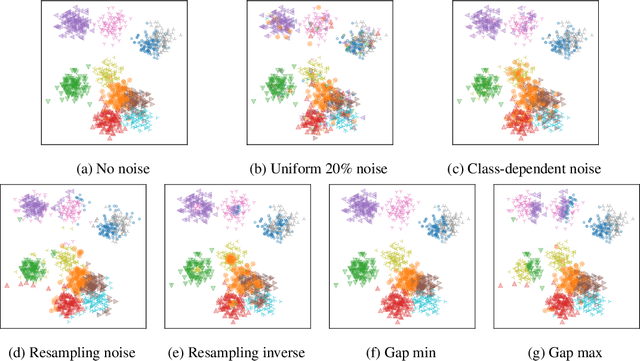
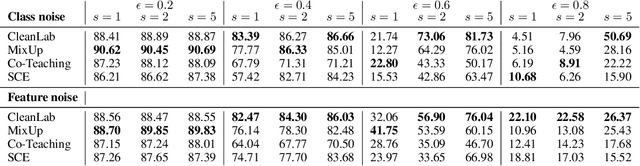
Machine learning classifiers have been demonstrated, both empirically and theoretically, to be robust to label noise under certain conditions -- notably the typical assumption is that label noise is independent of the features given the class label. We provide a theoretical framework that generalizes beyond this typical assumption by modeling label noise as a distribution over feature space. We show that both the scale and the shape of the noise distribution influence the posterior likelihood; and the shape of the noise distribution has a stronger impact on classification performance if the noise is concentrated in feature space where the decision boundary can be moved. For the special case of uniform label noise (independent of features and the class label), we show that the Bayes optimal classifier for $c$ classes is robust to label noise until the ratio of noisy samples goes above $\frac{c-1}{c}$ (e.g. 90% for 10 classes), which we call the tipping point. However, for the special case of class-dependent label noise (independent of features given the class label), the tipping point can be as low as 50%. Most importantly, we show that when the noise distribution targets decision boundaries (label noise is directly dependent on feature space), classification robustness can drop off even at a small scale of noise. Even when evaluating recent label-noise mitigation methods we see reduced accuracy when label noise is dependent on features. These findings explain why machine learning often handles label noise well if the noise distribution is uniform in feature-space; yet it also points to the difficulty of overcoming label noise when it is concentrated in a region of feature space where a decision boundary can move.
On visual self-supervision and its effect on model robustness
Dec 08, 2021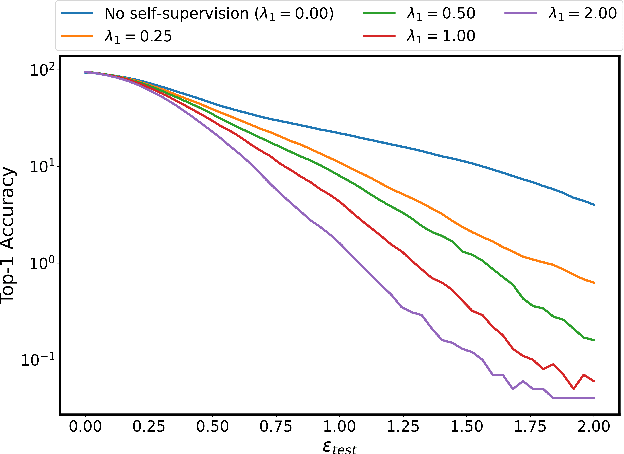

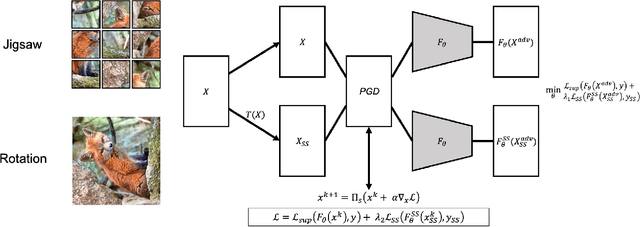

Recent self-supervision methods have found success in learning feature representations that could rival ones from full supervision, and have been shown to be beneficial to the model in several ways: for example improving models robustness and out-of-distribution detection. In our paper, we conduct an empirical study to understand more precisely in what way can self-supervised learning - as a pre-training technique or part of adversarial training - affects model robustness to $l_2$ and $l_{\infty}$ adversarial perturbations and natural image corruptions. Self-supervision can indeed improve model robustness, however it turns out the devil is in the details. If one simply adds self-supervision loss in tandem with adversarial training, then one sees improvement in accuracy of the model when evaluated with adversarial perturbations smaller or comparable to the value of $\epsilon_{train}$ that the robust model is trained with. However, if one observes the accuracy for $\epsilon_{test} \ge \epsilon_{train}$, the model accuracy drops. In fact, the larger the weight of the supervision loss, the larger the drop in performance, i.e. harming the robustness of the model. We identify primary ways in which self-supervision can be added to adversarial training, and observe that using a self-supervised loss to optimize both network parameters and find adversarial examples leads to the strongest improvement in model robustness, as this can be viewed as a form of ensemble adversarial training. Although self-supervised pre-training yields benefits in improving adversarial training as compared to random weight initialization, we observe no benefit in model robustness or accuracy if self-supervision is incorporated into adversarial training.