 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn visual self-supervision and its effect on model robustness
Paper and Code
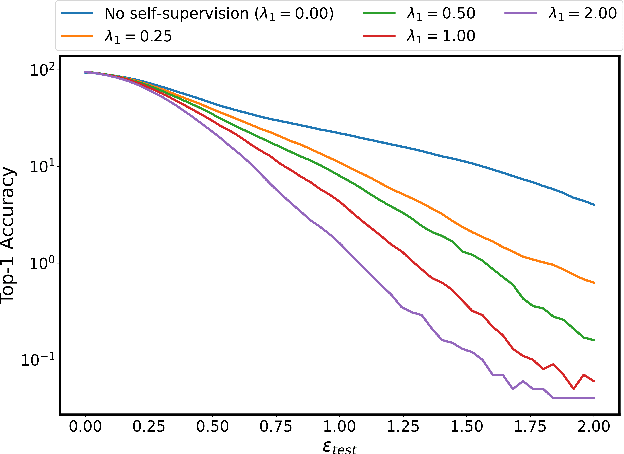

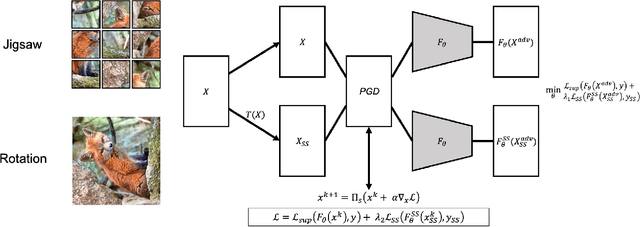

Recent self-supervision methods have found success in learning feature representations that could rival ones from full supervision, and have been shown to be beneficial to the model in several ways: for example improving models robustness and out-of-distribution detection. In our paper, we conduct an empirical study to understand more precisely in what way can self-supervised learning - as a pre-training technique or part of adversarial training - affects model robustness to $l_2$ and $l_{\infty}$ adversarial perturbations and natural image corruptions. Self-supervision can indeed improve model robustness, however it turns out the devil is in the details. If one simply adds self-supervision loss in tandem with adversarial training, then one sees improvement in accuracy of the model when evaluated with adversarial perturbations smaller or comparable to the value of $\epsilon_{train}$ that the robust model is trained with. However, if one observes the accuracy for $\epsilon_{test} \ge \epsilon_{train}$, the model accuracy drops. In fact, the larger the weight of the supervision loss, the larger the drop in performance, i.e. harming the robustness of the model. We identify primary ways in which self-supervision can be added to adversarial training, and observe that using a self-supervised loss to optimize both network parameters and find adversarial examples leads to the strongest improvement in model robustness, as this can be viewed as a form of ensemble adversarial training. Although self-supervised pre-training yields benefits in improving adversarial training as compared to random weight initialization, we observe no benefit in model robustness or accuracy if self-supervision is incorporated into adversarial training.