 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPUS: A Lightweight and Parameter-Efficient Foundation Model for PDEs
Oct 01, 2025We introduce Small PDE U-Net Solver (SPUS), a compact and efficient foundation model (FM) designed as a unified neural operator for solving a wide range of partial differential equations (PDEs). Unlike existing state-of-the-art PDE FMs-primarily based on large complex transformer architectures with high computational and parameter overhead-SPUS leverages a lightweight residual U-Net-based architecture that has been largely underexplored as a foundation model architecture in this domain. To enable effective learning in this minimalist framework, we utilize a simple yet powerful auto-regressive pretraining strategy which closely replicates the behavior of numerical solvers to learn the underlying physics. SPUS is pretrained on a diverse set of fluid dynamics PDEs and evaluated across 6 challenging unseen downstream PDEs spanning various physical systems. Experimental results demonstrate that SPUS using residual U-Net based architecture achieves state-of-the-art generalization on these downstream tasks while requiring significantly fewer parameters and minimal fine-tuning data, highlighting its potential as a highly parameter-efficient FM for solving diverse PDE systems.
Graph Neural Networks for Parameterized Quantum Circuits Expressibility Estimation
May 13, 2024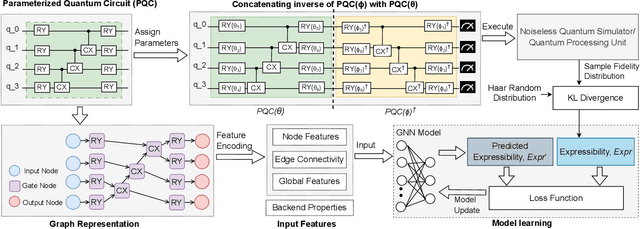


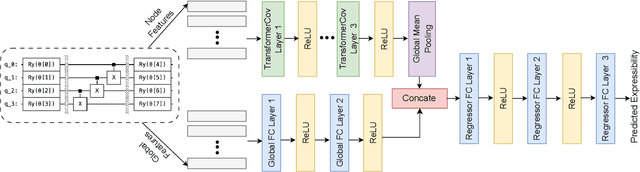
Parameterized quantum circuits (PQCs) are fundamental to quantum machine learning (QML), quantum optimization, and variational quantum algorithms (VQAs). The expressibility of PQCs is a measure that determines their capability to harness the full potential of the quantum state space. It is thus a crucial guidepost to know when selecting a particular PQC ansatz. However, the existing technique for expressibility computation through statistical estimation requires a large number of samples, which poses significant challenges due to time and computational resource constraints. This paper introduces a novel approach for expressibility estimation of PQCs using Graph Neural Networks (GNNs). We demonstrate the predictive power of our GNN model with a dataset consisting of 25,000 samples from the noiseless IBM QASM Simulator and 12,000 samples from three distinct noisy quantum backends. The model accurately estimates expressibility, with root mean square errors (RMSE) of 0.05 and 0.06 for the noiseless and noisy backends, respectively. We compare our model's predictions with reference circuits [Sim and others, QuTe'2019] and IBM Qiskit's hardware-efficient ansatz sets to further evaluate our model's performance. Our experimental evaluation in noiseless and noisy scenarios reveals a close alignment with ground truth expressibility values, highlighting the model's efficacy. Moreover, our model exhibits promising extrapolation capabilities, predicting expressibility values with low RMSE for out-of-range qubit circuits trained solely on only up to 5-qubit circuit sets. This work thus provides a reliable means of efficiently evaluating the expressibility of diverse PQCs on noiseless simulators and hardware.
DeepPatent2: A Large-Scale Benchmarking Corpus for Technical Drawing Understanding
Nov 07, 2023Recent advances in computer vision (CV) and natural language processing have been driven by exploiting big data on practical applications. However, these research fields are still limited by the sheer volume, versatility, and diversity of the available datasets. CV tasks, such as image captioning, which has primarily been carried out on natural images, still struggle to produce accurate and meaningful captions on sketched images often included in scientific and technical documents. The advancement of other tasks such as 3D reconstruction from 2D images requires larger datasets with multiple viewpoints. We introduce DeepPatent2, a large-scale dataset, providing more than 2.7 million technical drawings with 132,890 object names and 22,394 viewpoints extracted from 14 years of US design patent documents. We demonstrate the usefulness of DeepPatent2 with conceptual captioning. We further provide the potential usefulness of our dataset to facilitate other research areas such as 3D image reconstruction and image retrieval.
Discovering Image Usage Online: A Case Study With "Flatten the Curve''
Jul 12, 2023Understanding the spread of images across the web helps us understand the reuse of scientific visualizations and their relationship with the public. The "Flatten the Curve" graphic was heavily used during the COVID-19 pandemic to convey a complex concept in a simple form. It displays two curves comparing the impact on case loads for medical facilities if the populace either adopts or fails to adopt protective measures during a pandemic. We use five variants of the "Flatten the Curve" image as a case study for viewing the spread of an image online. To evaluate its spread, we leverage three information channels: reverse image search engines, social media, and web archives. Reverse image searches give us a current view into image reuse. Social media helps us understand a variant's popularity over time. Web archives help us see when it was preserved, highlighting a view of popularity for future researchers. Our case study leverages document URLs can be used as a proxy for images when studying the spread of images online.
Semi-supervised Learning of Pushforwards For Domain Translation & Adaptation
Apr 18, 2023Given two probability densities on related data spaces, we seek a map pushing one density to the other while satisfying application-dependent constraints. For maps to have utility in a broad application space (including domain translation, domain adaptation, and generative modeling), the map must be available to apply on out-of-sample data points and should correspond to a probabilistic model over the two spaces. Unfortunately, existing approaches, which are primarily based on optimal transport, do not address these needs. In this paper, we introduce a novel pushforward map learning algorithm that utilizes normalizing flows to parameterize the map. We first re-formulate the classical optimal transport problem to be map-focused and propose a learning algorithm to select from all possible maps under the constraint that the map minimizes a probability distance and application-specific regularizers; thus, our method can be seen as solving a modified optimal transport problem. Once the map is learned, it can be used to map samples from a source domain to a target domain. In addition, because the map is parameterized as a composition of normalizing flows, it models the empirical distributions over the two data spaces and allows both sampling and likelihood evaluation for both data sets. We compare our method (parOT) to related optimal transport approaches in the context of domain adaptation and domain translation on benchmark data sets. Finally, to illustrate the impact of our work on applied problems, we apply parOT to a real scientific application: spectral calibration for high-dimensional measurements from two vastly different environments
Generative structured normalizing flow Gaussian processes applied to spectroscopic data
Dec 14, 2022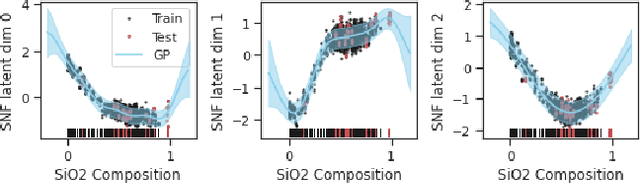
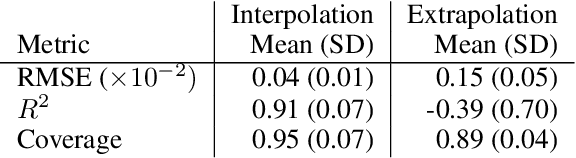
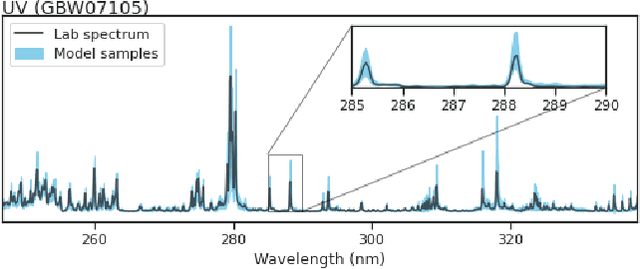
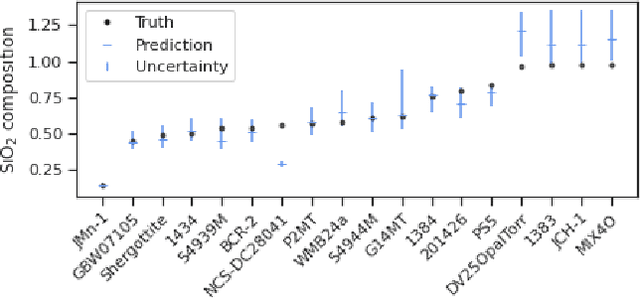
In this work, we propose a novel generative model for mapping inputs to structured, high-dimensional outputs using structured conditional normalizing flows and Gaussian process regression. The model is motivated by the need to characterize uncertainty in the input/output relationship when making inferences on new data. In particular, in the physical sciences, limited training data may not adequately characterize future observed data; it is critical that models adequately indicate uncertainty, particularly when they may be asked to extrapolate. In our proposed model, structured conditional normalizing flows provide parsimonious latent representations that relate to the inputs through a Gaussian process, providing exact likelihood calculations and uncertainty that naturally increases away from the training data inputs. We demonstrate the methodology on laser-induced breakdown spectroscopy data from the ChemCam instrument onboard the Mars rover Curiosity. ChemCam was designed to recover the chemical composition of rock and soil samples by measuring the spectral properties of plasma atomic emissions induced by a laser pulse. We show that our model can generate realistic spectra conditional on a given chemical composition and that we can use the model to perform uncertainty quantification of chemical compositions for new observed spectra. Based on our results, we anticipate that our proposed modeling approach may be useful in other scientific domains with high-dimensional, complex structure where it is important to quantify predictive uncertainty.
Abstract Images Have Different Levels of Retrievability Per Reverse Image Search Engine
Nov 03, 2022Much computer vision research has focused on natural images, but technical documents typically consist of abstract images, such as charts, drawings, diagrams, and schematics. How well do general web search engines discover abstract images? Recent advancements in computer vision and machine learning have led to the rise of reverse image search engines. Where conventional search engines accept a text query and return a set of document results, including images, a reverse image search accepts an image as a query and returns a set of images as results. This paper evaluates how well common reverse image search engines discover abstract images. We conducted an experiment leveraging images from Wikimedia Commons, a website known to be well indexed by Baidu, Bing, Google, and Yandex. We measure how difficult an image is to find again (retrievability), what percentage of images returned are relevant (precision), and the average number of results a visitor must review before finding the submitted image (mean reciprocal rank). When trying to discover the same image again among similar images, Yandex performs best. When searching for pages containing a specific image, Google and Yandex outperform the others when discovering photographs with precision scores ranging from 0.8191 to 0.8297, respectively. In both of these cases, Google and Yandex perform better with natural images than with abstract ones achieving a difference in retrievability as high as 54\% between images in these categories. These results affect anyone applying common web search engines to search for technical documents that use abstract images.
Robustness to Label Noise Depends on the Shape of the Noise Distribution in Feature Space
Jun 02, 2022

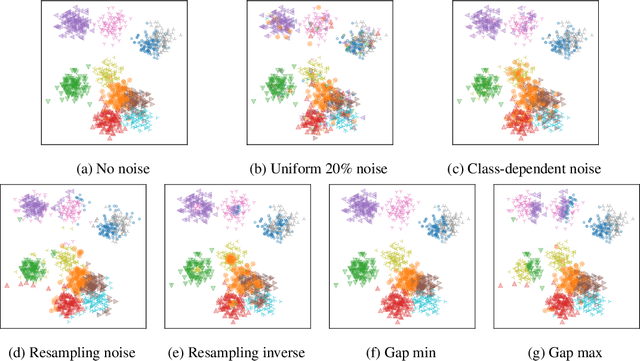
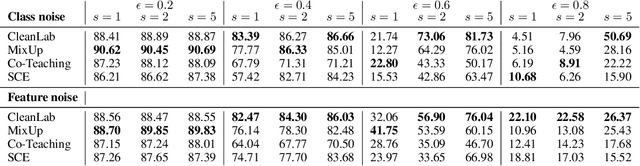
Machine learning classifiers have been demonstrated, both empirically and theoretically, to be robust to label noise under certain conditions -- notably the typical assumption is that label noise is independent of the features given the class label. We provide a theoretical framework that generalizes beyond this typical assumption by modeling label noise as a distribution over feature space. We show that both the scale and the shape of the noise distribution influence the posterior likelihood; and the shape of the noise distribution has a stronger impact on classification performance if the noise is concentrated in feature space where the decision boundary can be moved. For the special case of uniform label noise (independent of features and the class label), we show that the Bayes optimal classifier for $c$ classes is robust to label noise until the ratio of noisy samples goes above $\frac{c-1}{c}$ (e.g. 90% for 10 classes), which we call the tipping point. However, for the special case of class-dependent label noise (independent of features given the class label), the tipping point can be as low as 50%. Most importantly, we show that when the noise distribution targets decision boundaries (label noise is directly dependent on feature space), classification robustness can drop off even at a small scale of noise. Even when evaluating recent label-noise mitigation methods we see reduced accuracy when label noise is dependent on features. These findings explain why machine learning often handles label noise well if the noise distribution is uniform in feature-space; yet it also points to the difficulty of overcoming label noise when it is concentrated in a region of feature space where a decision boundary can move.
On visual self-supervision and its effect on model robustness
Dec 08, 2021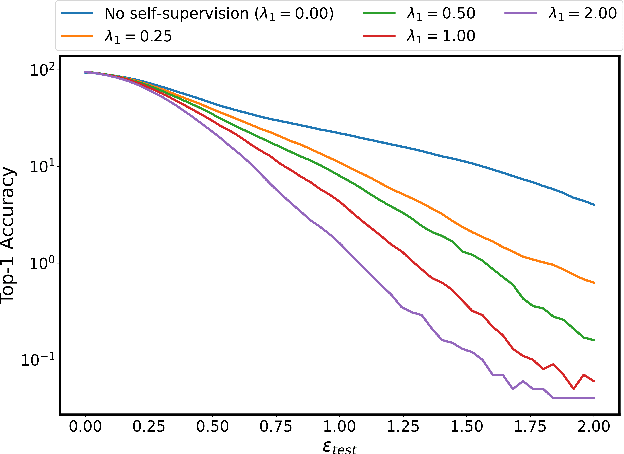

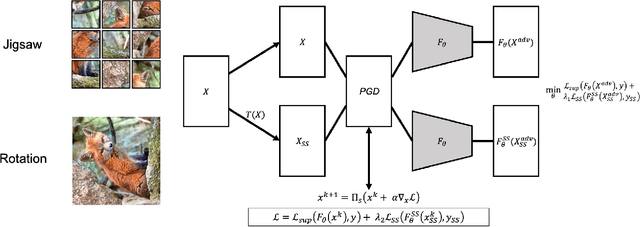

Recent self-supervision methods have found success in learning feature representations that could rival ones from full supervision, and have been shown to be beneficial to the model in several ways: for example improving models robustness and out-of-distribution detection. In our paper, we conduct an empirical study to understand more precisely in what way can self-supervised learning - as a pre-training technique or part of adversarial training - affects model robustness to $l_2$ and $l_{\infty}$ adversarial perturbations and natural image corruptions. Self-supervision can indeed improve model robustness, however it turns out the devil is in the details. If one simply adds self-supervision loss in tandem with adversarial training, then one sees improvement in accuracy of the model when evaluated with adversarial perturbations smaller or comparable to the value of $\epsilon_{train}$ that the robust model is trained with. However, if one observes the accuracy for $\epsilon_{test} \ge \epsilon_{train}$, the model accuracy drops. In fact, the larger the weight of the supervision loss, the larger the drop in performance, i.e. harming the robustness of the model. We identify primary ways in which self-supervision can be added to adversarial training, and observe that using a self-supervised loss to optimize both network parameters and find adversarial examples leads to the strongest improvement in model robustness, as this can be viewed as a form of ensemble adversarial training. Although self-supervised pre-training yields benefits in improving adversarial training as compared to random weight initialization, we observe no benefit in model robustness or accuracy if self-supervision is incorporated into adversarial training.
Learning to Pre-process Laser Induced Breakdown Spectroscopy Signals Without Clean Data
Oct 26, 2021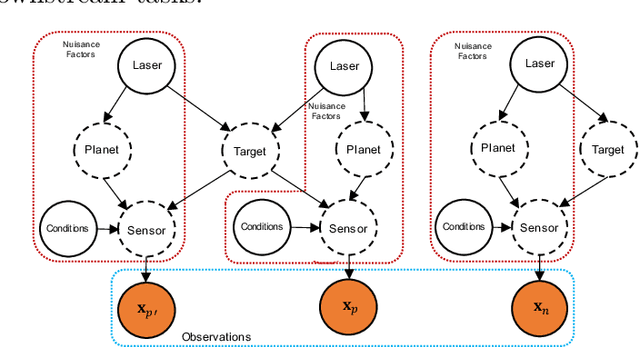

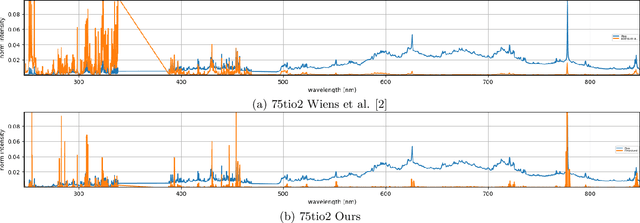
This work tests whether deep neural networks can clean laser induced breakdown spectroscopy (LIBS) signals by using only uncleaned raw measurements. Our view of this problem considers a disentanglement of the effects of the target of interest from those of the nuisance factors (with non-zero mean) by leveraging the vast amounts of redundancies in LIBS data and our proposed learning formulation. This later aims at promoting consistency between repeated measurement views of a target while simultaneously removing consistencies with all other LIBS measurements taken throughout the history of the instrument. Evaluations on real data from the ChemCam instrument onboard the Martian Curiosity rover show a superior performance in cleaning LIBS signals compared to the standard approaches being used by the ChemCam team.