 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Learning of Pushforwards For Domain Translation & Adaptation
Apr 18, 2023Given two probability densities on related data spaces, we seek a map pushing one density to the other while satisfying application-dependent constraints. For maps to have utility in a broad application space (including domain translation, domain adaptation, and generative modeling), the map must be available to apply on out-of-sample data points and should correspond to a probabilistic model over the two spaces. Unfortunately, existing approaches, which are primarily based on optimal transport, do not address these needs. In this paper, we introduce a novel pushforward map learning algorithm that utilizes normalizing flows to parameterize the map. We first re-formulate the classical optimal transport problem to be map-focused and propose a learning algorithm to select from all possible maps under the constraint that the map minimizes a probability distance and application-specific regularizers; thus, our method can be seen as solving a modified optimal transport problem. Once the map is learned, it can be used to map samples from a source domain to a target domain. In addition, because the map is parameterized as a composition of normalizing flows, it models the empirical distributions over the two data spaces and allows both sampling and likelihood evaluation for both data sets. We compare our method (parOT) to related optimal transport approaches in the context of domain adaptation and domain translation on benchmark data sets. Finally, to illustrate the impact of our work on applied problems, we apply parOT to a real scientific application: spectral calibration for high-dimensional measurements from two vastly different environments
Modeling Design and Control Problems Involving Neural Network Surrogates
Nov 20, 2021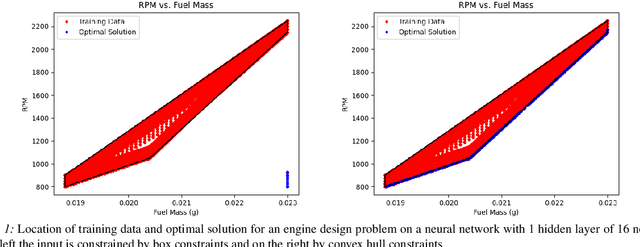


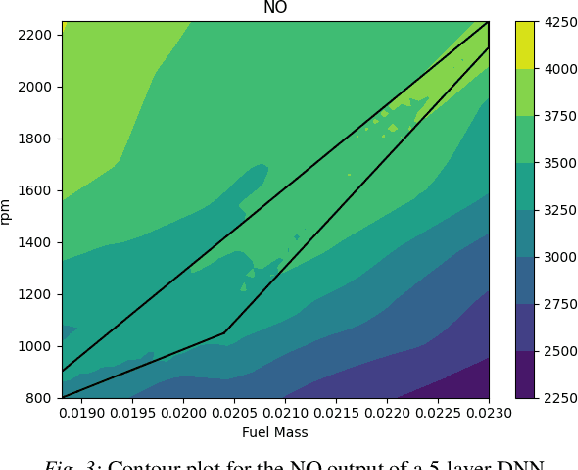
We consider nonlinear optimization problems that involve surrogate models represented by neural networks. We demonstrate first how to directly embed neural network evaluation into optimization models, highlight a difficulty with this approach that can prevent convergence, and then characterize stationarity of such models. We then present two alternative formulations of these problems in the specific case of feedforward neural networks with ReLU activation: as a mixed-integer optimization problem and as a mathematical program with complementarity constraints. For the latter formulation we prove that stationarity at a point for this problem corresponds to stationarity of the embedded formulation. Each of these formulations may be solved with state-of-the-art optimization methods, and we show how to obtain good initial feasible solutions for these methods. We compare our formulations on three practical applications arising in the design and control of combustion engines, in the generation of adversarial attacks on classifier networks, and in the determination of optimal flows in an oil well network.