 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Complex Scientific Table Data Extraction
Jul 02, 2025Table structure recognition (TSR) and optical character recognition (OCR) play crucial roles in extracting structured data from tables in scientific documents. However, existing extraction frameworks built on top of TSR and OCR methods often fail to quantify the uncertainties of extracted results. To obtain highly accurate data for scientific domains, all extracted data must be manually verified, which can be time-consuming and labor-intensive. We propose a framework that performs uncertainty-aware data extraction for complex scientific tables, built on conformal prediction, a model-agnostic method for uncertainty quantification (UQ). We explored various uncertainty scoring methods to aggregate the uncertainties introduced by TSR and OCR. We rigorously evaluated the framework using a standard benchmark and an in-house dataset consisting of complex scientific tables in six scientific domains. The results demonstrate the effectiveness of using UQ for extraction error detection, and by manually verifying only 47\% of extraction results, the data quality can be improved by 30\%. Our work quantitatively demonstrates the role of UQ with the potential of improving the efficiency in the human-machine cooperation process to obtain scientifically usable data from complex tables in scientific documents. All code and data are available on GitHub at https://github.com/lamps-lab/TSR-OCR-UQ/tree/main.
Uncertainty Quantification in Table Structure Recognition
Jul 01, 2024
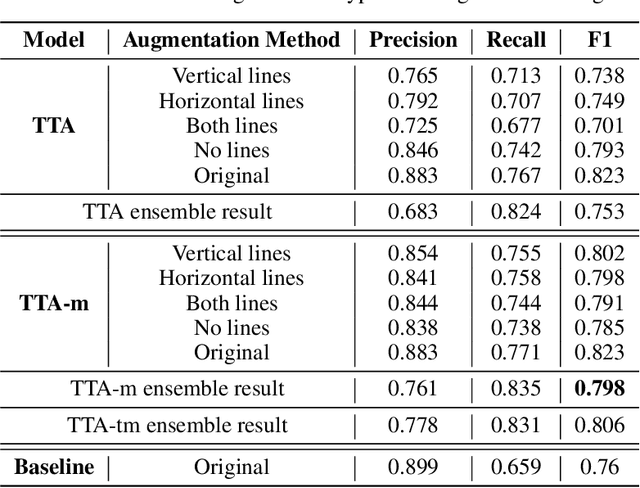


Quantifying uncertainties for machine learning models is a critical step to reduce human verification effort by detecting predictions with low confidence. This paper proposes a method for uncertainty quantification (UQ) of table structure recognition (TSR). The proposed UQ method is built upon a mixture-of-expert approach termed Test-Time Augmentation (TTA). Our key idea is to enrich and diversify the table representations, to spotlight the cells with high recognition uncertainties. To evaluate the effectiveness, we proposed two heuristics to differentiate highly uncertain cells from normal cells, namely, masking and cell complexity quantification. Masking involves varying the pixel intensity to deem the detection uncertainty. Cell complexity quantification gauges the uncertainty of each cell by its topological relation with neighboring cells. The evaluation results based on standard benchmark datasets demonstrate that the proposed method is effective in quantifying uncertainty in TSR models. To our best knowledge, this study is the first of its kind to enable UQ in TSR tasks. Our code and data are available at: https://github.com/lamps-lab/UQTTA.git.
DeepPatent2: A Large-Scale Benchmarking Corpus for Technical Drawing Understanding
Nov 07, 2023Recent advances in computer vision (CV) and natural language processing have been driven by exploiting big data on practical applications. However, these research fields are still limited by the sheer volume, versatility, and diversity of the available datasets. CV tasks, such as image captioning, which has primarily been carried out on natural images, still struggle to produce accurate and meaningful captions on sketched images often included in scientific and technical documents. The advancement of other tasks such as 3D reconstruction from 2D images requires larger datasets with multiple viewpoints. We introduce DeepPatent2, a large-scale dataset, providing more than 2.7 million technical drawings with 132,890 object names and 22,394 viewpoints extracted from 14 years of US design patent documents. We demonstrate the usefulness of DeepPatent2 with conceptual captioning. We further provide the potential usefulness of our dataset to facilitate other research areas such as 3D image reconstruction and image retrieval.
A Study on Reproducibility and Replicability of Table Structure Recognition Methods
Apr 20, 2023



Concerns about reproducibility in artificial intelligence (AI) have emerged, as researchers have reported unsuccessful attempts to directly reproduce published findings in the field. Replicability, the ability to affirm a finding using the same procedures on new data, has not been well studied. In this paper, we examine both reproducibility and replicability of a corpus of 16 papers on table structure recognition (TSR), an AI task aimed at identifying cell locations of tables in digital documents. We attempt to reproduce published results using codes and datasets provided by the original authors. We then examine replicability using a dataset similar to the original as well as a new dataset, GenTSR, consisting of 386 annotated tables extracted from scientific papers. Out of 16 papers studied, we reproduce results consistent with the original in only four. Two of the four papers are identified as replicable using the similar dataset under certain IoU values. No paper is identified as replicable using the new dataset. We offer observations on the causes of irreproducibility and irreplicability. All code and data are available on Codeocean at https://codeocean.com/capsule/6680116/tree.