 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Generalized Mixed-Effects Models
Apr 13, 2026Generalized linear mixed-effects models (GLMMs) are widely used to analyze grouped and hierarchical data. In a GLMM, each response is assumed to follow an exponential-family distribution where the natural parameter is given by a linear function of observed covariates and a latent group-specific random effect. Since exact marginalization over the random effects is typically intractable, model parameters are estimated by maximizing an approximate marginal likelihood. In this paper, we replace the linear function with neural networks. The result is a more flexible model, the neural generalized mixed-effects model (NGMM), which captures complex relationships between covariates and responses. To fit NGMM to data, we introduce an efficient optimization procedure that maximizes the approximate marginal likelihood and is differentiable with respect to network parameters. We show that the approximation error of our objective decays at a Gaussian-tail rate in a user-chosen parameter. On synthetic data, NGMM improves over GLMMs when covariate-response relationships are nonlinear, and on real-world datasets it outperforms prior methods. Finally, we analyze a large dataset of student proficiency to demonstrate how NGMM can be extended to more complex latent-variable models.
Posterior Mean Matching: Generative Modeling through Online Bayesian Inference
Dec 17, 2024This paper introduces posterior mean matching (PMM), a new method for generative modeling that is grounded in Bayesian inference. PMM uses conjugate pairs of distributions to model complex data of various modalities like images and text, offering a flexible alternative to existing methods like diffusion models. PMM models iteratively refine noisy approximations of the target distribution using updates from online Bayesian inference. PMM is flexible because its mechanics are based on general Bayesian models. We demonstrate this flexibility by developing specialized examples: a generative PMM model of real-valued data using the Normal-Normal model, a generative PMM model of count data using a Gamma-Poisson model, and a generative PMM model of discrete data using a Dirichlet-Categorical model. For the Normal-Normal PMM model, we establish a direct connection to diffusion models by showing that its continuous-time formulation converges to a stochastic differential equation (SDE). Additionally, for the Gamma-Poisson PMM, we derive a novel SDE driven by a Cox process, which is a significant departure from traditional Brownian motion-based generative models. PMMs achieve performance that is competitive with generative models for language modeling and image generation.
Counterfactual Explanations for Support Vector Machine Models
Dec 14, 2022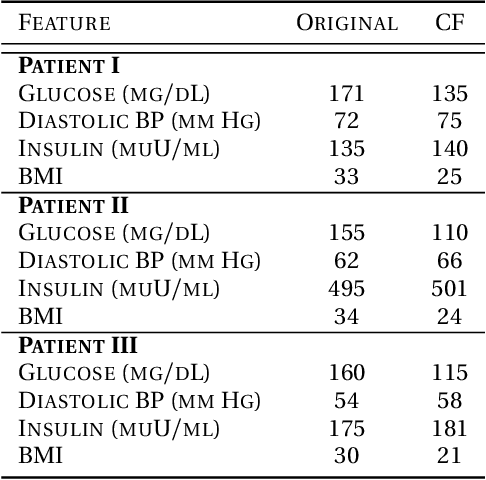
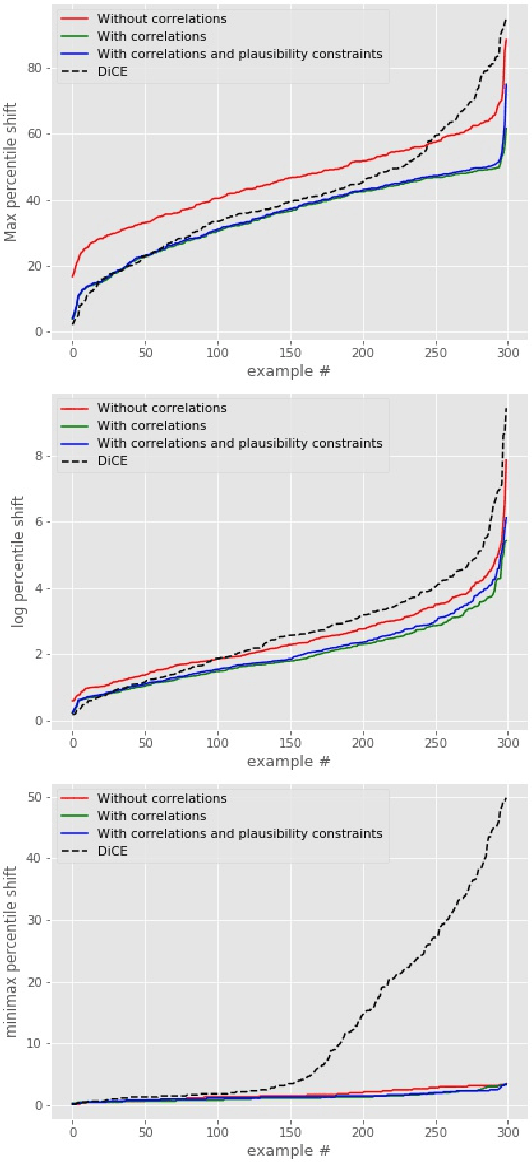
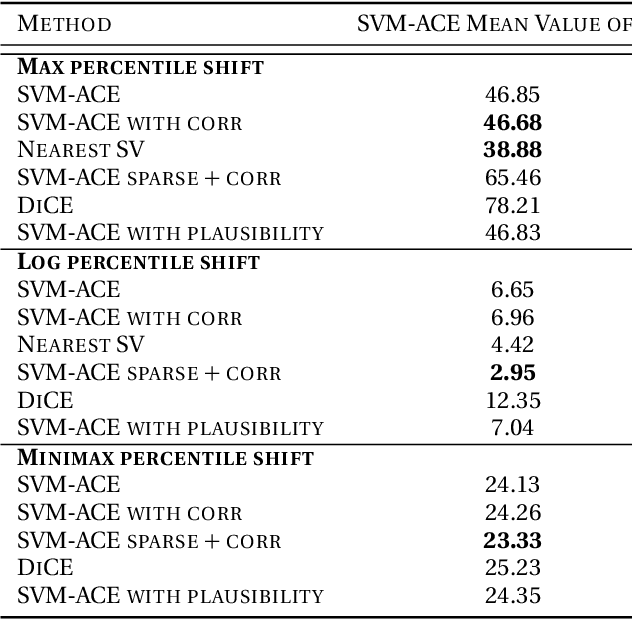
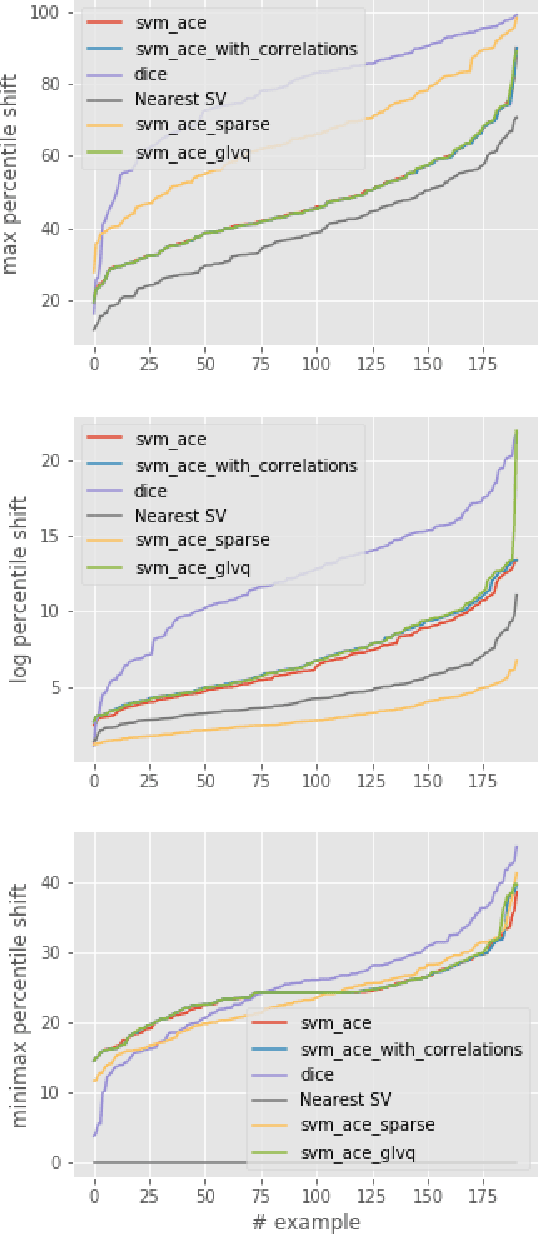
We tackle the problem of computing counterfactual explanations -- minimal changes to the features that flip an undesirable model prediction. We propose a solution to this question for linear Support Vector Machine (SVMs) models. Moreover, we introduce a way to account for weighted actions that allow for more changes in certain features than others. In particular, we show how to find counterfactual explanations with the purpose of increasing model interpretability. These explanations are valid, change only actionable features, are close to the data distribution, sparse, and take into account correlations between features. We cast this as a mixed integer programming optimization problem. Additionally, we introduce two novel scale-invariant cost functions for assessing the quality of counterfactual explanations and use them to evaluate the quality of our approach with a real medical dataset. Finally, we build a support vector machine model to predict whether law students will pass the Bar exam using protected features, and used our algorithms to uncover the inherent biases of the SVM.