 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Robustness to Spurious Correlations in Post-Training Language Models
May 09, 2025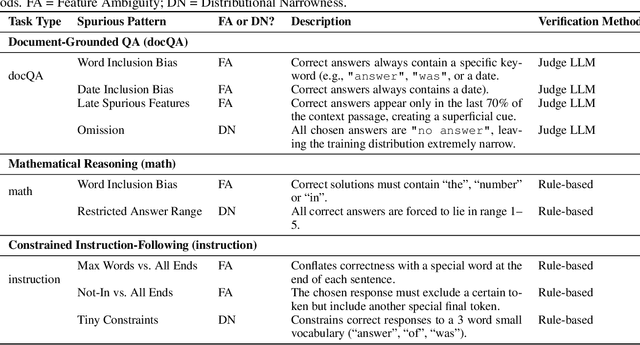
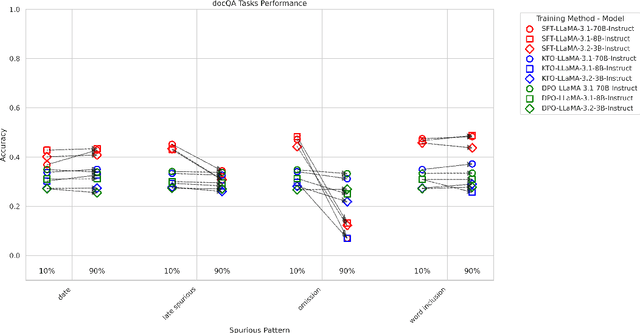
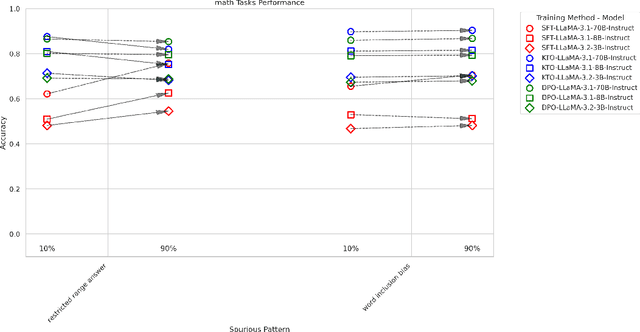
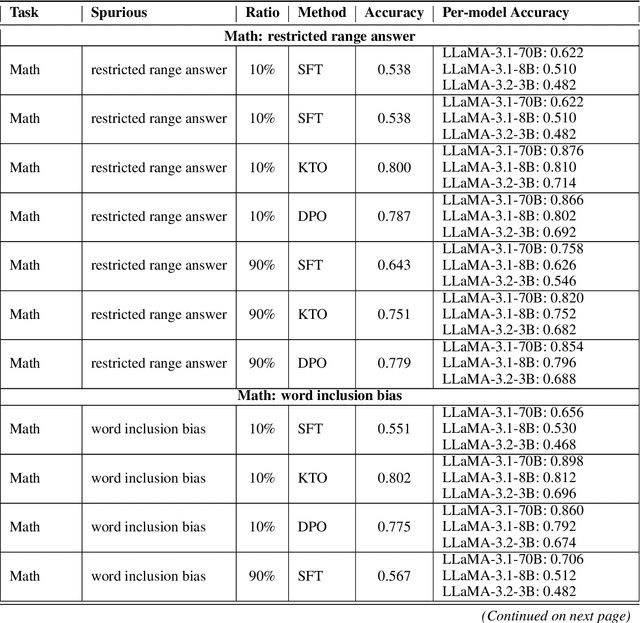
Supervised and preference-based fine-tuning techniques have become popular for aligning large language models (LLMs) with user intent and correctness criteria. However, real-world training data often exhibits spurious correlations -- arising from biases, dataset artifacts, or other "shortcut" features -- that can compromise a model's performance or generalization. In this paper, we systematically evaluate three post-training algorithms -- Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and KTO (Kahneman-Tversky Optimization) -- across a diverse set of synthetic tasks and spuriousness conditions. Our tasks span mathematical reasoning, constrained instruction-following, and document-grounded question answering. We vary the degree of spurious correlation (10% vs. 90%) and investigate two forms of artifacts: "Feature Ambiguity" and "Distributional Narrowness." Our results show that the models often but not always degrade under higher spuriousness. The preference-based methods (DPO/KTO) can demonstrate relative robustness in mathematical reasoning tasks. By contrast, SFT maintains stronger performance in complex, context-intensive tasks. These findings highlight that no single post-training strategy universally outperforms in all scenarios; the best choice depends on the type of target task and the nature of spurious correlations.
Counterfactual Explanations for Support Vector Machine Models
Dec 14, 2022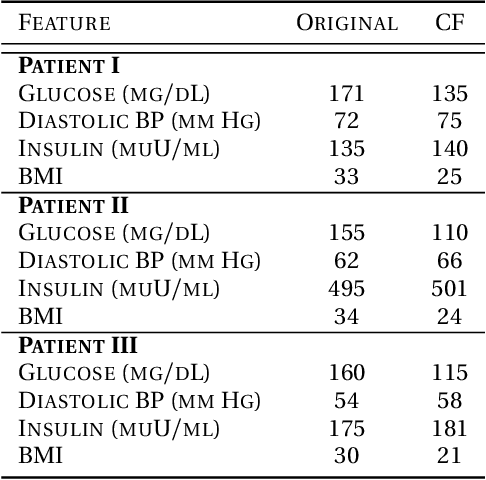
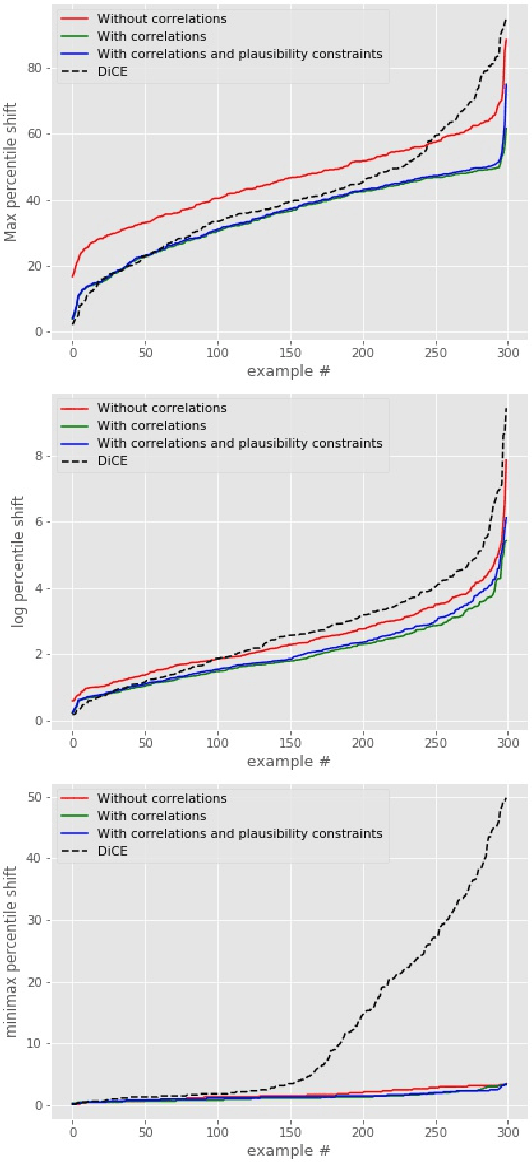
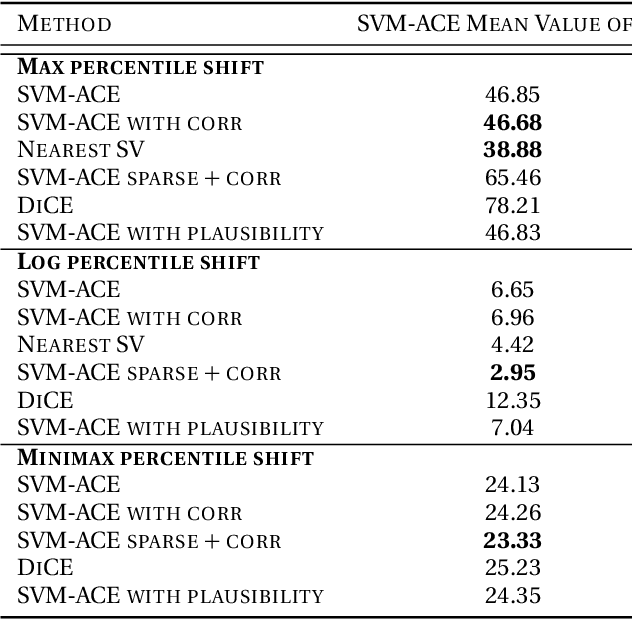
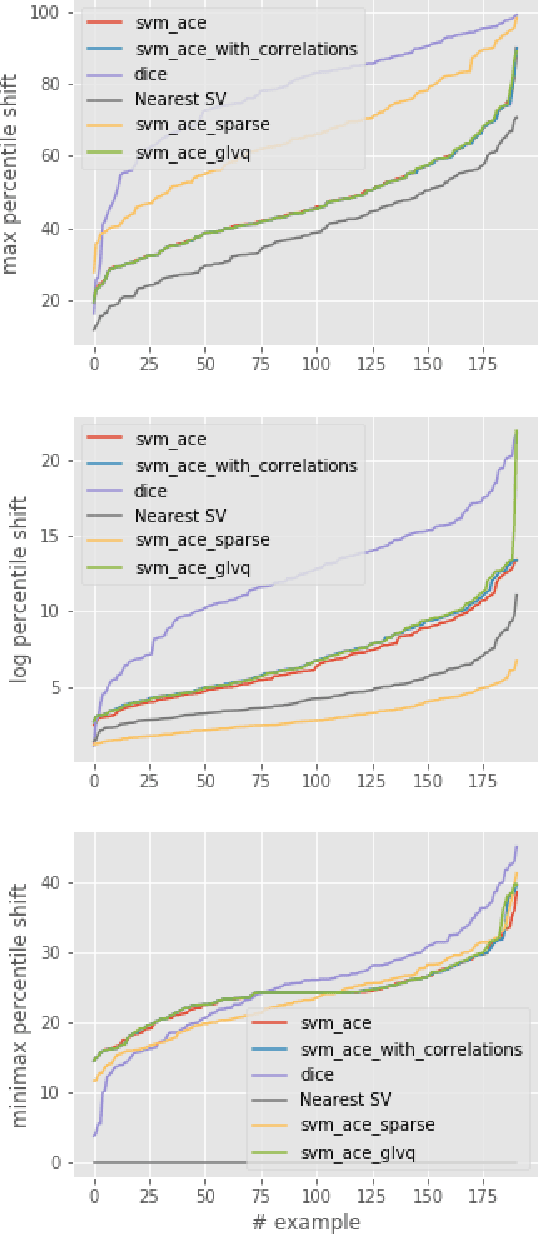
We tackle the problem of computing counterfactual explanations -- minimal changes to the features that flip an undesirable model prediction. We propose a solution to this question for linear Support Vector Machine (SVMs) models. Moreover, we introduce a way to account for weighted actions that allow for more changes in certain features than others. In particular, we show how to find counterfactual explanations with the purpose of increasing model interpretability. These explanations are valid, change only actionable features, are close to the data distribution, sparse, and take into account correlations between features. We cast this as a mixed integer programming optimization problem. Additionally, we introduce two novel scale-invariant cost functions for assessing the quality of counterfactual explanations and use them to evaluate the quality of our approach with a real medical dataset. Finally, we build a support vector machine model to predict whether law students will pass the Bar exam using protected features, and used our algorithms to uncover the inherent biases of the SVM.
Direct Inversion: Optimization-Free Text-Driven Real Image Editing with Diffusion Models
Nov 15, 2022

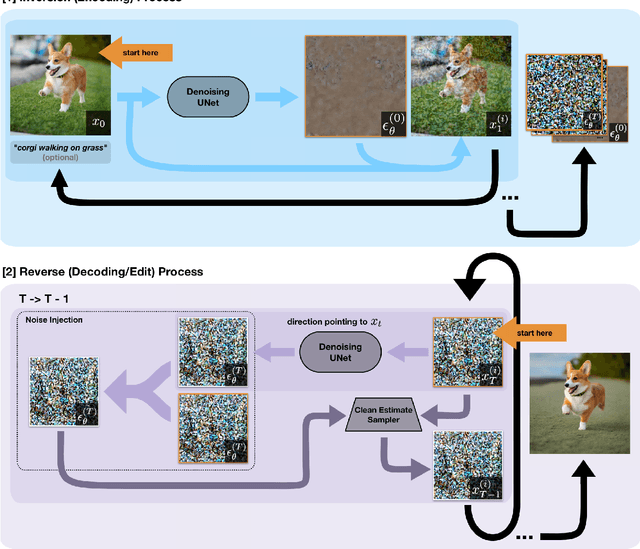
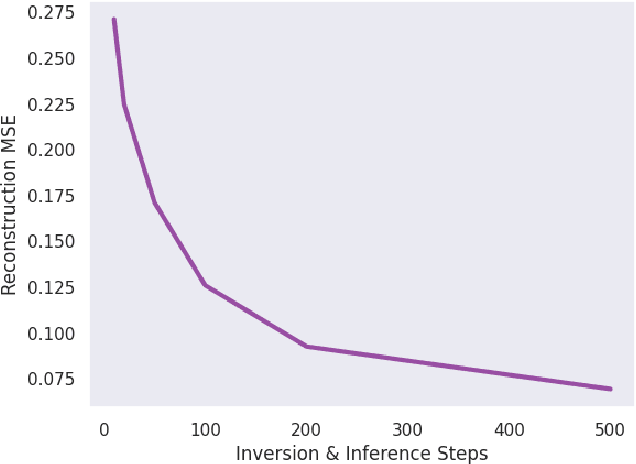
With the rise of large, publicly-available text-to-image diffusion models, text-guided real image editing has garnered much research attention recently. Existing methods tend to either rely on some form of per-instance or per-task fine-tuning and optimization, require multiple novel views, or they inherently entangle preservation of real image identity, semantic coherence, and faithfulness to text guidance. In this paper, we propose an optimization-free and zero fine-tuning framework that applies complex and non-rigid edits to a single real image via a text prompt, avoiding all the pitfalls described above. Using widely-available generic pre-trained text-to-image diffusion models, we demonstrate the ability to modulate pose, scene, background, style, color, and even racial identity in an extremely flexible manner through a single target text detailing the desired edit. Furthermore, our method, which we name $\textit{Direct Inversion}$, proposes multiple intuitively configurable hyperparameters to allow for a wide range of types and extents of real image edits. We prove our method's efficacy in producing high-quality, diverse, semantically coherent, and faithful real image edits through applying it on a variety of inputs for a multitude of tasks. We also formalize our method in well-established theory, detail future experiments for further improvement, and compare against state-of-the-art attempts.