 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness to Model Inversion Attacks via Sparse Coding Architectures
Mar 21, 2024Recent model inversion attack algorithms permit adversaries to reconstruct a neural network's private training data just by repeatedly querying the network and inspecting its outputs. In this work, we develop a novel network architecture that leverages sparse-coding layers to obtain superior robustness to this class of attacks. Three decades of computer science research has studied sparse coding in the context of image denoising, object recognition, and adversarial misclassification settings, but to the best of our knowledge, its connection to state-of-the-art privacy vulnerabilities remains unstudied. However, sparse coding architectures suggest an advantageous means to defend against model inversion attacks because they allow us to control the amount of irrelevant private information encoded in a network's intermediate representations in a manner that can be computed efficiently during training and that is known to have little effect on classification accuracy. Specifically, compared to networks trained with a variety of state-of-the-art defenses, our sparse-coding architectures maintain comparable or higher classification accuracy while degrading state-of-the-art training data reconstructions by factors of 1.1 to 18.3 across a variety of reconstruction quality metrics (PSNR, SSIM, FID). This performance advantage holds across 5 datasets ranging from CelebA faces to medical images and CIFAR-10, and across various state-of-the-art SGD-based and GAN-based inversion attacks, including Plug-&-Play attacks. We provide a cluster-ready PyTorch codebase to promote research and standardize defense evaluations.
How Robust Are Energy-Based Models Trained With Equilibrium Propagation?
Jan 21, 2024Deep neural networks (DNNs) are easily fooled by adversarial perturbations that are imperceptible to humans. Adversarial training, a process where adversarial examples are added to the training set, is the current state-of-the-art defense against adversarial attacks, but it lowers the model's accuracy on clean inputs, is computationally expensive, and offers less robustness to natural noise. In contrast, energy-based models (EBMs), which were designed for efficient implementation in neuromorphic hardware and physical systems, incorporate feedback connections from each layer to the previous layer, yielding a recurrent, deep-attractor architecture which we hypothesize should make them naturally robust. Our work is the first to explore the robustness of EBMs to both natural corruptions and adversarial attacks, which we do using the CIFAR-10 and CIFAR-100 datasets. We demonstrate that EBMs are more robust than transformers and display comparable robustness to adversarially-trained DNNs on gradient-based (white-box) attacks, query-based (black-box) attacks, and natural perturbations without sacrificing clean accuracy, and without the need for adversarial training or additional training techniques.
A Systematic Comparison of Deep Learning Architectures in an Autonomous Vehicle
Oct 13, 2018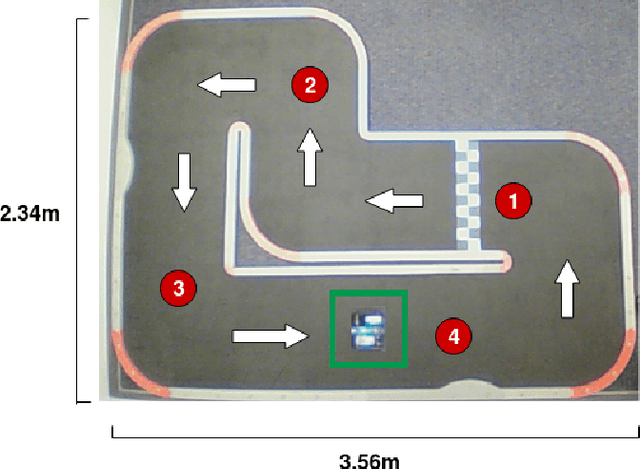
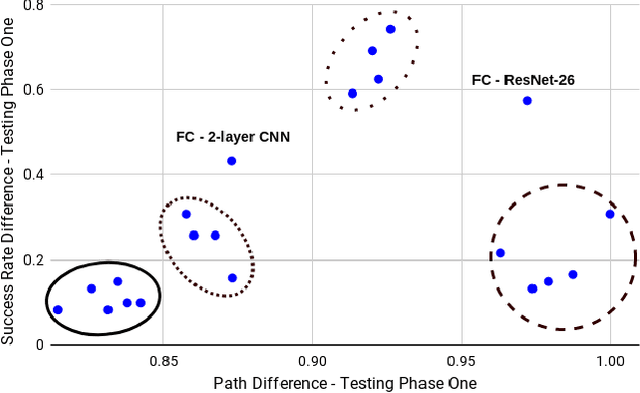

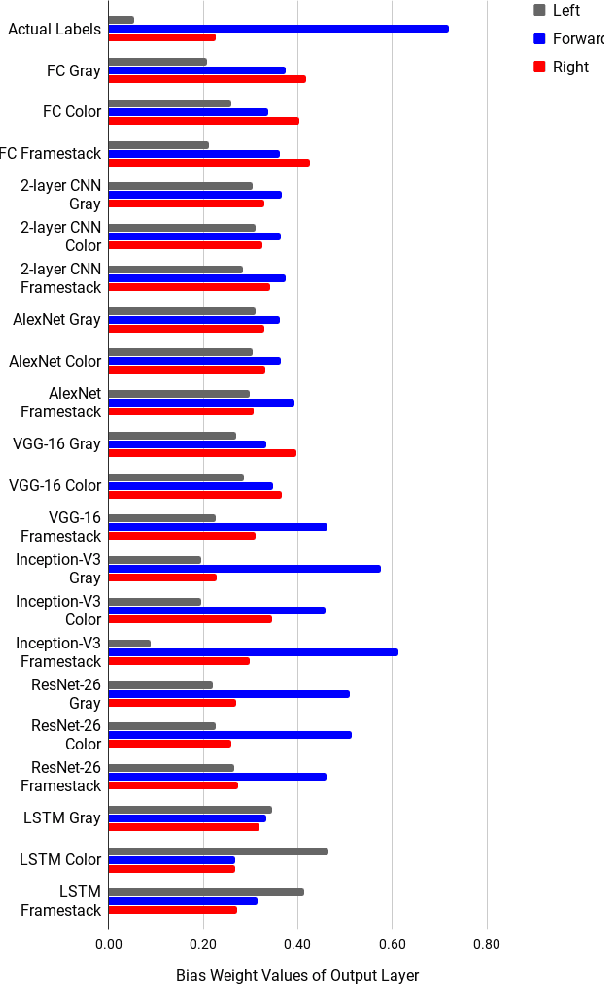
Self-driving technology is advancing rapidly --- albeit with significant challenges and limitations. This progress is largely due to recent developments in deep learning algorithms. To date, however, there has been no systematic comparison of how different deep learning architectures perform at such tasks, or an attempt to determine a correlation between classification performance and performance in an actual vehicle, a potentially critical factor in developing self-driving systems. Here, we introduce the first controlled comparison of multiple deep-learning architectures in an end-to-end autonomous driving task across multiple testing conditions. We compared performance, under identical driving conditions, across seven architectures including a fully-connected network, a simple 2 layer CNN, AlexNet, VGG-16, Inception-V3, ResNet, and an LSTM by assessing the number of laps each model was able to successfully complete without crashing while traversing an indoor racetrack. We compared performance across models when the conditions exactly matched those in training as well as when the local environment and track were configured differently and objects that were not included in the training dataset were placed on the track in various positions. In addition, we considered performance using several different data types for training and testing including single grayscale and color frames, and multiple grayscale frames stacked together in sequence. With the exception of a fully-connected network, all models performed reasonably well (around or above 80\%) and most very well (~95\%) on at least one input type but with considerable variation across models and inputs. Overall, AlexNet, operating on single color frames as input, achieved the best level of performance (100\% success rate in phase one and 55\% in phase two) while VGG-16 performed well most consistently across image types.