 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Comparison of Deep Learning Architectures in an Autonomous Vehicle
Oct 13, 2018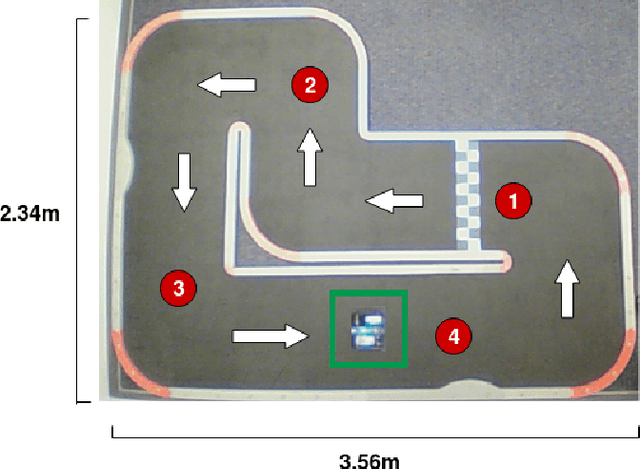
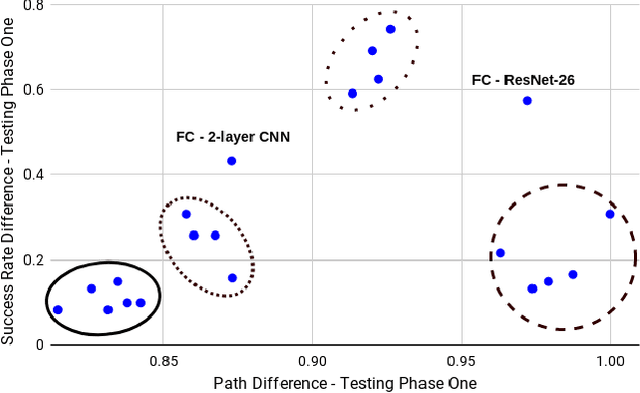

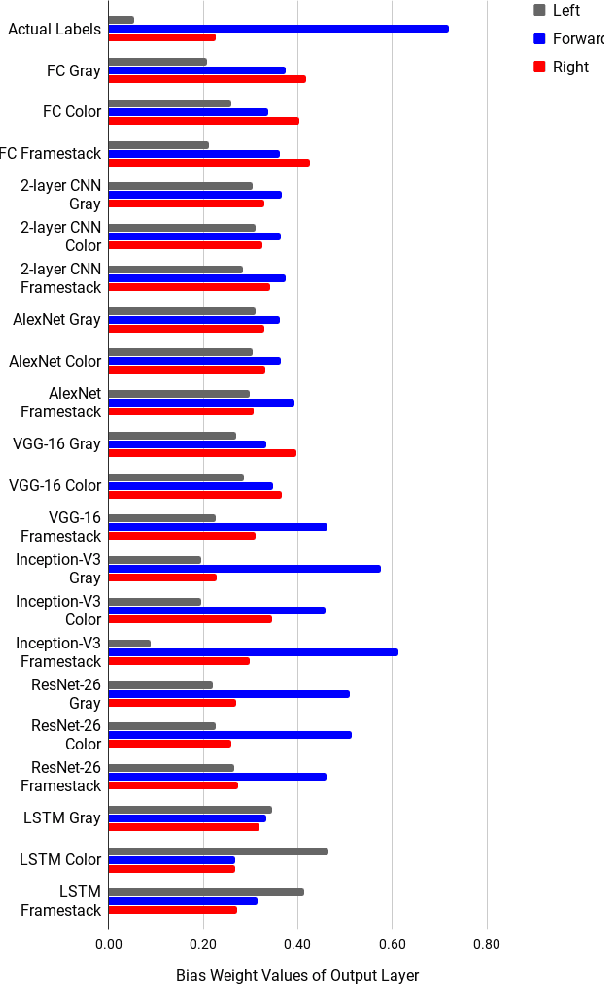
Self-driving technology is advancing rapidly --- albeit with significant challenges and limitations. This progress is largely due to recent developments in deep learning algorithms. To date, however, there has been no systematic comparison of how different deep learning architectures perform at such tasks, or an attempt to determine a correlation between classification performance and performance in an actual vehicle, a potentially critical factor in developing self-driving systems. Here, we introduce the first controlled comparison of multiple deep-learning architectures in an end-to-end autonomous driving task across multiple testing conditions. We compared performance, under identical driving conditions, across seven architectures including a fully-connected network, a simple 2 layer CNN, AlexNet, VGG-16, Inception-V3, ResNet, and an LSTM by assessing the number of laps each model was able to successfully complete without crashing while traversing an indoor racetrack. We compared performance across models when the conditions exactly matched those in training as well as when the local environment and track were configured differently and objects that were not included in the training dataset were placed on the track in various positions. In addition, we considered performance using several different data types for training and testing including single grayscale and color frames, and multiple grayscale frames stacked together in sequence. With the exception of a fully-connected network, all models performed reasonably well (around or above 80\%) and most very well (~95\%) on at least one input type but with considerable variation across models and inputs. Overall, AlexNet, operating on single color frames as input, achieved the best level of performance (100\% success rate in phase one and 55\% in phase two) while VGG-16 performed well most consistently across image types.