 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Way Matching of Datasets with Low Rank Signals
Apr 29, 2022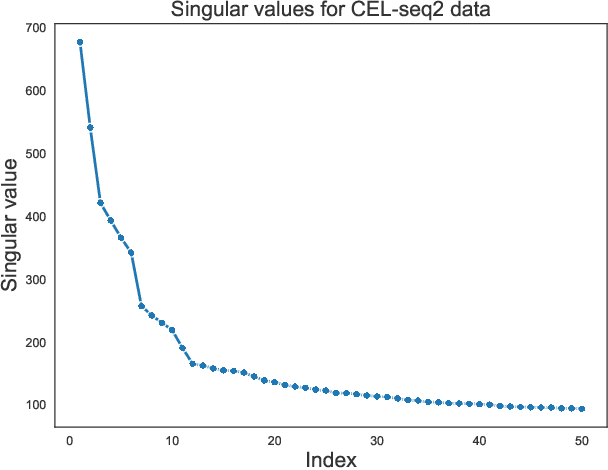
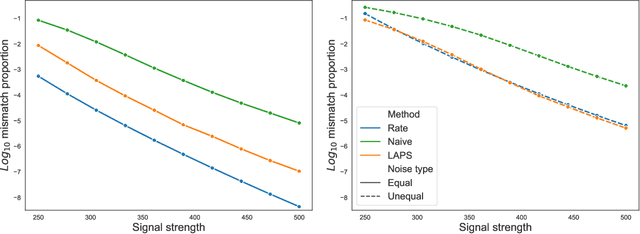

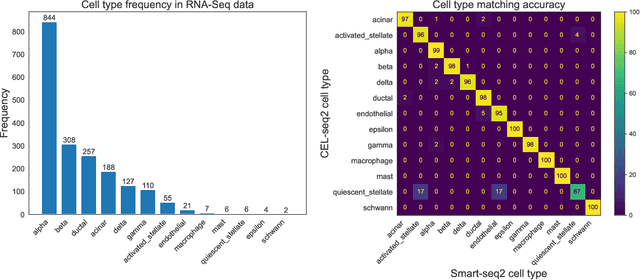
We study one-way matching of a pair of datasets with low rank signals. Under a stylized model, we first derive information-theoretic limits of matching. We then show that linear assignment with projected data achieves fast rates of convergence and sometimes even minimax rate optimality for this task. The theoretical error bounds are corroborated by simulated examples. Furthermore, we illustrate practical use of the matching procedure on two single-cell data examples.
Perception-aware receding horizon trajectory planning for multicopters with visual-inertial odometry
Apr 07, 2022
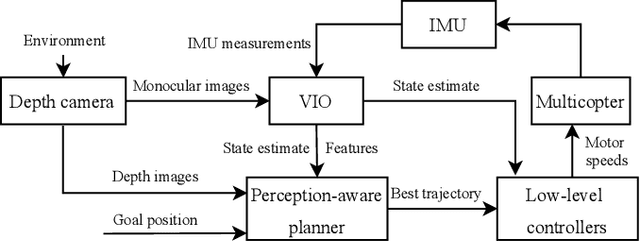
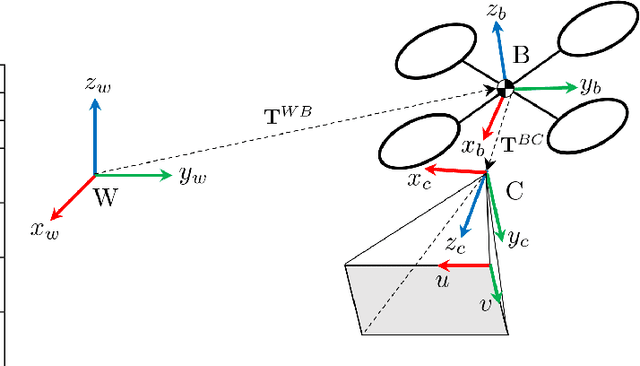
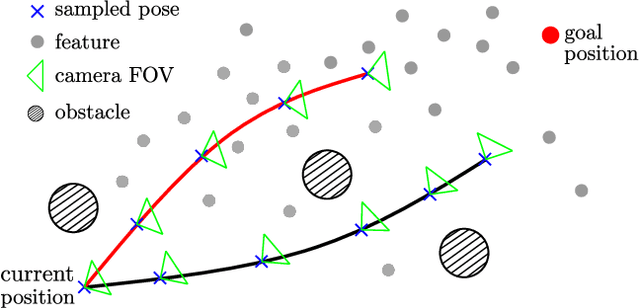
Visual inertial odometry (VIO) is widely used for the state estimation of multicopters, but it may function poorly in environments with few visual features or in overly aggressive flights. In this work, we propose a perception-aware collision avoidance local planner for multicopters. Our approach is able to fly the vehicle to a goal position at high speed, avoiding obstacles in the environment while achieving good VIO state estimation accuracy. The proposed planner samples a group of minimum jerk trajectories and finds collision-free trajectories among them, which are then evaluated based on their speed to the goal and perception quality. Both the features' motion blur and their locations are considered for the perception quality. The best trajectory from the evaluation is tracked by the vehicle and is updated in a receding horizon manner when new images are received from the camera. All the sampled trajectories have zero speed and acceleration at the end, and the planner assumes no other visual features except those already found by the VIO. As a result, the vehicle will follow the current trajectory to the end and stop safely if no new trajectories are found, avoiding collision or flying into areas without features. The proposed method can run in real time on a small embedded computer on board. We validated the effectiveness of our proposed approach through experiments in indoor and outdoor environments. Compared to a perception-agnostic planner, the proposed planner kept more features in the camera's view and made the flight less aggressive, making the VIO more accurate. It also reduced VIO failures, which occurred for the perception-agnostic planner but not for the proposed planner. The experiment video can be found at https://youtu.be/LjZju4KEH9Q.
Learning Torque Control for Quadrupedal Locomotion
Mar 10, 2022



Reinforcement learning (RL) is a promising tool for developing controllers for quadrupedal locomotion. The design of most learning-based locomotion controllers adopts the joint position-based paradigm, wherein a low-frequency RL policy outputs target joint positions that are then tracked by a high-frequency proportional-derivative (PD) controller that outputs joint torques. However, the low frequency of such a policy hinders the advancement of highly dynamic locomotion behaviors. Moreover, determining the PD gains for optimal tracking performance is laborious and dependent on the task at hand. In this paper, we introduce a learning torque control framework for quadrupedal locomotion, which trains an RL policy that directly predicts joint torques at a high frequency, thus circumventing the use of PD controllers. We validate the proposed framework with extensive experiments where the robot is able to both traverse various terrains and resist external pushes, given user-specified commands. To our knowledge, this is the first attempt of learning torque control for quadrupedal locomotion with an end-to-end single neural network that has led to successful real-world experiments among recent research on learning-based quadrupedal locomotion which is mostly position-based.
Vision-aided Dynamic Quadrupedal Locomotion on Discrete Terrain using Motion Libraries
Oct 02, 2021



In this paper, we present a framework rooted in control and planning that enables quadrupedal robots to traverse challenging terrains with discrete footholds using visual feedback. Navigating discrete terrain is challenging for quadrupeds because the motion of the robot can be aperiodic, highly dynamic, and blind for the hind legs of the robot. Additionally, the robot needs to reason over both the feasible footholds as well as robot velocity by speeding up and slowing down at different parts of the terrain. We build an offline library of periodic gaits which span two trotting steps on the robot, and switch between different motion primitives to achieve aperiodic motions of different step lengths on an A1 robot. The motion library is used to provide targets to a geometric model predictive controller which controls stance. To incorporate visual feedback, we use terrain mapping tools to build a local height map of the terrain around the robot using RGB and depth cameras, and extract feasible foothold locations around both the front and hind legs of the robot. Our experiments show a Unitree A1 robot navigating multiple unknown, challenging and discrete terrains in the real world.
Vision-Aided Autonomous Navigation of Bipedal Robots in Height-Constrained Environments
Sep 13, 2021
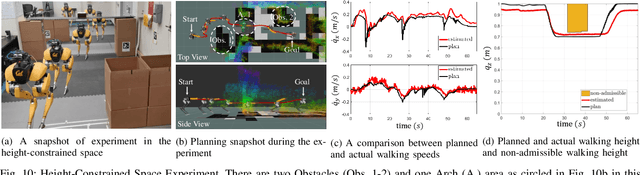
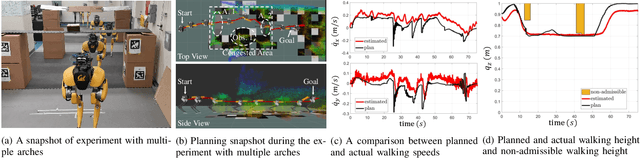
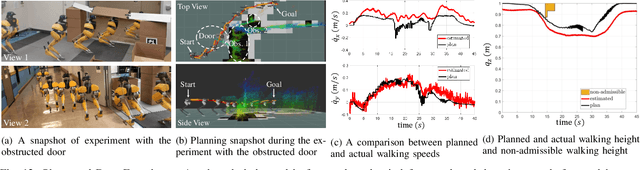
Navigating a large-scaled robot in unknown and cluttered height-constrained environments is challenging. Not only is a fast and reliable planning algorithm required to go around obstacles, the robot should also be able to change its intrinsic dimension by crouching in order to travel underneath height constrained regions. There are few mobile robots that are capable of handling such a challenge, and bipedal robots provide a solution. However, as bipedal robots have nonlinear and hybrid dynamics, trajectory planning while ensuring dynamic feasibility and safety on these robots is challenging. This paper presents an end-to-end vision-aided autonomous navigation framework which leverages three layers of planners and a variable walking height controller to enable bipedal robots to safely explore height-constrained environments. A vertically actuated Spring-Loaded Inverted Pendulum (vSLIP) model is introduced to capture the robot coupled dynamics of planar walking and vertical walking height. This reduced-order model is utilized to optimize for long-term and short-term safe trajectory plans. A variable walking height controller is leveraged to enable the bipedal robot to maintain stable periodic walking gaits while following the planned trajectory. The entire framework is tested and experimentally validated using a bipedal robot Cassie. This demonstrates reliable autonomy to drive the robot to safely avoid obstacles while walking to the goal location in various kinds of height-constrained cluttered environments.
Real-time Geo-localization Using Satellite Imagery and Topography for Unmanned Aerial Vehicles
Aug 07, 2021



The capabilities of autonomous flight with unmanned aerial vehicles (UAVs) have significantly increased in recent times. However, basic problems such as fast and robust geo-localization in GPS-denied environments still remain unsolved. Existing research has primarily concentrated on improving the accuracy of localization at the cost of long and varying computation time in various situations, which often necessitates the use of powerful ground station machines. In order to make image-based geo-localization online and pragmatic for lightweight embedded systems on UAVs, we propose a framework that is reliable in changing scenes, flexible about computing resource allocation and adaptable to common camera placements. The framework is comprised of two stages: offline database preparation and online inference. At the first stage, color images and depth maps are rendered as seen from potential vehicle poses quantized over the satellite and topography maps of anticipated flying areas. A database is then populated with the global and local descriptors of the rendered images. At the second stage, for each captured real-world query image, top global matches are retrieved from the database and the vehicle pose is further refined via local descriptor matching. We present field experiments of image-based localization on two different UAV platforms to validate our results.
Weighted Training for Cross-Task Learning
May 28, 2021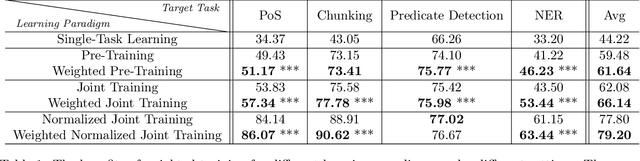


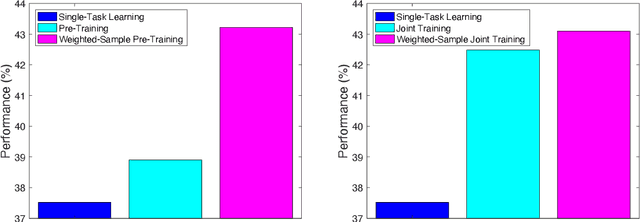
In this paper, we introduce Target-Aware Weighted Training (TAWT), a weighted training algorithm for cross-task learning based on minimizing a representation-based task distance between the source and target tasks. We show that TAWT is easy to implement, is computationally efficient, requires little hyperparameter tuning, and enjoys non-asymptotic learning-theoretic guarantees. The effectiveness of TAWT is corroborated through extensive experiments with BERT on four sequence tagging tasks in natural language processing (NLP), including part-of-speech (PoS) tagging, chunking, predicate detection, and named entity recognition (NER). As a byproduct, the proposed representation-based task distance allows one to reason in a theoretically principled way about several critical aspects of cross-task learning, such as the choice of the source data and the impact of fine-tuning
Estimating and Improving Dynamic Treatment Regimes With a Time-Varying Instrumental Variable
Apr 15, 2021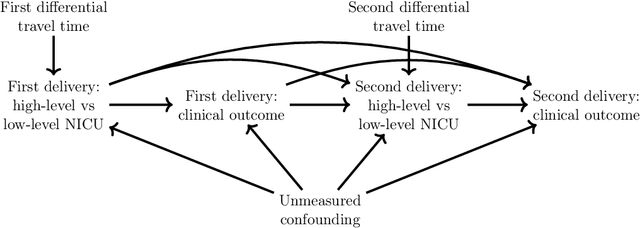



Estimating dynamic treatment regimes (DTRs) from retrospective observational data is challenging as some degree of unmeasured confounding is often expected. In this work, we develop a framework of estimating properly defined "optimal" DTRs with a time-varying instrumental variable (IV) when unmeasured covariates confound the treatment and outcome, rendering the potential outcome distributions only partially identified. We derive a novel Bellman equation under partial identification, use it to define a generic class of estimands (termed IV-optimal DTRs), and study the associated estimation problem. We then extend the IV-optimality framework to tackle the policy improvement problem, delivering IV-improved DTRs that are guaranteed to perform no worse and potentially better than a pre-specified baseline DTR. Importantly, our IV-improvement framework opens up the possibility of strictly improving upon DTRs that are optimal under the no unmeasured confounding assumption (NUCA). We demonstrate via extensive simulations the superior performance of IV-optimal and IV-improved DTRs over the DTRs that are optimal only under the NUCA. In a real data example, we embed retrospective observational registry data into a natural, two-stage experiment with noncompliance using a time-varying IV and estimate useful IV-optimal DTRs that assign mothers to high-level or low-level neonatal intensive care units based on their prognostic variables.
A Theorem of the Alternative for Personalized Federated Learning
Mar 02, 2021A widely recognized difficulty in federated learning arises from the statistical heterogeneity among clients: local datasets often come from different but not entirely unrelated distributions, and personalization is, therefore, necessary to achieve optimal results from each individual's perspective. In this paper, we show how the excess risks of personalized federated learning with a smooth, strongly convex loss depend on data heterogeneity from a minimax point of view. Our analysis reveals a surprising theorem of the alternative for personalized federated learning: there exists a threshold such that (a) if a certain measure of data heterogeneity is below this threshold, the FedAvg algorithm [McMahan et al., 2017] is minimax optimal; (b) when the measure of heterogeneity is above this threshold, then doing pure local training (i.e., clients solve empirical risk minimization problems on their local datasets without any communication) is minimax optimal. As an implication, our results show that the presumably difficult (infinite-dimensional) problem of adapting to client-wise heterogeneity can be reduced to a simple binary decision problem of choosing between the two baseline algorithms. Our analysis relies on a new notion of algorithmic stability that takes into account the nature of federated learning.
Federated $f$-Differential Privacy
Feb 22, 2021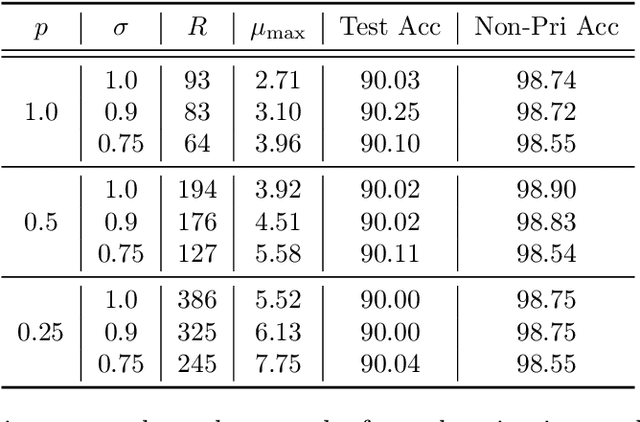
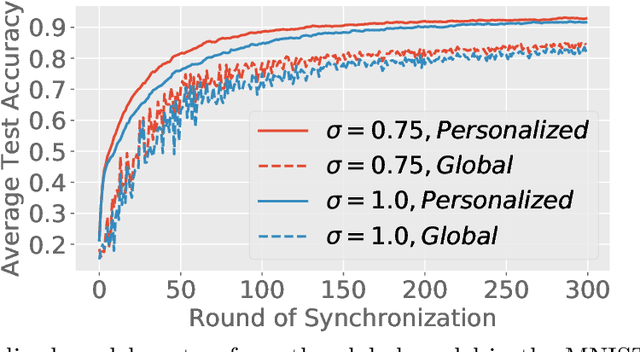
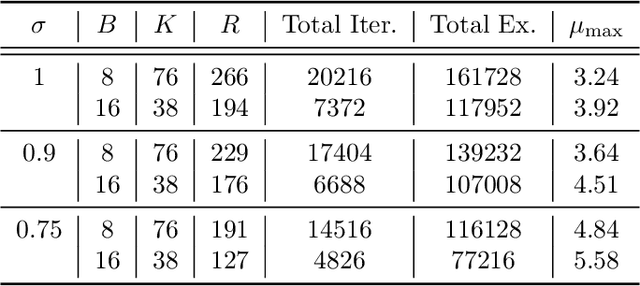
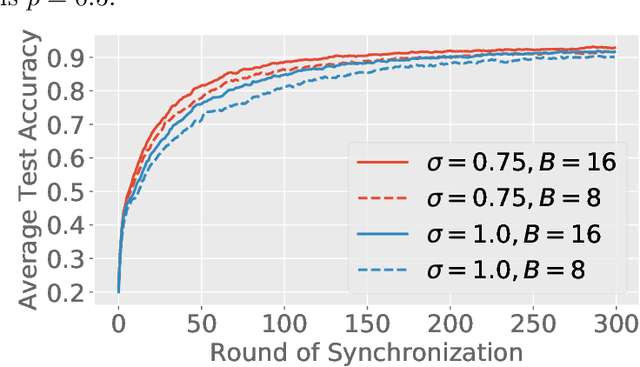
Federated learning (FL) is a training paradigm where the clients collaboratively learn models by repeatedly sharing information without compromising much on the privacy of their local sensitive data. In this paper, we introduce federated $f$-differential privacy, a new notion specifically tailored to the federated setting, based on the framework of Gaussian differential privacy. Federated $f$-differential privacy operates on record level: it provides the privacy guarantee on each individual record of one client's data against adversaries. We then propose a generic private federated learning framework {PriFedSync} that accommodates a large family of state-of-the-art FL algorithms, which provably achieves federated $f$-differential privacy. Finally, we empirically demonstrate the trade-off between privacy guarantee and prediction performance for models trained by {PriFedSync} in computer vision tasks.