 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Training for Cross-Task Learning
May 28, 2021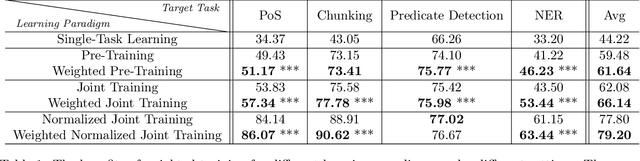


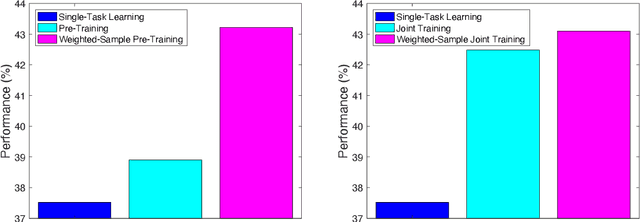
In this paper, we introduce Target-Aware Weighted Training (TAWT), a weighted training algorithm for cross-task learning based on minimizing a representation-based task distance between the source and target tasks. We show that TAWT is easy to implement, is computationally efficient, requires little hyperparameter tuning, and enjoys non-asymptotic learning-theoretic guarantees. The effectiveness of TAWT is corroborated through extensive experiments with BERT on four sequence tagging tasks in natural language processing (NLP), including part-of-speech (PoS) tagging, chunking, predicate detection, and named entity recognition (NER). As a byproduct, the proposed representation-based task distance allows one to reason in a theoretically principled way about several critical aspects of cross-task learning, such as the choice of the source data and the impact of fine-tuning
Variance Estimation For Online Regression via Spectrum Thresholding
Jun 13, 2019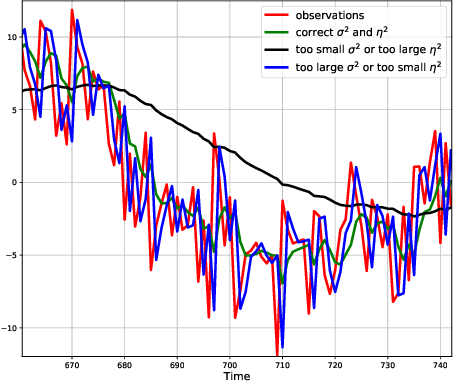
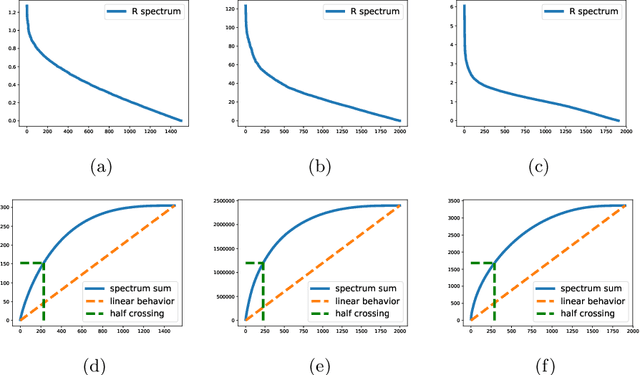
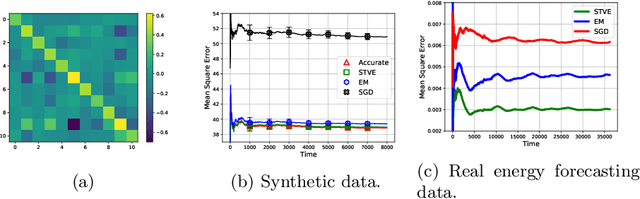
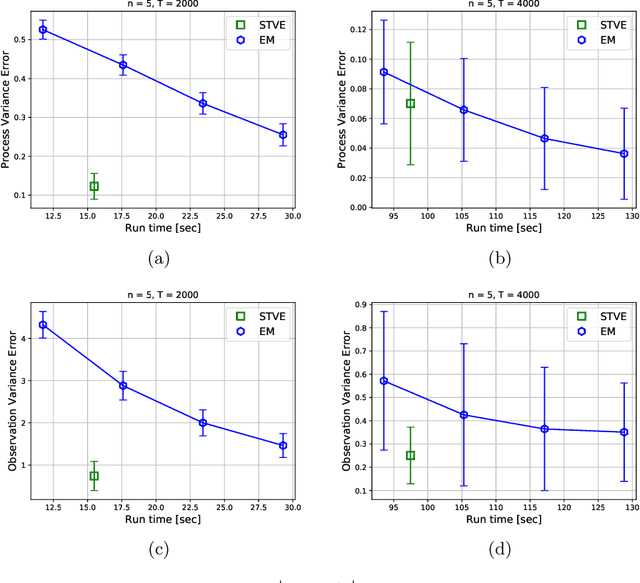
We consider the online linear regression problem, where the predictor vector may vary with time. This problem can be modelled as a linear dynamical system, where the parameters that need to be learned are the variance of both the process noise and the observation noise. The classical approach to learning the variance is via the maximum likelihood estimator -- a non-convex optimization problem prone to local minima and with no finite sample complexity bounds. In this paper we study the global system operator: the operator that maps the noises vectors to the output. In particular, we obtain estimates on its spectrum, and as a result derive the first known variance estimators with sample complexity guarantees for online regression problems. We demonstrate the approach on a number of synthetic and real-world benchmarks.
Multi Instance Learning For Unbalanced Data
Dec 17, 2018
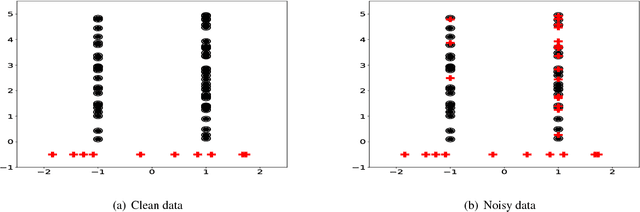
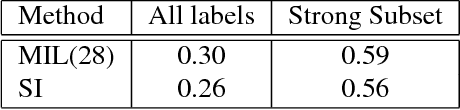
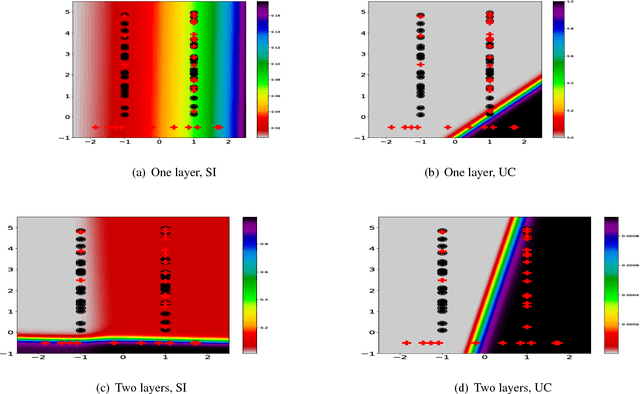
In the context of Multi Instance Learning, we analyze the Single Instance (SI) learning objective. We show that when the data is unbalanced and the family of classifiers is sufficiently rich, the SI method is a useful learning algorithm. In particular, we show that larger data imbalance, a quality that is typically perceived as negative, in fact implies a better resilience of the algorithm to the statistical dependencies of the objects in bags. In addition, our results shed new light on some known issues with the SI method in the setting of linear classifiers, and we show that these issues are significantly less likely to occur in the setting of neural networks. We demonstrate our results on a synthetic dataset, and on the COCO dataset for the problem of patch classification with weak image level labels derived from captions.
A Better Resource Allocation Algorithm with Semi-Bandit Feedback
Mar 28, 2018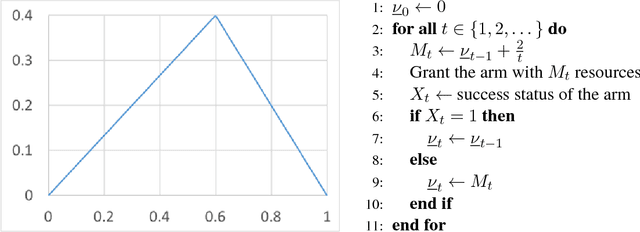

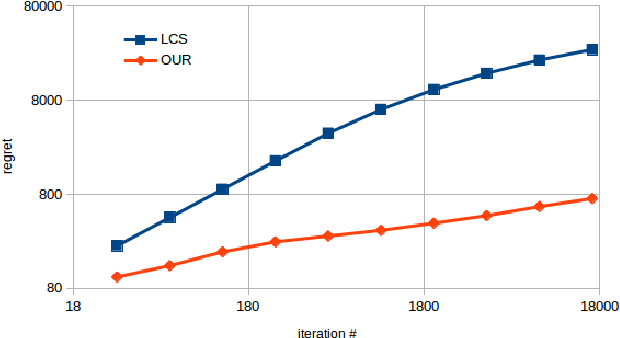
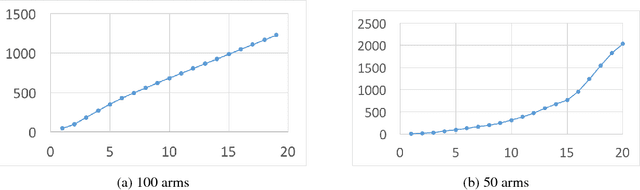
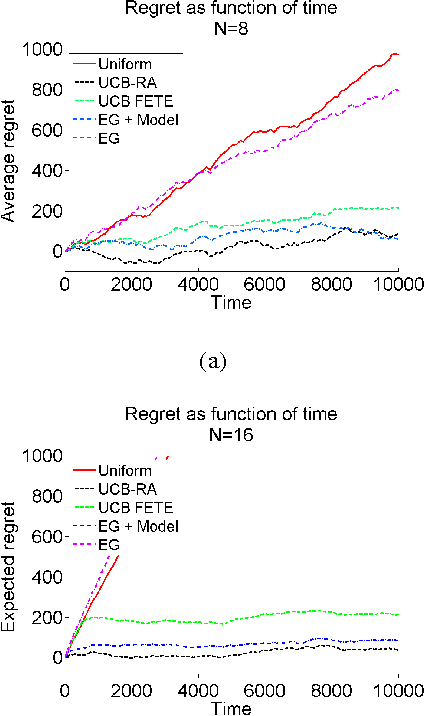
We study a sequential resource allocation problem between a fixed number of arms. On each iteration the algorithm distributes a resource among the arms in order to maximize the expected success rate. Allocating more of the resource to a given arm increases the probability that it succeeds, yet with a cut-off. We follow Lattimore et al. (2014) and assume that the probability increases linearly until it equals one, after which allocating more of the resource is wasteful. These cut-off values are fixed and unknown to the learner. We present an algorithm for this problem and prove a regret upper bound of $O(\log n)$ improving over the best known bound of $O(\log^2 n)$. Lower bounds we prove show that our upper bound is tight. Simulations demonstrate the superiority of our algorithm.
Efficient Loss-Based Decoding On Graphs For Extreme Classification
Mar 08, 2018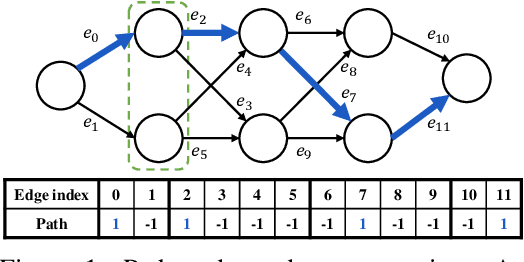
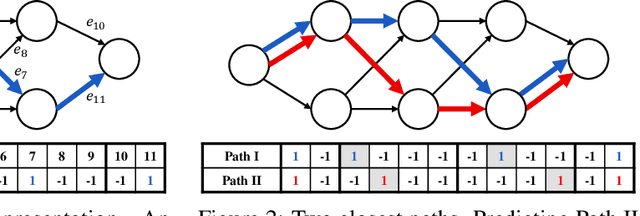

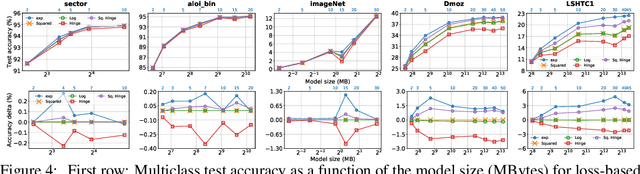
In extreme classification problems, learning algorithms are required to map instances to labels from an extremely large label set. We build on a recent extreme classification framework with logarithmic time and space, and on a general approach for error correcting output coding (ECOC), and introduce a flexible and efficient approach accompanied by bounds. Our framework employs output codes induced by graphs, and offers a tradeoff between accuracy and model size. We show how to find the sweet spot of this tradeoff using only the training data. Our experimental study demonstrates the validity of our assumptions and claims, and shows the superiority of our method compared with state-of-the-art algorithms.
Rotting Bandits
Nov 02, 2017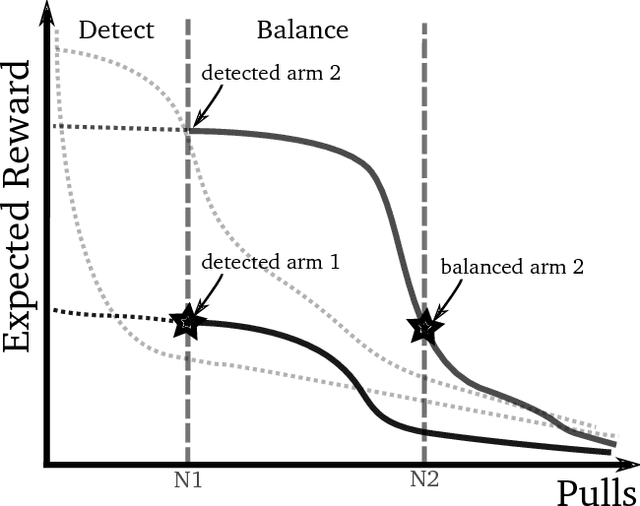
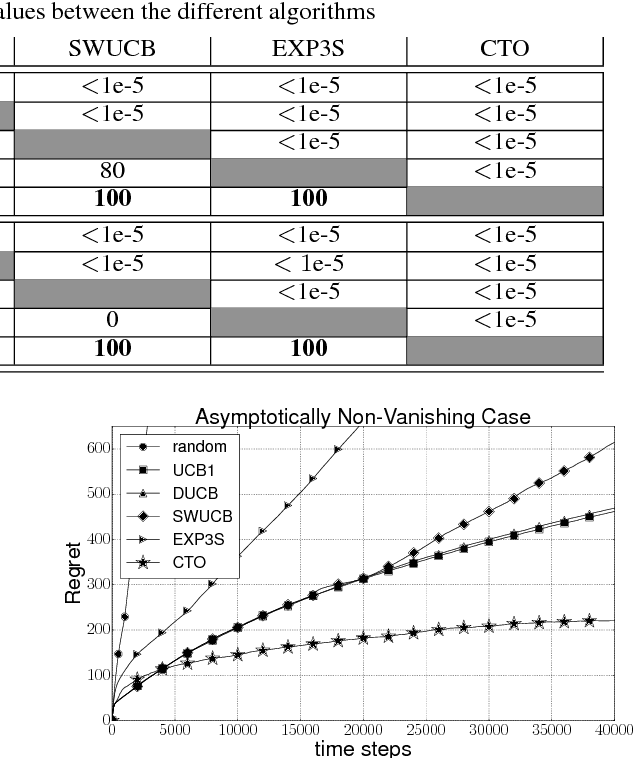
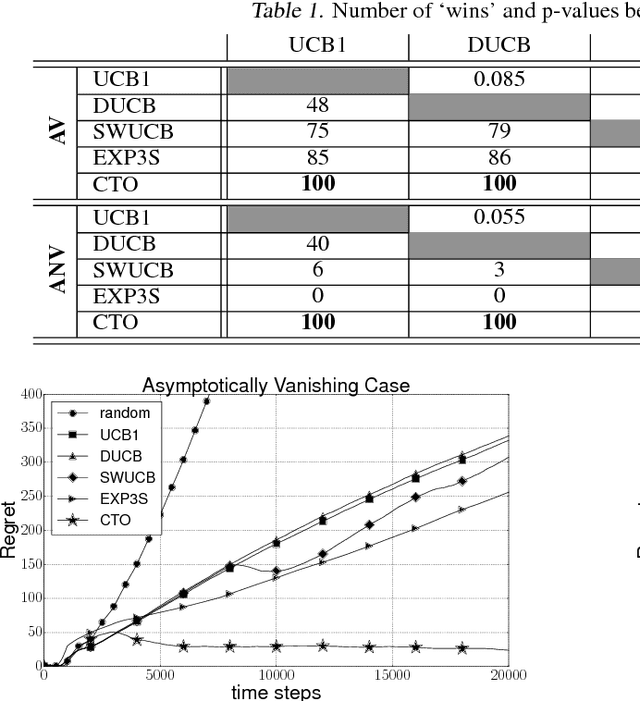
The Multi-Armed Bandits (MAB) framework highlights the tension between acquiring new knowledge (Exploration) and leveraging available knowledge (Exploitation). In the classical MAB problem, a decision maker must choose an arm at each time step, upon which she receives a reward. The decision maker's objective is to maximize her cumulative expected reward over the time horizon. The MAB problem has been studied extensively, specifically under the assumption of the arms' rewards distributions being stationary, or quasi-stationary, over time. We consider a variant of the MAB framework, which we termed Rotting Bandits, where each arm's expected reward decays as a function of the number of times it has been pulled. We are motivated by many real-world scenarios such as online advertising, content recommendation, crowdsourcing, and more. We present algorithms, accompanied by simulations, and derive theoretical guarantees.
Bandits meet Computer Architecture: Designing a Smartly-allocated Cache
Jan 31, 2016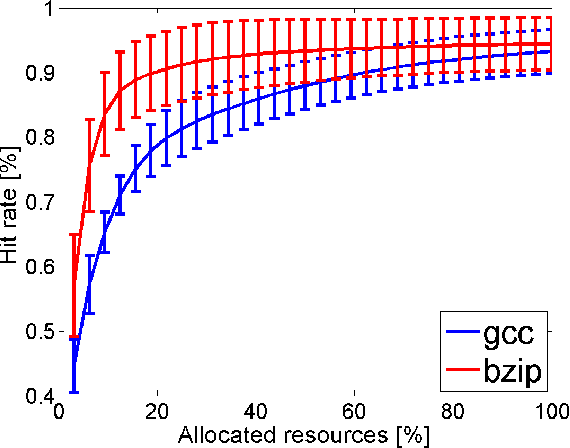
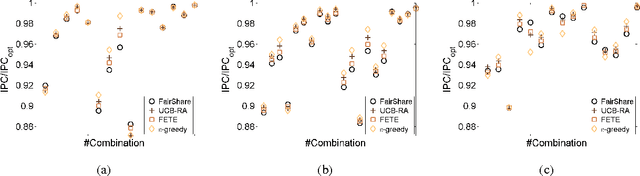
In many embedded systems, such as imaging sys- tems, the system has a single designated purpose, and same threads are executed repeatedly. Profiling thread behavior, allows the system to allocate each thread its resources in a way that improves overall system performance. We study an online resource al- locationproblem,wherearesourcemanagersimulta- neously allocates resources (exploration), learns the impact on the different consumers (learning) and im- proves allocation towards optimal performance (ex- ploitation). We build on the rich framework of multi- armed bandits and present online and offline algo- rithms. Through extensive experiments with both synthetic data and real-world cache allocation to threads we show the merits and properties of our al- gorithms
Learn on Source, Refine on Target:A Model Transfer Learning Framework with Random Forests
Nov 08, 2015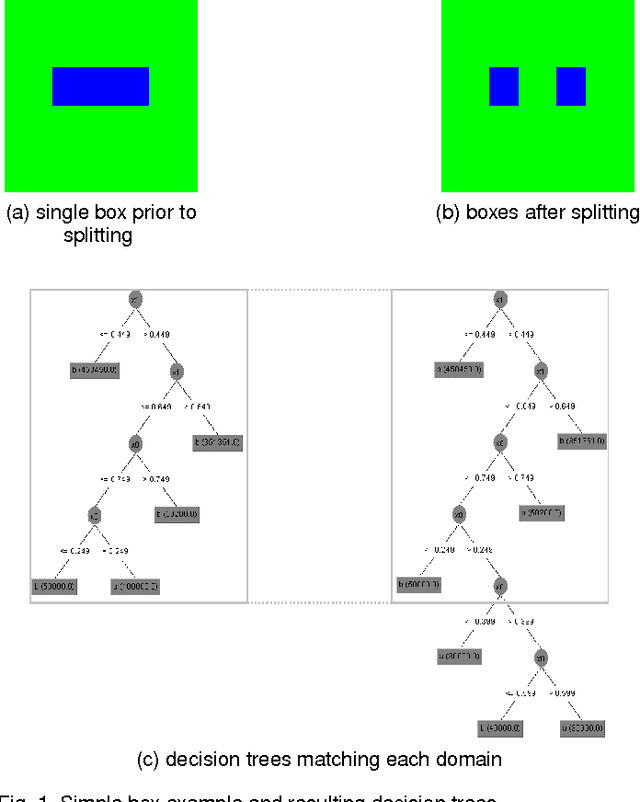
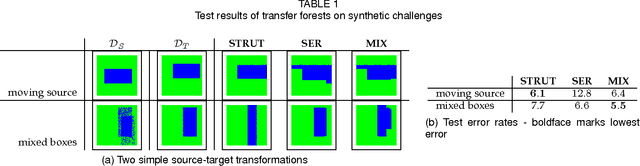
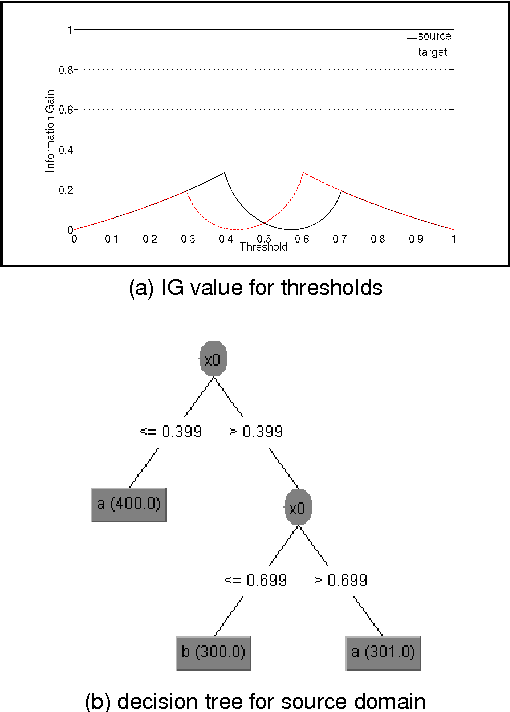
We propose novel model transfer-learning methods that refine a decision forest model M learned within a "source" domain using a training set sampled from a "target" domain, assumed to be a variation of the source. We present two random forest transfer algorithms. The first algorithm searches greedily for locally optimal modifications of each tree structure by trying to locally expand or reduce the tree around individual nodes. The second algorithm does not modify structure, but only the parameter (thresholds) associated with decision nodes. We also propose to combine both methods by considering an ensemble that contains the union of the two forests. The proposed methods exhibit impressive experimental results over a range of problems.
* 2 columns, 14 pages, TPAMI submitted
CONQUER: Confusion Queried Online Bandit Learning
Oct 30, 2015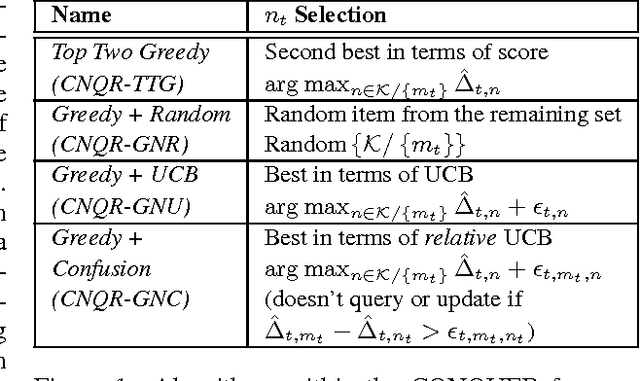
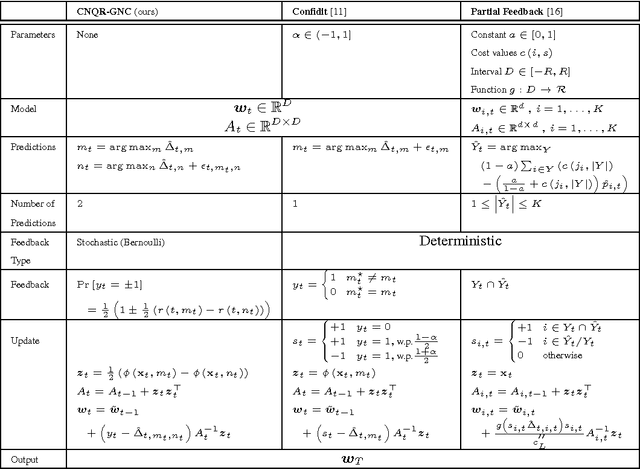
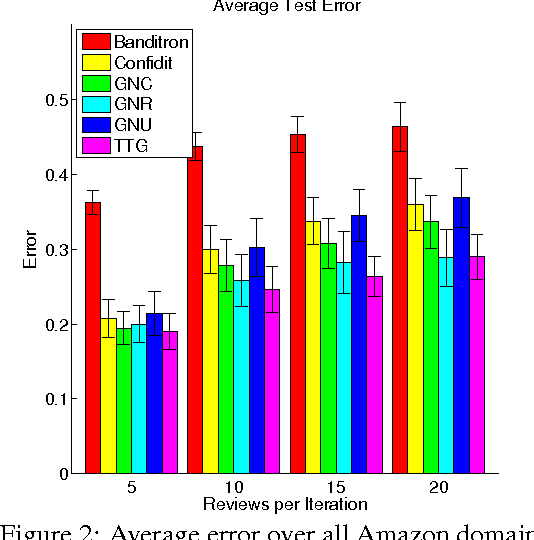
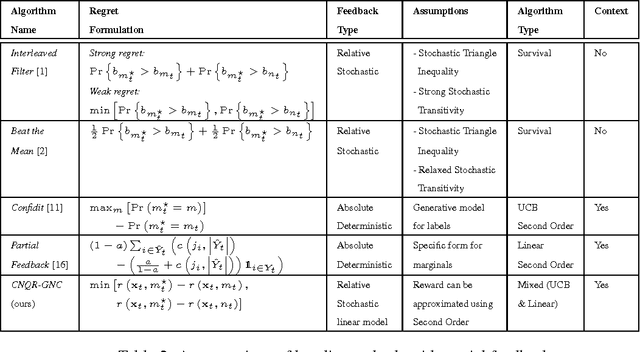
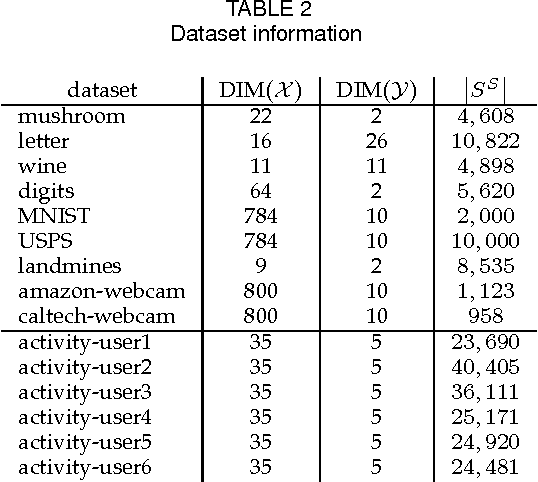
We present a new recommendation setting for picking out two items from a given set to be highlighted to a user, based on contextual input. These two items are presented to a user who chooses one of them, possibly stochastically, with a bias that favours the item with the higher value. We propose a second-order algorithm framework that members of it use uses relative upper-confidence bounds to trade off exploration and exploitation, and some explore via sampling. We analyze one algorithm in this framework in an adversarial setting with only mild assumption on the data, and prove a regret bound of $O(Q_T + \sqrt{TQ_T\log T} + \sqrt{T}\log T)$, where $T$ is the number of rounds and $Q_T$ is the cumulative approximation error of item values using a linear model. Experiments with product reviews from 33 domains show the advantage of our methods over algorithms designed for related settings, and that UCB based algorithms are inferior to greed or sampling based algorithms.
Belief Flows of Robust Online Learning
May 26, 2015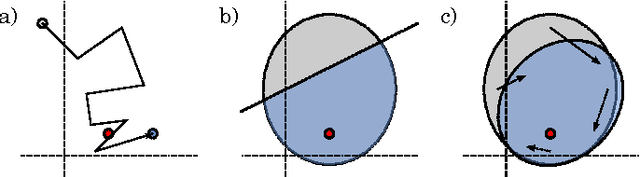

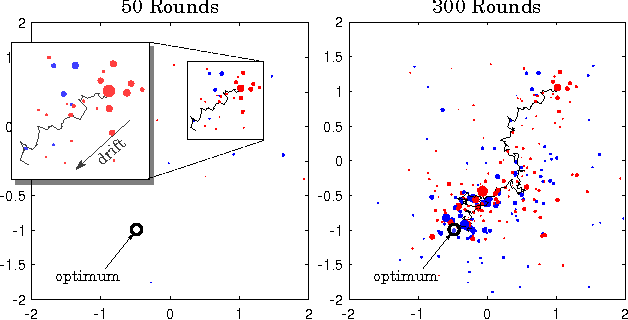
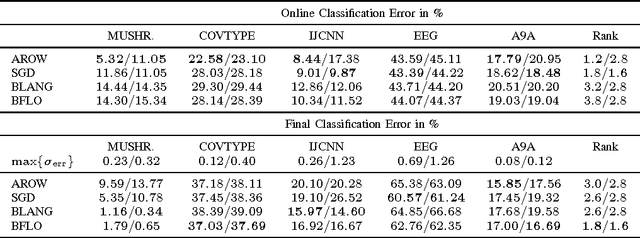
This paper introduces a new probabilistic model for online learning which dynamically incorporates information from stochastic gradients of an arbitrary loss function. Similar to probabilistic filtering, the model maintains a Gaussian belief over the optimal weight parameters. Unlike traditional Bayesian updates, the model incorporates a small number of gradient evaluations at locations chosen using Thompson sampling, making it computationally tractable. The belief is then transformed via a linear flow field which optimally updates the belief distribution using rules derived from information theoretic principles. Several versions of the algorithm are shown using different constraints on the flow field and compared with conventional online learning algorithms. Results are given for several classification tasks including logistic regression and multilayer neural networks.