 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the gap towards end-to-end autonomous vehicle system
Jan 04, 2019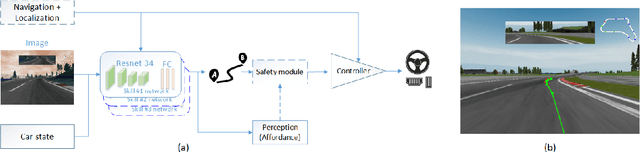

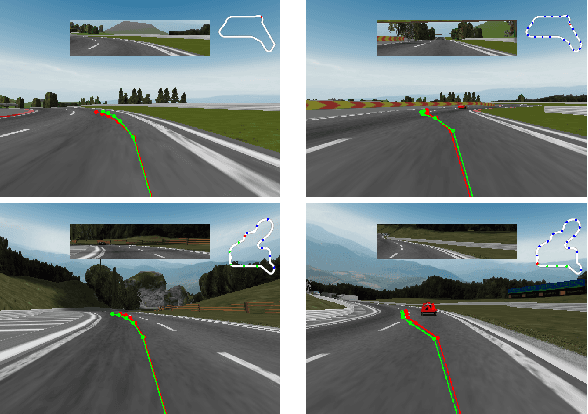
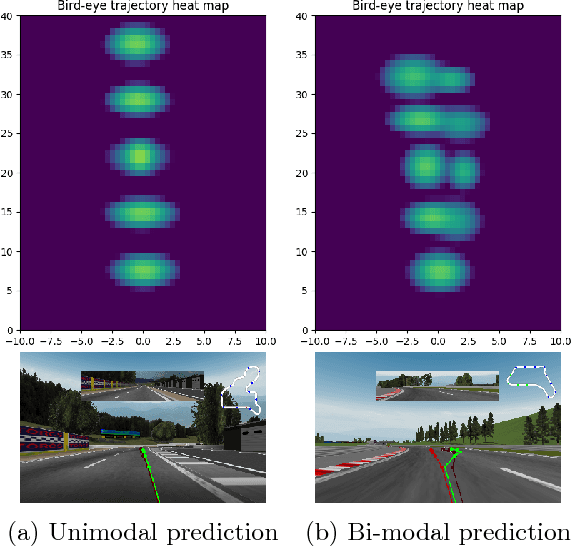
Designing a driving policy for autonomous vehicles is a difficult task. Recent studies suggested an end-toend (E2E) training of a policy to predict car actuators directly from raw sensory inputs. It is appealing due to the ease of labeled data collection and since handcrafted features are avoided. Explicit drawbacks such as interpretability, safety enforcement and learning efficiency limit the practical application of the approach. In this paper, we amend the basic E2E architecture to address these shortcomings, while retaining the power of end-to-end learning. A key element in our proposed architecture is formulation of the learning problem as learning of trajectory. We also apply a Gaussian mixture model loss to contend with multi-modal data, and adopt a finance risk measure, conditional value at risk, to emphasize rare events. We analyze the effect of each concept and present driving performance in a highway scenario in the TORCS simulator. Video is available in this link: https://www.youtube.com/watch?v=1JYNBZNOe_4
Bandits meet Computer Architecture: Designing a Smartly-allocated Cache
Jan 31, 2016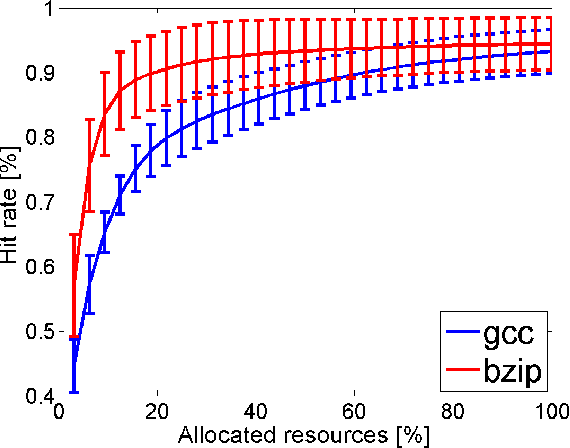
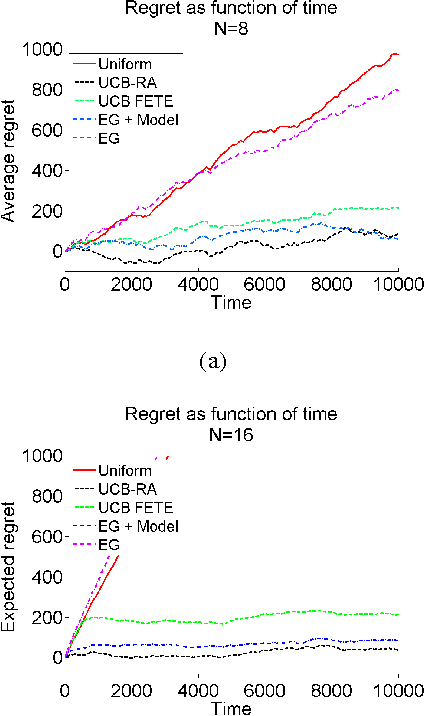
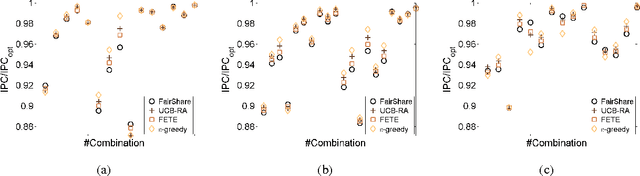
In many embedded systems, such as imaging sys- tems, the system has a single designated purpose, and same threads are executed repeatedly. Profiling thread behavior, allows the system to allocate each thread its resources in a way that improves overall system performance. We study an online resource al- locationproblem,wherearesourcemanagersimulta- neously allocates resources (exploration), learns the impact on the different consumers (learning) and im- proves allocation towards optimal performance (ex- ploitation). We build on the rich framework of multi- armed bandits and present online and offline algo- rithms. Through extensive experiments with both synthetic data and real-world cache allocation to threads we show the merits and properties of our al- gorithms
Optimizing the CVaR via Sampling
Nov 22, 2014
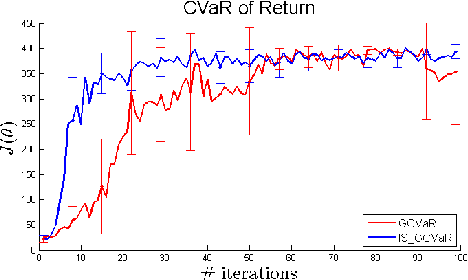
Conditional Value at Risk (CVaR) is a prominent risk measure that is being used extensively in various domains. We develop a new formula for the gradient of the CVaR in the form of a conditional expectation. Based on this formula, we propose a novel sampling-based estimator for the CVaR gradient, in the spirit of the likelihood-ratio method. We analyze the bias of the estimator, and prove the convergence of a corresponding stochastic gradient descent algorithm to a local CVaR optimum. Our method allows to consider CVaR optimization in new domains. As an example, we consider a reinforcement learning application, and learn a risk-sensitive controller for the game of Tetris.