 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONQUER: Confusion Queried Online Bandit Learning
Paper and Code
Oct 30, 2015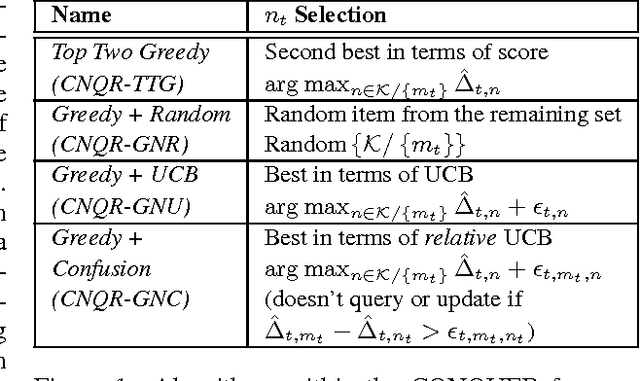
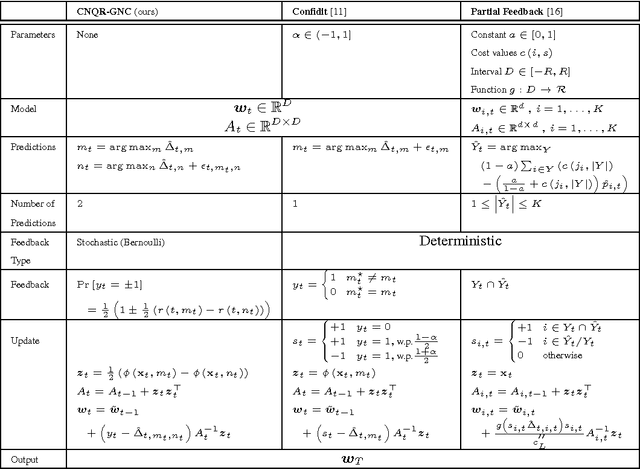
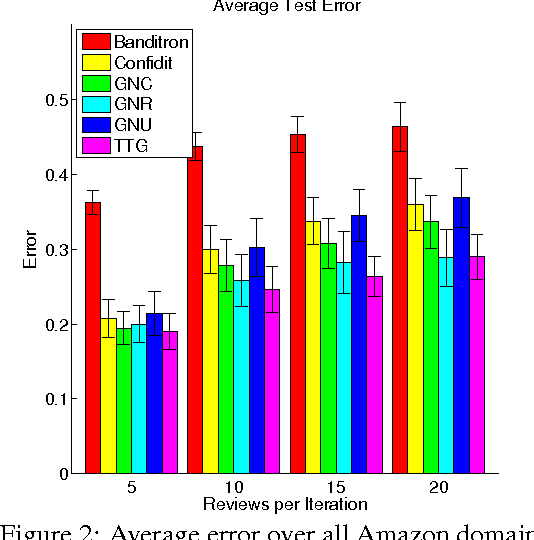
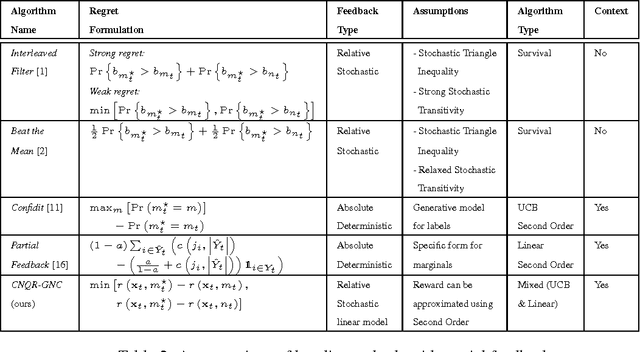
We present a new recommendation setting for picking out two items from a given set to be highlighted to a user, based on contextual input. These two items are presented to a user who chooses one of them, possibly stochastically, with a bias that favours the item with the higher value. We propose a second-order algorithm framework that members of it use uses relative upper-confidence bounds to trade off exploration and exploitation, and some explore via sampling. We analyze one algorithm in this framework in an adversarial setting with only mild assumption on the data, and prove a regret bound of $O(Q_T + \sqrt{TQ_T\log T} + \sqrt{T}\log T)$, where $T$ is the number of rounds and $Q_T$ is the cumulative approximation error of item values using a linear model. Experiments with product reviews from 33 domains show the advantage of our methods over algorithms designed for related settings, and that UCB based algorithms are inferior to greed or sampling based algorithms.