 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordLight: Learning Decentralized Coordination for Network-Wide Traffic Signal Control
Mar 25, 2026Adaptive traffic signal control (ATSC) is crucial in alleviating congestion, maximizing throughput and promoting sustainable mobility in ever-expanding cities. Multi-Agent Reinforcement Learning (MARL) has recently shown significant potential in addressing complex traffic dynamics, but the intricacies of partial observability and coordination in decentralized environments still remain key challenges in formulating scalable and efficient control strategies. To address these challenges, we present CoordLight, a MARL-based framework designed to improve intra-neighborhood traffic by enhancing decision-making at individual junctions (agents), as well as coordination with neighboring agents, thereby scaling up to network-level traffic optimization. Specifically, we introduce the Queue Dynamic State Encoding (QDSE), a novel state representation based on vehicle queuing models, which strengthens the agents' capability to analyze, predict, and respond to local traffic dynamics. We further propose an advanced MARL algorithm, named Neighbor-aware Policy Optimization (NAPO). It integrates an attention mechanism that discerns the state and action dependencies among adjacent agents, aiming to facilitate more coordinated decision-making, and to improve policy learning updates through robust advantage calculation. This enables agents to identify and prioritize crucial interactions with influential neighbors, thus enhancing the targeted coordination and collaboration among agents. Through comprehensive evaluations against state-of-the-art traffic signal control methods over three real-world traffic datasets composed of up to 196 intersections, we empirically show that CoordLight consistently exhibits superior performance across diverse traffic networks with varying traffic flows. The code is available at https://github.com/marmotlab/CoordLight
ViSIL: Unified Evaluation of Information Loss in Multimodal Video Captioning
Jan 14, 2026Multimodal video captioning condenses dense footage into a structured format of keyframes and natural language. By creating a cohesive multimodal summary, this approach anchors generative AI in rich semantic evidence and serves as a lightweight proxy for high-efficiency retrieval. However, traditional metrics like BLEU or ROUGE fail to quantify information coverage across disparate modalities, such as comparing a paragraph of text to a sequence of keyframes. To address this, we propose the Video Summary Information Loss (ViSIL) score, an information-theoretic framework that quantifies the video information not captured by a summary via vision-language model (VLM) inference. By measuring the information loss, ViSIL is a unified metric that enables direct comparison across multimodal summary formats despite their structural discrepancies. Our results demonstrate that ViSIL scores show a statistically significant correlation with both human and VLM performance on Video Question Answering (VQA) tasks. ViSIL also enables summary selection to optimize the trade-off between information loss and processing speed, establishing a Pareto-optimal frontier that outperforms text summaries by $7\%$ in VQA accuracy without increasing processing load.
A Challenge to Build Neuro-Symbolic Video Agents
May 20, 2025Modern video understanding systems excel at tasks such as scene classification, object detection, and short video retrieval. However, as video analysis becomes increasingly central to real-world applications, there is a growing need for proactive video agents for the systems that not only interpret video streams but also reason about events and take informed actions. A key obstacle in this direction is temporal reasoning: while deep learning models have made remarkable progress in recognizing patterns within individual frames or short clips, they struggle to understand the sequencing and dependencies of events over time, which is critical for action-driven decision-making. Addressing this limitation demands moving beyond conventional deep learning approaches. We posit that tackling this challenge requires a neuro-symbolic perspective, where video queries are decomposed into atomic events, structured into coherent sequences, and validated against temporal constraints. Such an approach can enhance interpretability, enable structured reasoning, and provide stronger guarantees on system behavior, all key properties for advancing trustworthy video agents. To this end, we present a grand challenge to the research community: developing the next generation of intelligent video agents that integrate three core capabilities: (1) autonomous video search and analysis, (2) seamless real-world interaction, and (3) advanced content generation. By addressing these pillars, we can transition from passive perception to intelligent video agents that reason, predict, and act, pushing the boundaries of video understanding.
We'll Fix it in Post: Improving Text-to-Video Generation with Neuro-Symbolic Feedback
Apr 24, 2025
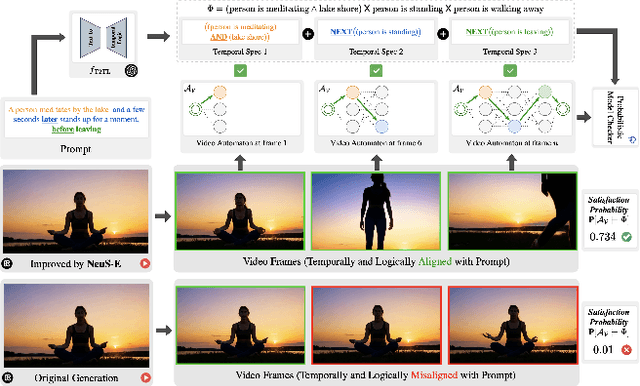


Current text-to-video (T2V) generation models are increasingly popular due to their ability to produce coherent videos from textual prompts. However, these models often struggle to generate semantically and temporally consistent videos when dealing with longer, more complex prompts involving multiple objects or sequential events. Additionally, the high computational costs associated with training or fine-tuning make direct improvements impractical. To overcome these limitations, we introduce \(\projectname\), a novel zero-training video refinement pipeline that leverages neuro-symbolic feedback to automatically enhance video generation, achieving superior alignment with the prompts. Our approach first derives the neuro-symbolic feedback by analyzing a formal video representation and pinpoints semantically inconsistent events, objects, and their corresponding frames. This feedback then guides targeted edits to the original video. Extensive empirical evaluations on both open-source and proprietary T2V models demonstrate that \(\projectname\) significantly enhances temporal and logical alignment across diverse prompts by almost $40\%$.
Learning Human Perception Dynamics for Informative Robot Communication
Feb 03, 2025



Human-robot cooperative navigation is challenging in environments with incomplete information. We introduce CoNav-Maze, a simulated robotics environment where a robot navigates using local perception while a human operator provides guidance based on an inaccurate map. The robot can share its camera views to improve the operator's understanding of the environment. To enable efficient human-robot cooperation, we propose Information Gain Monte Carlo Tree Search (IG-MCTS), an online planning algorithm that balances autonomous movement and informative communication. Central to IG-MCTS is a neural human perception dynamics model that estimates how humans distill information from robot communications. We collect a dataset through a crowdsourced mapping task in CoNav-Maze and train this model using a fully convolutional architecture with data augmentation. User studies show that IG-MCTS outperforms teleoperation and instruction-following baselines, achieving comparable task performance with significantly less communication and lower human cognitive load, as evidenced by eye-tracking metrics.
Dense Dynamics-Aware Reward Synthesis: Integrating Prior Experience with Demonstrations
Dec 02, 2024



Many continuous control problems can be formulated as sparse-reward reinforcement learning (RL) tasks. In principle, online RL methods can automatically explore the state space to solve each new task. However, discovering sequences of actions that lead to a non-zero reward becomes exponentially more difficult as the task horizon increases. Manually shaping rewards can accelerate learning for a fixed task, but it is an arduous process that must be repeated for each new environment. We introduce a systematic reward-shaping framework that distills the information contained in 1) a task-agnostic prior data set and 2) a small number of task-specific expert demonstrations, and then uses these priors to synthesize dense dynamics-aware rewards for the given task. This supervision substantially accelerates learning in our experiments, and we provide analysis demonstrating how the approach can effectively guide online learning agents to faraway goals.
SynDiff-AD: Improving Semantic Segmentation and End-to-End Autonomous Driving with Synthetic Data from Latent Diffusion Models
Nov 25, 2024In recent years, significant progress has been made in collecting large-scale datasets to improve segmentation and autonomous driving models. These large-scale datasets are often dominated by common environmental conditions such as "Clear and Day" weather, leading to decreased performance in under-represented conditions like "Rainy and Night". To address this issue, we introduce SynDiff-AD, a novel data augmentation pipeline that leverages diffusion models (DMs) to generate realistic images for such subgroups. SynDiff-AD uses ControlNet-a DM that guides data generation conditioned on semantic maps-along with a novel prompting scheme that generates subgroup-specific, semantically dense prompts. By augmenting datasets with SynDiff-AD, we improve the performance of segmentation models like Mask2Former and SegFormer by up to 1.2% and 2.3% on the Waymo dataset, and up to 1.4% and 0.7% on the DeepDrive dataset, respectively. Additionally, we demonstrate that our SynDiff-AD pipeline enhances the driving performance of end-to-end autonomous driving models, like AIM-2D and AIM-BEV, by up to 20% across diverse environmental conditions in the CARLA autonomous driving simulator, providing a more robust model.
Any2Any: Incomplete Multimodal Retrieval with Conformal Prediction
Nov 25, 2024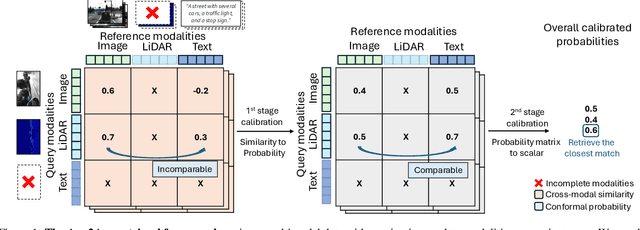
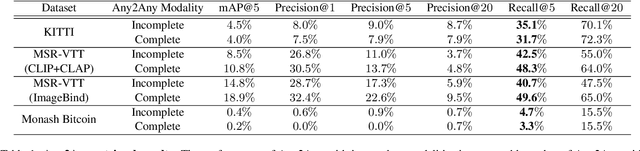
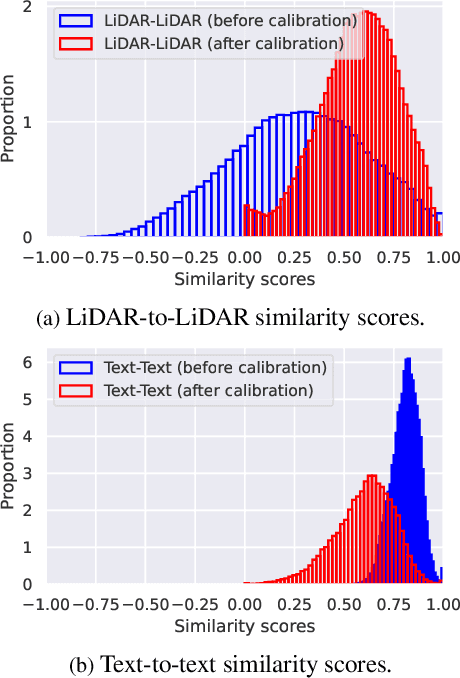
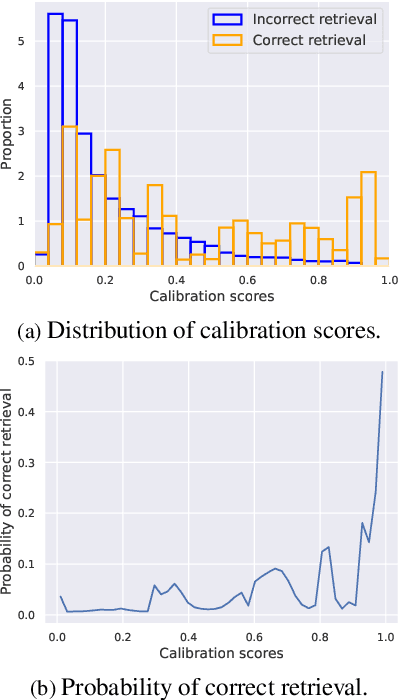
Autonomous agents perceive and interpret their surroundings by integrating multimodal inputs, such as vision, audio, and LiDAR. These perceptual modalities support retrieval tasks, such as place recognition in robotics. However, current multimodal retrieval systems encounter difficulties when parts of the data are missing due to sensor failures or inaccessibility, such as silent videos or LiDAR scans lacking RGB information. We propose Any2Any-a novel retrieval framework that addresses scenarios where both query and reference instances have incomplete modalities. Unlike previous methods limited to the imputation of two modalities, Any2Any handles any number of modalities without training generative models. It calculates pairwise similarities with cross-modal encoders and employs a two-stage calibration process with conformal prediction to align the similarities. Any2Any enables effective retrieval across multimodal datasets, e.g., text-LiDAR and text-time series. It achieves a Recall@5 of 35% on the KITTI dataset, which is on par with baseline models with complete modalities.
Neuro-Symbolic Evaluation of Text-to-Video Models using Formalf Verification
Nov 22, 2024Recent advancements in text-to-video models such as Sora, Gen-3, MovieGen, and CogVideoX are pushing the boundaries of synthetic video generation, with adoption seen in fields like robotics, autonomous driving, and entertainment. As these models become prevalent, various metrics and benchmarks have emerged to evaluate the quality of the generated videos. However, these metrics emphasize visual quality and smoothness, neglecting temporal fidelity and text-to-video alignment, which are crucial for safety-critical applications. To address this gap, we introduce NeuS-V, a novel synthetic video evaluation metric that rigorously assesses text-to-video alignment using neuro-symbolic formal verification techniques. Our approach first converts the prompt into a formally defined Temporal Logic (TL) specification and translates the generated video into an automaton representation. Then, it evaluates the text-to-video alignment by formally checking the video automaton against the TL specification. Furthermore, we present a dataset of temporally extended prompts to evaluate state-of-the-art video generation models against our benchmark. We find that NeuS-V demonstrates a higher correlation by over 5x with human evaluations when compared to existing metrics. Our evaluation further reveals that current video generation models perform poorly on these temporally complex prompts, highlighting the need for future work in improving text-to-video generation capabilities.
Human-Agent Coordination in Games under Incomplete Information via Multi-Step Intent
Oct 23, 2024Strategic coordination between autonomous agents and human partners under incomplete information can be modeled as turn-based cooperative games. We extend a turn-based game under incomplete information, the shared-control game, to allow players to take multiple actions per turn rather than a single action. The extension enables the use of multi-step intent, which we hypothesize will improve performance in long-horizon tasks. To synthesize cooperative policies for the agent in this extended game, we propose an approach featuring a memory module for a running probabilistic belief of the environment dynamics and an online planning algorithm called IntentMCTS. This algorithm strategically selects the next action by leveraging any communicated multi-step intent via reward augmentation while considering the current belief. Agent-to-agent simulations in the Gnomes at Night testbed demonstrate that IntentMCTS requires fewer steps and control switches than baseline methods. A human-agent user study corroborates these findings, showing an 18.52% higher success rate compared to the heuristic baseline and a 5.56% improvement over the single-step prior work. Participants also report lower cognitive load, frustration, and higher satisfaction with the IntentMCTS agent partner.