 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny2Any: Incomplete Multimodal Retrieval with Conformal Prediction
Paper and Code
Nov 25, 2024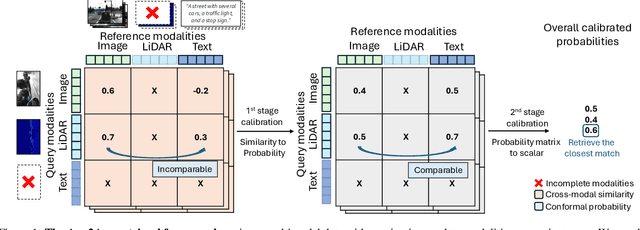
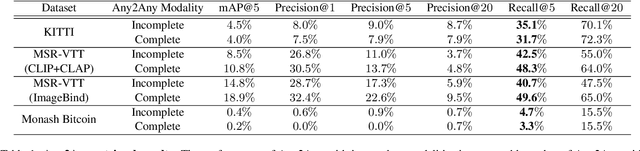
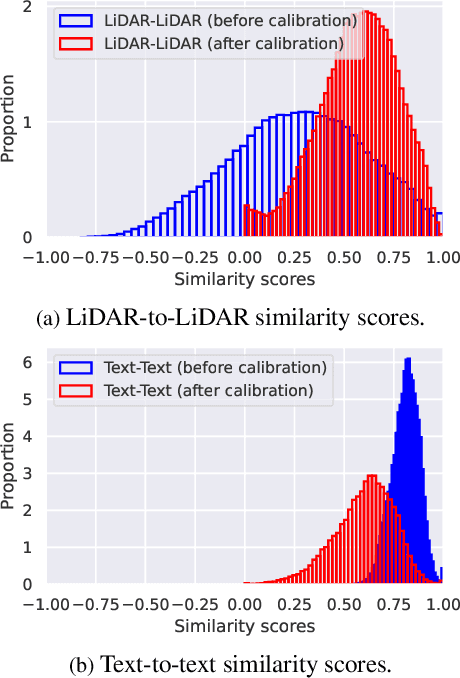
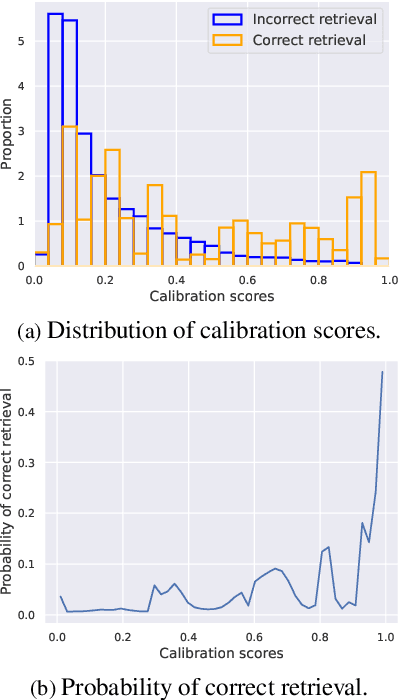
Autonomous agents perceive and interpret their surroundings by integrating multimodal inputs, such as vision, audio, and LiDAR. These perceptual modalities support retrieval tasks, such as place recognition in robotics. However, current multimodal retrieval systems encounter difficulties when parts of the data are missing due to sensor failures or inaccessibility, such as silent videos or LiDAR scans lacking RGB information. We propose Any2Any-a novel retrieval framework that addresses scenarios where both query and reference instances have incomplete modalities. Unlike previous methods limited to the imputation of two modalities, Any2Any handles any number of modalities without training generative models. It calculates pairwise similarities with cross-modal encoders and employs a two-stage calibration process with conformal prediction to align the similarities. Any2Any enables effective retrieval across multimodal datasets, e.g., text-LiDAR and text-time series. It achieves a Recall@5 of 35% on the KITTI dataset, which is on par with baseline models with complete modalities.