 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymLoc: Towards Asymmetric Feature Matching for Efficient Visual Localization
Apr 10, 2026Precise and real-time visual localization is critical for applications like AR/VR and robotics, especially on resource-constrained edge devices such as smart glasses, where battery life and heat dissipation can be a primary concerns. While many efficient models exist, further reducing compute without sacrificing accuracy is essential for practical deployment. To address this, we propose asymmetric visual localization: a large Teacher model processes pre-mapped database images offline, while a lightweight Student model processes the query image online. This creates a challenge in matching features from two different models without resorting to heavy, learned matchers. We introduce AsymLoc, a novel distillation framework that aligns a Student to its Teacher through a combination of a geometry-driven matching objective and a joint detector-descriptor distillation objective, enabling fast, parameter-less nearest-neighbor matching. Extensive experiments on HPatches, ScanNet, IMC2022, and Aachen show that AsymLoc achieves up to 95% of the teacher's localization accuracy using an order of magnitude smaller models, significantly outperforming existing baselines and establishing a new state-of-the-art efficiency-accuracy trade-off.
SSR: A Generic Framework for Text-Aided Map Compression for Localization
Mar 04, 2026Mapping is crucial in robotics for localization and downstream decision-making. As robots are deployed in ever-broader settings, the maps they rely on continue to increase in size. However, storing these maps indefinitely (cold storage), transferring them across networks, or sending localization queries to cloud-hosted maps imposes prohibitive memory and bandwidth costs. We propose a text-enhanced compression framework that reduces both memory and bandwidth footprints while retaining high-fidelity localization. The key idea is to treat text as an alternative modality: one that can be losslessly compressed with large language models. We propose leveraging lightweight text descriptions combined with very small image feature vectors, which capture "complementary information" as a compact representation for the mapping task. Building on this, our novel technique, Similarity Space Replication (SSR), learns an adaptive image embedding in one shot that captures only the information "complementary" to the text descriptions. We validate our compression framework on multiple downstream localization tasks, including Visual Place Recognition as well as object-centric Monte Carlo localization in both indoor and outdoor settings. SSR achieves 2 times better compression than competing baselines on state-of-the-art datasets, including TokyoVal, Pittsburgh30k, Replica, and KITTI.
SparseLoc: Sparse Open-Set Landmark-based Global Localization for Autonomous Navigation
Mar 30, 2025



Global localization is a critical problem in autonomous navigation, enabling precise positioning without reliance on GPS. Modern global localization techniques often depend on dense LiDAR maps, which, while precise, require extensive storage and computational resources. Recent approaches have explored alternative methods, such as sparse maps and learned features, but they suffer from poor robustness and generalization. We propose SparseLoc, a global localization framework that leverages vision-language foundation models to generate sparse, semantic-topometric maps in a zero-shot manner. It combines this map representation with a Monte Carlo localization scheme enhanced by a novel late optimization strategy, ensuring improved pose estimation. By constructing compact yet highly discriminative maps and refining localization through a carefully designed optimization schedule, SparseLoc overcomes the limitations of existing techniques, offering a more efficient and robust solution for global localization. Our system achieves over a 5X improvement in localization accuracy compared to existing sparse mapping techniques. Despite utilizing only 1/500th of the points of dense mapping methods, it achieves comparable performance, maintaining an average global localization error below 5m and 2 degrees on KITTI sequences.
Any2Any: Incomplete Multimodal Retrieval with Conformal Prediction
Nov 25, 2024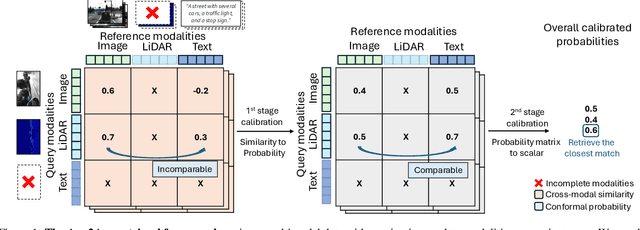
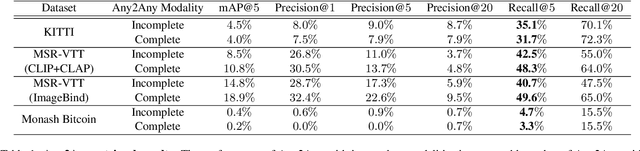
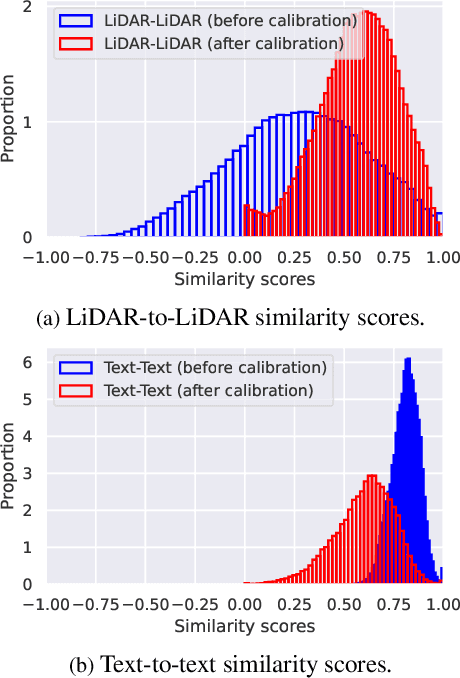
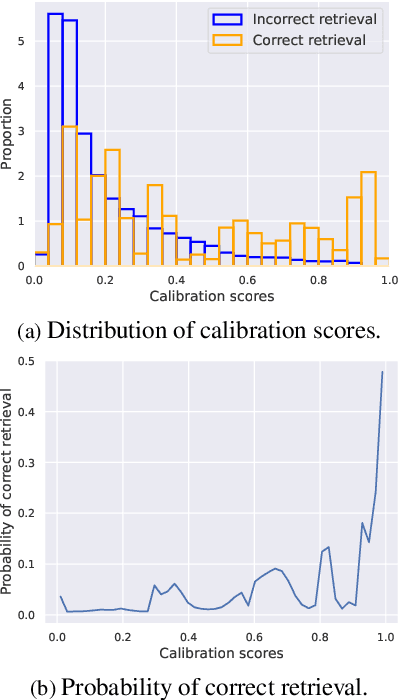
Autonomous agents perceive and interpret their surroundings by integrating multimodal inputs, such as vision, audio, and LiDAR. These perceptual modalities support retrieval tasks, such as place recognition in robotics. However, current multimodal retrieval systems encounter difficulties when parts of the data are missing due to sensor failures or inaccessibility, such as silent videos or LiDAR scans lacking RGB information. We propose Any2Any-a novel retrieval framework that addresses scenarios where both query and reference instances have incomplete modalities. Unlike previous methods limited to the imputation of two modalities, Any2Any handles any number of modalities without training generative models. It calculates pairwise similarities with cross-modal encoders and employs a two-stage calibration process with conformal prediction to align the similarities. Any2Any enables effective retrieval across multimodal datasets, e.g., text-LiDAR and text-time series. It achieves a Recall@5 of 35% on the KITTI dataset, which is on par with baseline models with complete modalities.
Neuro-Symbolic Evaluation of Text-to-Video Models using Formalf Verification
Nov 22, 2024Recent advancements in text-to-video models such as Sora, Gen-3, MovieGen, and CogVideoX are pushing the boundaries of synthetic video generation, with adoption seen in fields like robotics, autonomous driving, and entertainment. As these models become prevalent, various metrics and benchmarks have emerged to evaluate the quality of the generated videos. However, these metrics emphasize visual quality and smoothness, neglecting temporal fidelity and text-to-video alignment, which are crucial for safety-critical applications. To address this gap, we introduce NeuS-V, a novel synthetic video evaluation metric that rigorously assesses text-to-video alignment using neuro-symbolic formal verification techniques. Our approach first converts the prompt into a formally defined Temporal Logic (TL) specification and translates the generated video into an automaton representation. Then, it evaluates the text-to-video alignment by formally checking the video automaton against the TL specification. Furthermore, we present a dataset of temporally extended prompts to evaluate state-of-the-art video generation models against our benchmark. We find that NeuS-V demonstrates a higher correlation by over 5x with human evaluations when compared to existing metrics. Our evaluation further reveals that current video generation models perform poorly on these temporally complex prompts, highlighting the need for future work in improving text-to-video generation capabilities.
Exploiting Distribution Constraints for Scalable and Efficient Image Retrieval
Oct 09, 2024



Image retrieval is crucial in robotics and computer vision, with downstream applications in robot place recognition and vision-based product recommendations. Modern retrieval systems face two key challenges: scalability and efficiency. State-of-the-art image retrieval systems train specific neural networks for each dataset, an approach that lacks scalability. Furthermore, since retrieval speed is directly proportional to embedding size, existing systems that use large embeddings lack efficiency. To tackle scalability, recent works propose using off-the-shelf foundation models. However, these models, though applicable across datasets, fall short in achieving performance comparable to that of dataset-specific models. Our key observation is that, while foundation models capture necessary subtleties for effective retrieval, the underlying distribution of their embedding space can negatively impact cosine similarity searches. We introduce Autoencoders with Strong Variance Constraints (AE-SVC), which, when used for projection, significantly improves the performance of foundation models. We provide an in-depth theoretical analysis of AE-SVC. Addressing efficiency, we introduce Single-shot Similarity Space Distillation ((SS)$_2$D), a novel approach to learn embeddings with adaptive sizes that offers a better trade-off between size and performance. We conducted extensive experiments on four retrieval datasets, including Stanford Online Products (SoP) and Pittsburgh30k, using four different off-the-shelf foundation models, including DinoV2 and CLIP. AE-SVC demonstrates up to a $16\%$ improvement in retrieval performance, while (SS)$_2$D shows a further $10\%$ improvement for smaller embedding sizes.
Neuro-Symbolic Video Search
Mar 16, 2024The unprecedented surge in video data production in recent years necessitates efficient tools to extract meaningful frames from videos for downstream tasks. Long-term temporal reasoning is a key desideratum for frame retrieval systems. While state-of-the-art foundation models, like VideoLLaMA and ViCLIP, are proficient in short-term semantic understanding, they surprisingly fail at long-term reasoning across frames. A key reason for this failure is that they intertwine per-frame perception and temporal reasoning into a single deep network. Hence, decoupling but co-designing semantic understanding and temporal reasoning is essential for efficient scene identification. We propose a system that leverages vision-language models for semantic understanding of individual frames but effectively reasons about the long-term evolution of events using state machines and temporal logic (TL) formulae that inherently capture memory. Our TL-based reasoning improves the F1 score of complex event identification by 9-15% compared to benchmarks that use GPT4 for reasoning on state-of-the-art self-driving datasets such as Waymo and NuScenes.
LIP-Loc: LiDAR Image Pretraining for Cross-Modal Localization
Dec 27, 2023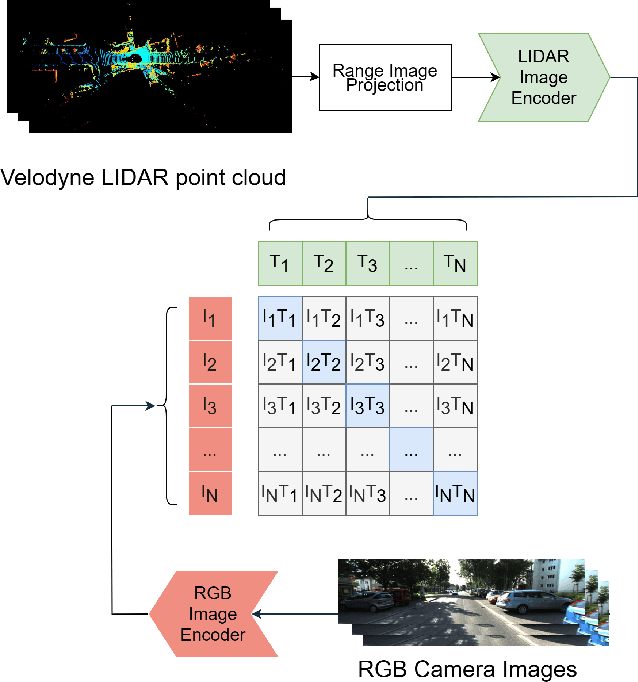
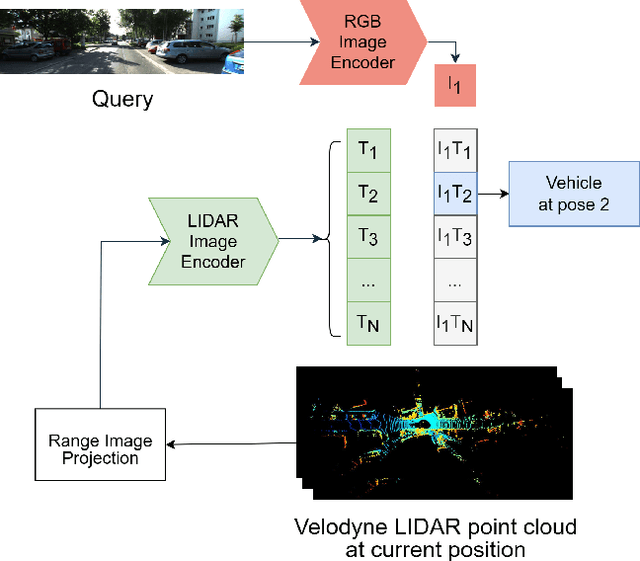
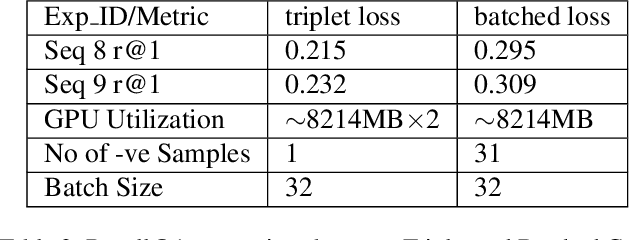
Global visual localization in LiDAR-maps, crucial for autonomous driving applications, remains largely unexplored due to the challenging issue of bridging the cross-modal heterogeneity gap. Popular multi-modal learning approach Contrastive Language-Image Pre-Training (CLIP) has popularized contrastive symmetric loss using batch construction technique by applying it to multi-modal domains of text and image. We apply this approach to the domains of 2D image and 3D LiDAR points on the task of cross-modal localization. Our method is explained as follows: A batch of N (image, LiDAR) pairs is constructed so as to predict what is the right match between N X N possible pairings across the batch by jointly training an image encoder and LiDAR encoder to learn a multi-modal embedding space. In this way, the cosine similarity between N positive pairings is maximized, whereas that between the remaining negative pairings is minimized. Finally, over the obtained similarity scores, a symmetric cross-entropy loss is optimized. To the best of our knowledge, this is the first work to apply batched loss approach to a cross-modal setting of image & LiDAR data and also to show Zero-shot transfer in a visual localization setting. We conduct extensive analyses on standard autonomous driving datasets such as KITTI and KITTI-360 datasets. Our method outperforms state-of-the-art recall@1 accuracy on the KITTI-360 dataset by 22.4%, using only perspective images, in contrast to the state-of-the-art approach, which utilizes the more informative fisheye images. Additionally, this superior performance is achieved without resorting to complex architectures. Moreover, we demonstrate the zero-shot capabilities of our model and we beat SOTA by 8% without even training on it. Furthermore, we establish the first benchmark for cross-modal localization on the KITTI dataset.
ALT-Pilot: Autonomous navigation with Language augmented Topometric maps
Oct 03, 2023



We present an autonomous navigation system that operates without assuming HD LiDAR maps of the environment. Our system, ALT-Pilot, relies only on publicly available road network information and a sparse (and noisy) set of crowdsourced language landmarks. With the help of onboard sensors and a language-augmented topometric map, ALT-Pilot autonomously pilots the vehicle to any destination on the road network. We achieve this by leveraging vision-language models pre-trained on web-scale data to identify potential landmarks in a scene, incorporating vision-language features into the recursive Bayesian state estimation stack to generate global (route) plans, and a reactive trajectory planner and controller operating in the vehicle frame. We implement and evaluate ALT-Pilot in simulation and on a real, full-scale autonomous vehicle and report improvements over state-of-the-art topometric navigation systems by a factor of 3x on localization accuracy and 5x on goal reachability