 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIP-Loc: LiDAR Image Pretraining for Cross-Modal Localization
Dec 27, 2023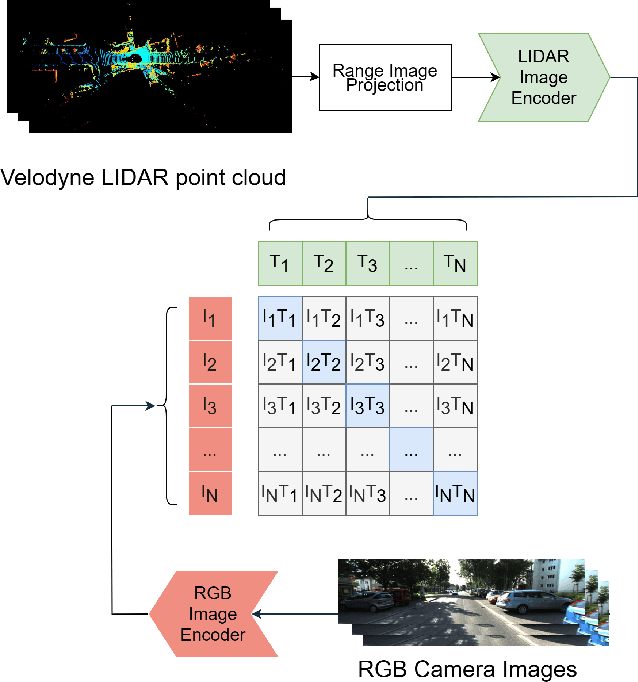
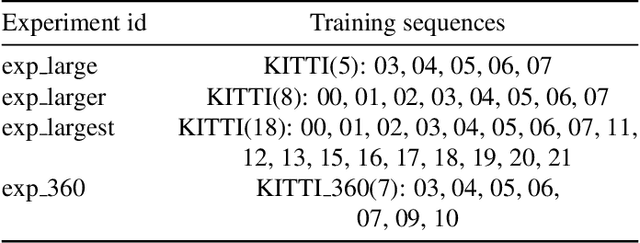
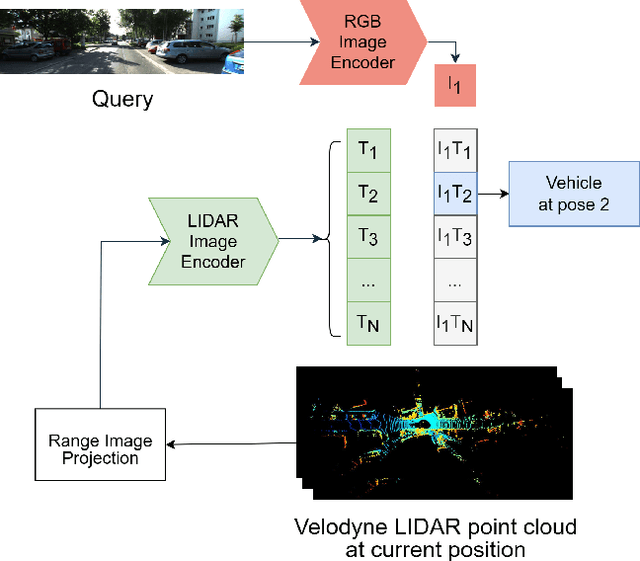
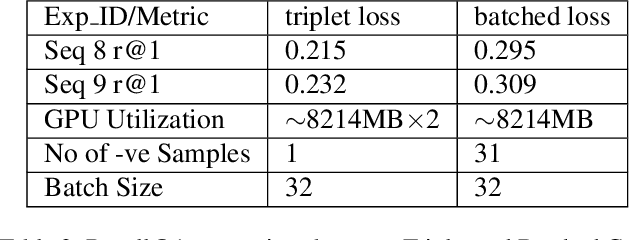
Global visual localization in LiDAR-maps, crucial for autonomous driving applications, remains largely unexplored due to the challenging issue of bridging the cross-modal heterogeneity gap. Popular multi-modal learning approach Contrastive Language-Image Pre-Training (CLIP) has popularized contrastive symmetric loss using batch construction technique by applying it to multi-modal domains of text and image. We apply this approach to the domains of 2D image and 3D LiDAR points on the task of cross-modal localization. Our method is explained as follows: A batch of N (image, LiDAR) pairs is constructed so as to predict what is the right match between N X N possible pairings across the batch by jointly training an image encoder and LiDAR encoder to learn a multi-modal embedding space. In this way, the cosine similarity between N positive pairings is maximized, whereas that between the remaining negative pairings is minimized. Finally, over the obtained similarity scores, a symmetric cross-entropy loss is optimized. To the best of our knowledge, this is the first work to apply batched loss approach to a cross-modal setting of image & LiDAR data and also to show Zero-shot transfer in a visual localization setting. We conduct extensive analyses on standard autonomous driving datasets such as KITTI and KITTI-360 datasets. Our method outperforms state-of-the-art recall@1 accuracy on the KITTI-360 dataset by 22.4%, using only perspective images, in contrast to the state-of-the-art approach, which utilizes the more informative fisheye images. Additionally, this superior performance is achieved without resorting to complex architectures. Moreover, we demonstrate the zero-shot capabilities of our model and we beat SOTA by 8% without even training on it. Furthermore, we establish the first benchmark for cross-modal localization on the KITTI dataset.
Estimation of Appearance and Occupancy Information in Birds Eye View from Surround Monocular Images
Nov 08, 2022Autonomous driving requires efficient reasoning about the location and appearance of the different agents in the scene, which aids in downstream tasks such as object detection, object tracking, and path planning. The past few years have witnessed a surge in approaches that combine the different taskbased modules of the classic self-driving stack into an End-toEnd(E2E) trainable learning system. These approaches replace perception, prediction, and sensor fusion modules with a single contiguous module with shared latent space embedding, from which one extracts a human-interpretable representation of the scene. One of the most popular representations is the Birds-eye View (BEV), which expresses the location of different traffic participants in the ego vehicle frame from a top-down view. However, a BEV does not capture the chromatic appearance information of the participants. To overcome this limitation, we propose a novel representation that captures various traffic participants appearance and occupancy information from an array of monocular cameras covering 360 deg field of view (FOV). We use a learned image embedding of all camera images to generate a BEV of the scene at any instant that captures both appearance and occupancy of the scene, which can aid in downstream tasks such as object tracking and executing language-based commands. We test the efficacy of our approach on synthetic dataset generated from CARLA. The code, data set, and results can be found at https://rebrand.ly/APP OCC-results.
Bridging Sim2Real Gap Using Image Gradients for the Task of End-to-End Autonomous Driving
May 16, 2022
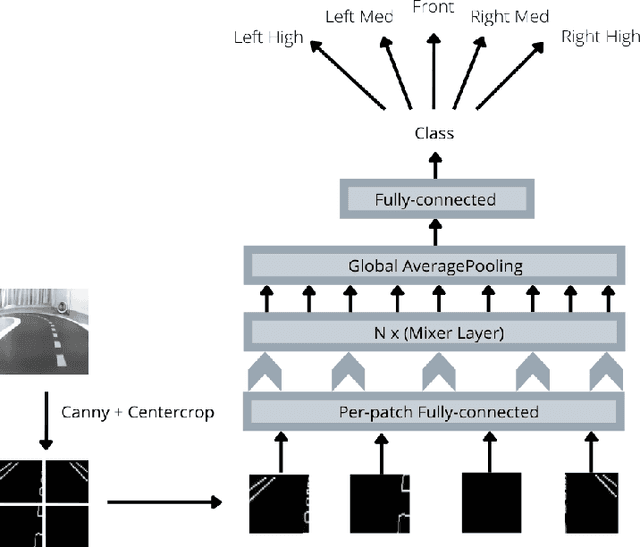

We present the first prize solution to NeurIPS 2021 - AWS Deepracer Challenge. In this competition, the task was to train a reinforcement learning agent (i.e. an autonomous car), that learns to drive by interacting with its environment, a simulated track, by taking an action in a given state to maximize the expected reward. This model was then tested on a real-world track with a miniature AWS Deepracer car. Our goal is to train a model that can complete a lap as fast as possible without going off the track. The Deepracer challenge is a part of a series of embodied intelligence competitions in the field of autonomous vehicles, called The AI Driving Olympics (AI-DO). The overall objective of the AI-DO is to provide accessible mechanisms for benchmarking progress in autonomy applied to the task of autonomous driving. The tricky section of this challenge was the sim2real transfer of the learned skills. To reduce the domain gap in the observation space we did a canny edge detection in addition to cropping out of the unnecessary background information. We modeled the problem as a behavioral cloning task and used MLP-MIXER to optimize for runtime. We made sure our model was capable of handling control noise by careful filtration of the training data and that gave us a robust model capable of completing the track even when 50% of the commands were randomly changed. The overall runtime of the model was only 2-3ms on a modern CPU.
RoRD: Rotation-Robust Descriptors and Orthographic Views for Local Feature Matching
Mar 15, 2021


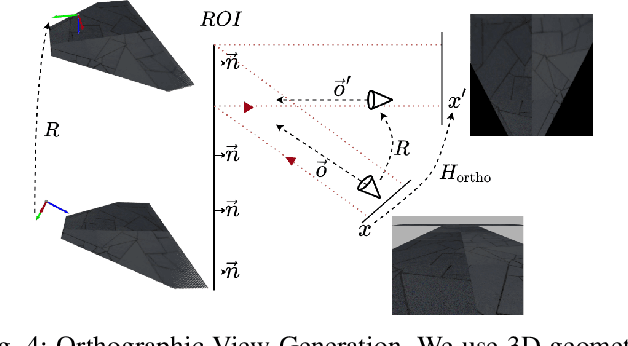
The use of local detectors and descriptors in typical computer vision pipelines work well until variations in viewpoint and appearance change become extreme. Past research in this area has typically focused on one of two approaches to this challenge: the use of projections into spaces more suitable for feature matching under extreme viewpoint changes, and attempting to learn features that are inherently more robust to viewpoint change. In this paper, we present a novel framework that combines learning of invariant descriptors through data augmentation and orthographic viewpoint projection. We propose rotation-robust local descriptors, learnt through training data augmentation based on rotation homographies, and a correspondence ensemble technique that combines vanilla feature correspondences with those obtained through rotation-robust features. Using a range of benchmark datasets as well as contributing a new bespoke dataset for this research domain, we evaluate the effectiveness of the proposed approach on key tasks including pose estimation and visual place recognition. Our system outperforms a range of baseline and state-of-the-art techniques, including enabling higher levels of place recognition precision across opposing place viewpoints and achieves practically-useful performance levels even under extreme viewpoint changes.
Early Bird: Loop Closures from Opposing Viewpoints for Perceptually-Aliased Indoor Environments
Oct 03, 2020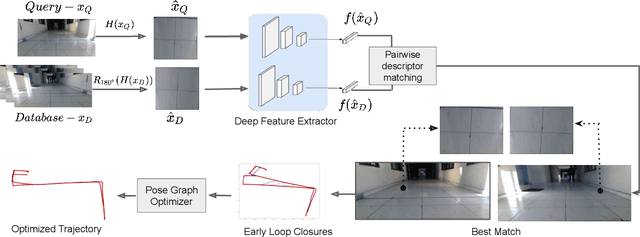


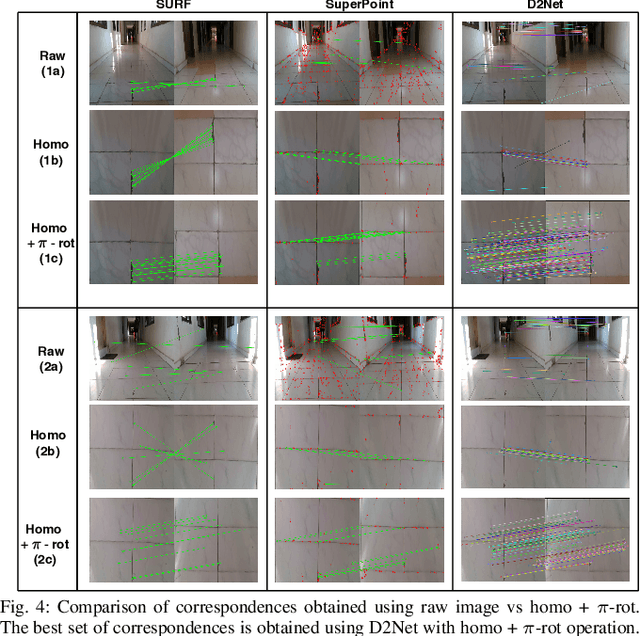
Significant advances have been made recently in Visual Place Recognition (VPR), feature correspondence, and localization due to the proliferation of deep-learning-based methods. However, existing approaches tend to address, partially or fully, only one of two key challenges: viewpoint change and perceptual aliasing. In this paper, we present novel research that simultaneously addresses both challenges by combining deep-learned features with geometric transformations based on reasonable domain assumptions about navigation on a ground-plane, whilst also removing the requirement for specialized hardware setup (e.g. lighting, downwards facing cameras). In particular, our integration of VPR with SLAM by leveraging the robustness of deep-learned features and our homography-based extreme viewpoint invariance significantly boosts the performance of VPR, feature correspondence, and pose graph submodules of the SLAM pipeline. For the first time, we demonstrate a localization system capable of state-of-the-art performance despite perceptual aliasing and extreme 180-degree-rotated viewpoint change in a range of real-world and simulated experiments. Our system is able to achieve early loop closures that prevent significant drifts in SLAM trajectories. We also compare extensively several deep architectures for VPR and descriptor matching. We also show that superior place recognition and descriptor matching across opposite views results in a similar performance gain in back-end pose graph optimization.
Topological Mapping for Manhattan-like Repetitive Environments
Mar 10, 2020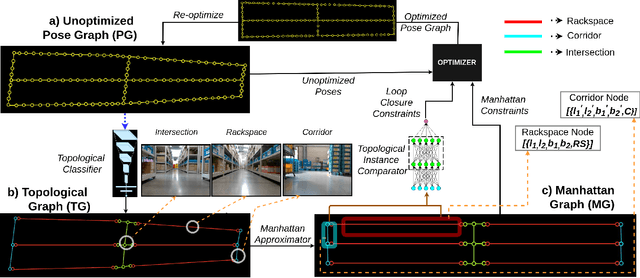

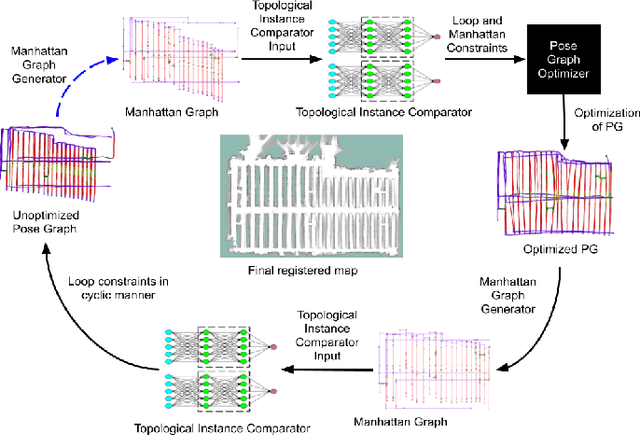
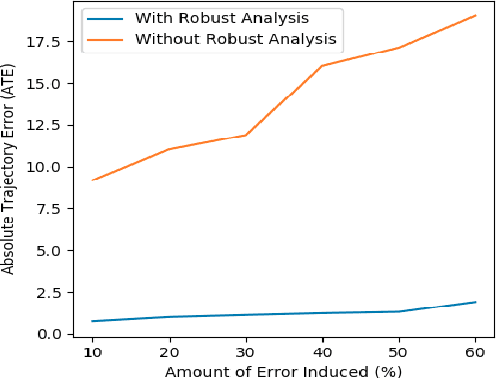
We showcase a topological mapping framework for a challenging indoor warehouse setting. At the most abstract level, the warehouse is represented as a Topological Graph where the nodes of the graph represent a particular warehouse topological construct (e.g. rackspace, corridor) and the edges denote the existence of a path between two neighbouring nodes or topologies. At the intermediate level, the map is represented as a Manhattan Graph where the nodes and edges are characterized by Manhattan properties and as a Pose Graph at the lower-most level of detail. The topological constructs are learned via a Deep Convolutional Network while the relational properties between topological instances are learnt via a Siamese-style Neural Network. In the paper, we show that maintaining abstractions such as Topological Graph and Manhattan Graph help in recovering an accurate Pose Graph starting from a highly erroneous and unoptimized Pose Graph. We show how this is achieved by embedding topological and Manhattan relations as well as Manhattan Graph aided loop closure relations as constraints in the backend Pose Graph optimization framework. The recovery of near ground-truth Pose Graph on real-world indoor warehouse scenes vindicate the efficacy of the proposed framework.