 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of Appearance and Occupancy Information in Birds Eye View from Surround Monocular Images
Nov 08, 2022Autonomous driving requires efficient reasoning about the location and appearance of the different agents in the scene, which aids in downstream tasks such as object detection, object tracking, and path planning. The past few years have witnessed a surge in approaches that combine the different taskbased modules of the classic self-driving stack into an End-toEnd(E2E) trainable learning system. These approaches replace perception, prediction, and sensor fusion modules with a single contiguous module with shared latent space embedding, from which one extracts a human-interpretable representation of the scene. One of the most popular representations is the Birds-eye View (BEV), which expresses the location of different traffic participants in the ego vehicle frame from a top-down view. However, a BEV does not capture the chromatic appearance information of the participants. To overcome this limitation, we propose a novel representation that captures various traffic participants appearance and occupancy information from an array of monocular cameras covering 360 deg field of view (FOV). We use a learned image embedding of all camera images to generate a BEV of the scene at any instant that captures both appearance and occupancy of the scene, which can aid in downstream tasks such as object tracking and executing language-based commands. We test the efficacy of our approach on synthetic dataset generated from CARLA. The code, data set, and results can be found at https://rebrand.ly/APP OCC-results.
NMR: Neural Manifold Representation for Autonomous Driving
May 11, 2022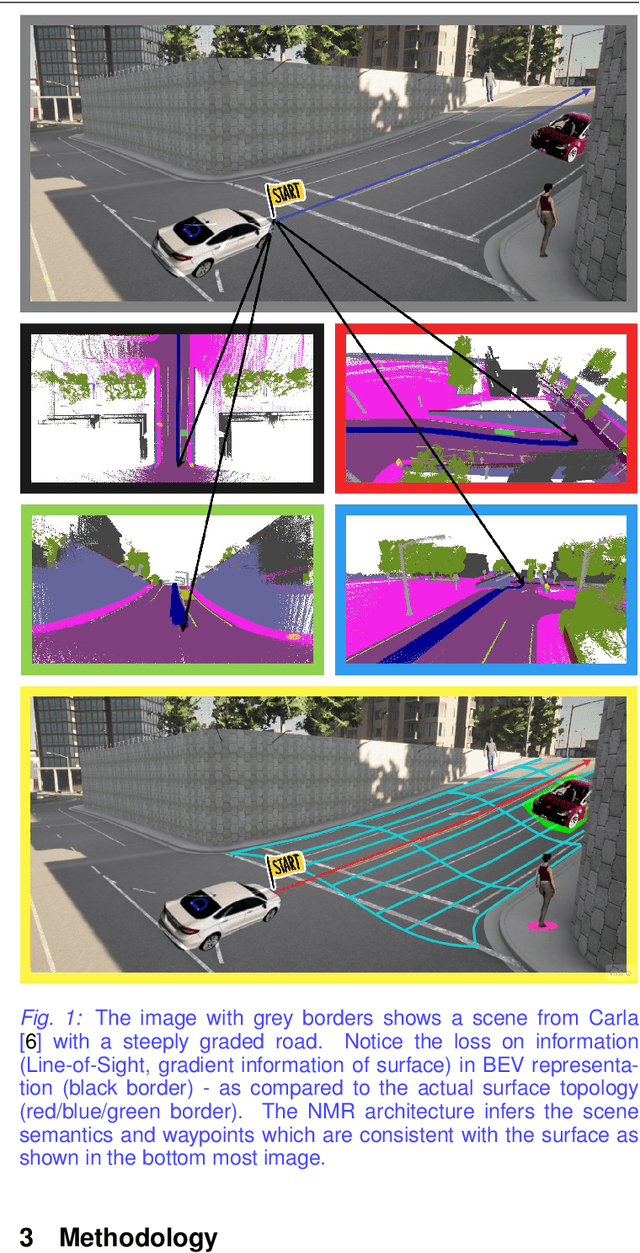
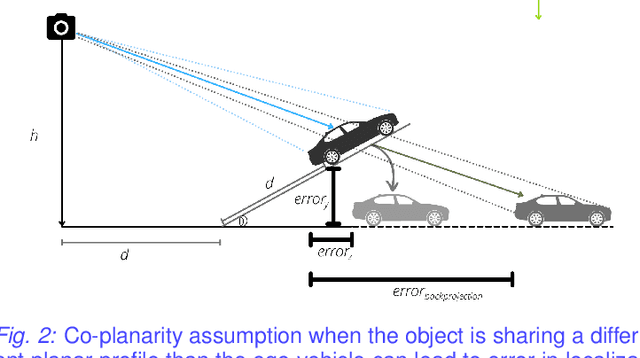
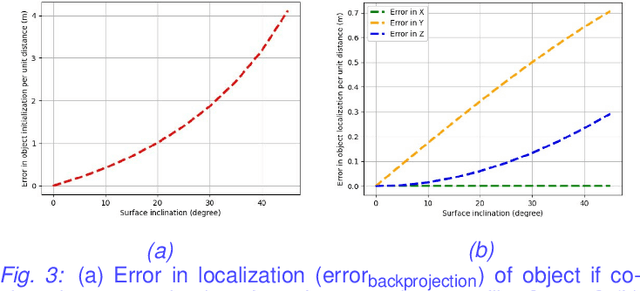
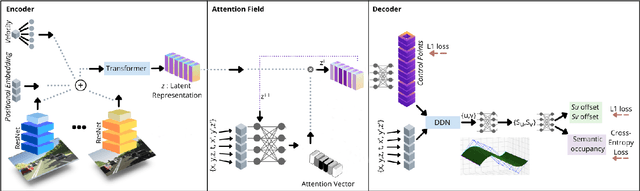
Autonomous driving requires efficient reasoning about the Spatio-temporal nature of the semantics of the scene. Recent approaches have successfully amalgamated the traditional modular architecture of an autonomous driving stack comprising perception, prediction, and planning in an end-to-end trainable system. Such a system calls for a shared latent space embedding with interpretable intermediate trainable projected representation. One such successfully deployed representation is the Bird's-Eye View(BEV) representation of the scene in ego-frame. However, a fundamental assumption for an undistorted BEV is the local coplanarity of the world around the ego-vehicle. This assumption is highly restrictive, as roads, in general, do have gradients. The resulting distortions make path planning inefficient and incorrect. To overcome this limitation, we propose Neural Manifold Representation (NMR), a representation for the task of autonomous driving that learns to infer semantics and predict way-points on a manifold over a finite horizon, centered on the ego-vehicle. We do this using an iterative attention mechanism applied on a latent high dimensional embedding of surround monocular images and partial ego-vehicle state. This representation helps generate motion and behavior plans consistent with and cognizant of the surface geometry. We propose a sampling algorithm based on edge-adaptive coverage loss of BEV occupancy grid and associated guidance flow field to generate the surface manifold while incurring minimal computational overhead. We aim to test the efficacy of our approach on CARLA and SYNTHIA-SF.