 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Social Motion Latent Space and Human Awareness for Effective Robot Navigation in Crowded Environments
Oct 11, 2023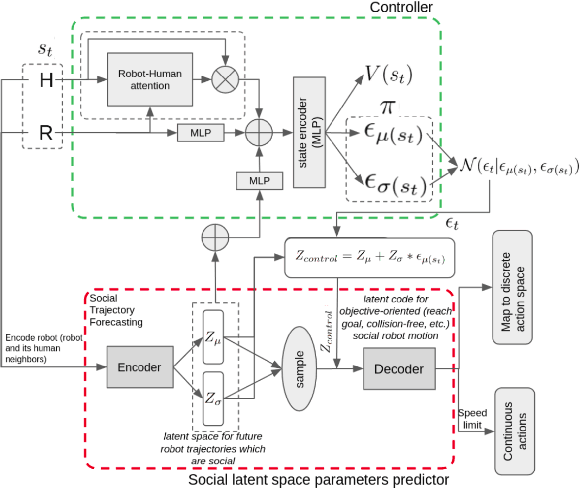
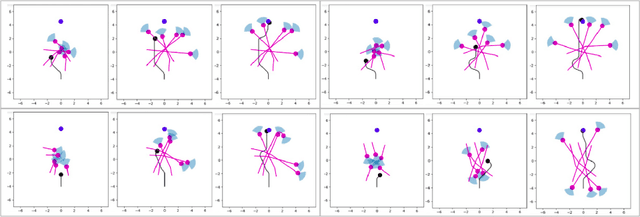
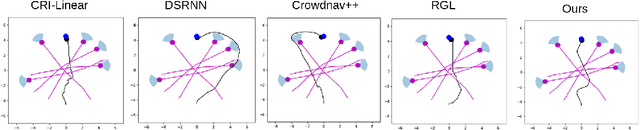
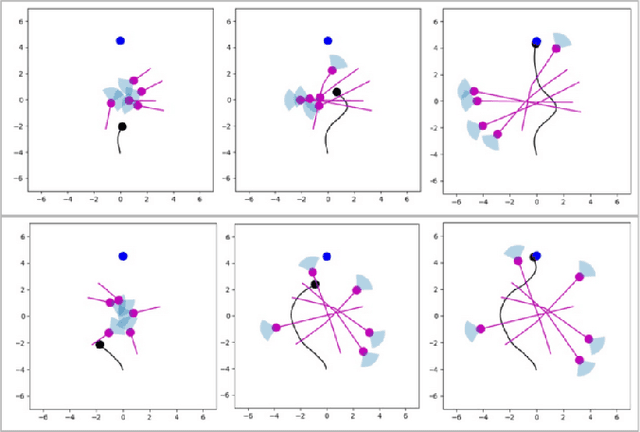
This work proposes a novel approach to social robot navigation by learning to generate robot controls from a social motion latent space. By leveraging this social motion latent space, the proposed method achieves significant improvements in social navigation metrics such as success rate, navigation time, and trajectory length while producing smoother (less jerk and angular deviations) and more anticipatory trajectories. The superiority of the proposed method is demonstrated through comparison with baseline models in various scenarios. Additionally, the concept of humans' awareness towards the robot is introduced into the social robot navigation framework, showing that incorporating human awareness leads to shorter and smoother trajectories owing to humans' ability to positively interact with the robot.
RoRD: Rotation-Robust Descriptors and Orthographic Views for Local Feature Matching
Mar 15, 2021


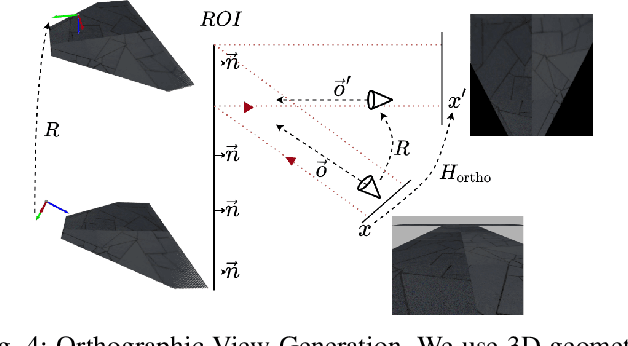
The use of local detectors and descriptors in typical computer vision pipelines work well until variations in viewpoint and appearance change become extreme. Past research in this area has typically focused on one of two approaches to this challenge: the use of projections into spaces more suitable for feature matching under extreme viewpoint changes, and attempting to learn features that are inherently more robust to viewpoint change. In this paper, we present a novel framework that combines learning of invariant descriptors through data augmentation and orthographic viewpoint projection. We propose rotation-robust local descriptors, learnt through training data augmentation based on rotation homographies, and a correspondence ensemble technique that combines vanilla feature correspondences with those obtained through rotation-robust features. Using a range of benchmark datasets as well as contributing a new bespoke dataset for this research domain, we evaluate the effectiveness of the proposed approach on key tasks including pose estimation and visual place recognition. Our system outperforms a range of baseline and state-of-the-art techniques, including enabling higher levels of place recognition precision across opposing place viewpoints and achieves practically-useful performance levels even under extreme viewpoint changes.
Early Bird: Loop Closures from Opposing Viewpoints for Perceptually-Aliased Indoor Environments
Oct 03, 2020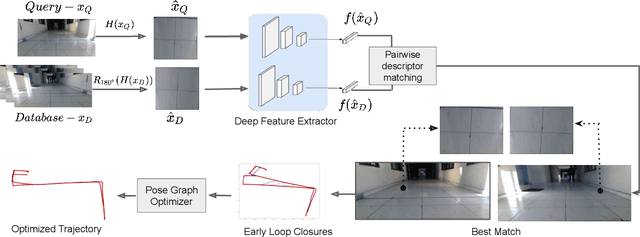


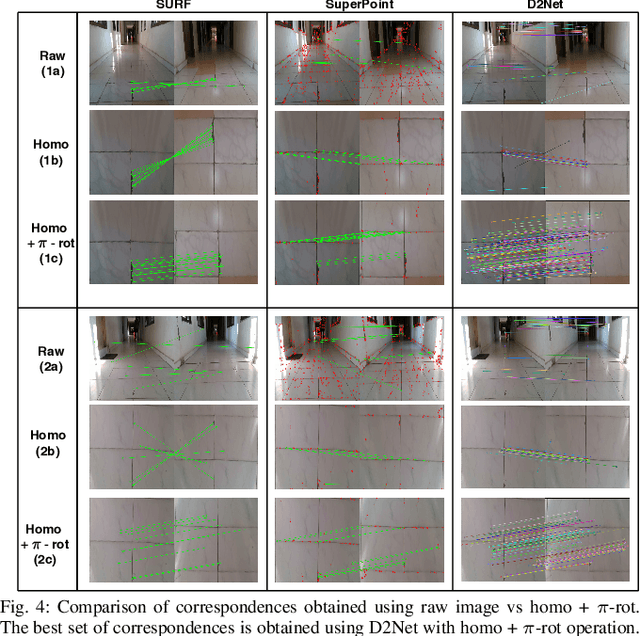
Significant advances have been made recently in Visual Place Recognition (VPR), feature correspondence, and localization due to the proliferation of deep-learning-based methods. However, existing approaches tend to address, partially or fully, only one of two key challenges: viewpoint change and perceptual aliasing. In this paper, we present novel research that simultaneously addresses both challenges by combining deep-learned features with geometric transformations based on reasonable domain assumptions about navigation on a ground-plane, whilst also removing the requirement for specialized hardware setup (e.g. lighting, downwards facing cameras). In particular, our integration of VPR with SLAM by leveraging the robustness of deep-learned features and our homography-based extreme viewpoint invariance significantly boosts the performance of VPR, feature correspondence, and pose graph submodules of the SLAM pipeline. For the first time, we demonstrate a localization system capable of state-of-the-art performance despite perceptual aliasing and extreme 180-degree-rotated viewpoint change in a range of real-world and simulated experiments. Our system is able to achieve early loop closures that prevent significant drifts in SLAM trajectories. We also compare extensively several deep architectures for VPR and descriptor matching. We also show that superior place recognition and descriptor matching across opposite views results in a similar performance gain in back-end pose graph optimization.
Topological Mapping for Manhattan-like Repetitive Environments
Mar 10, 2020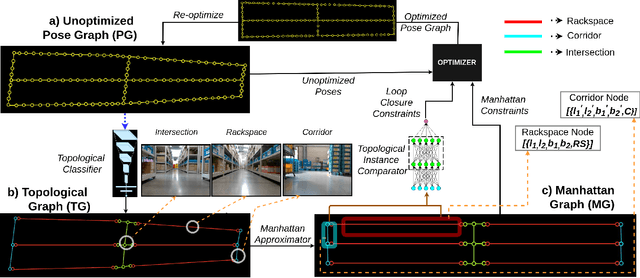

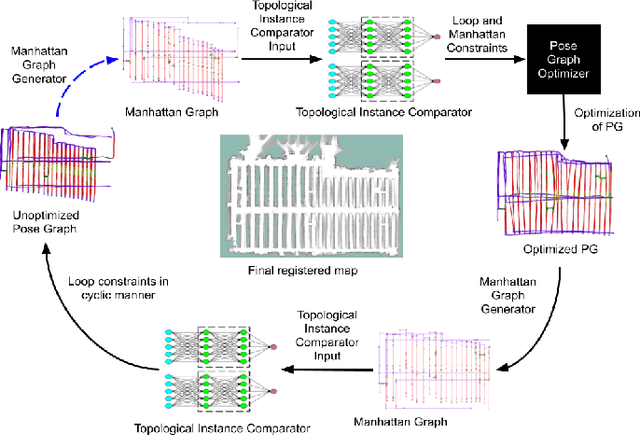
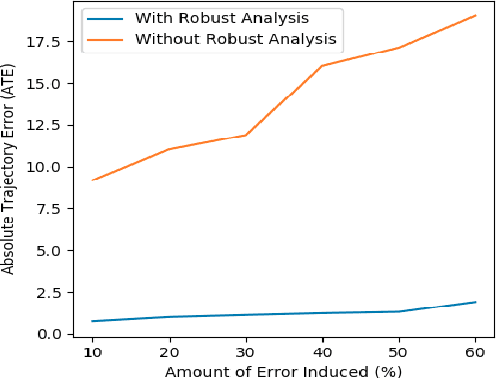
We showcase a topological mapping framework for a challenging indoor warehouse setting. At the most abstract level, the warehouse is represented as a Topological Graph where the nodes of the graph represent a particular warehouse topological construct (e.g. rackspace, corridor) and the edges denote the existence of a path between two neighbouring nodes or topologies. At the intermediate level, the map is represented as a Manhattan Graph where the nodes and edges are characterized by Manhattan properties and as a Pose Graph at the lower-most level of detail. The topological constructs are learned via a Deep Convolutional Network while the relational properties between topological instances are learnt via a Siamese-style Neural Network. In the paper, we show that maintaining abstractions such as Topological Graph and Manhattan Graph help in recovering an accurate Pose Graph starting from a highly erroneous and unoptimized Pose Graph. We show how this is achieved by embedding topological and Manhattan relations as well as Manhattan Graph aided loop closure relations as constraints in the backend Pose Graph optimization framework. The recovery of near ground-truth Pose Graph on real-world indoor warehouse scenes vindicate the efficacy of the proposed framework.