 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit Anything: Visual Place Recognition via Image Segment Retrieval
Sep 26, 2024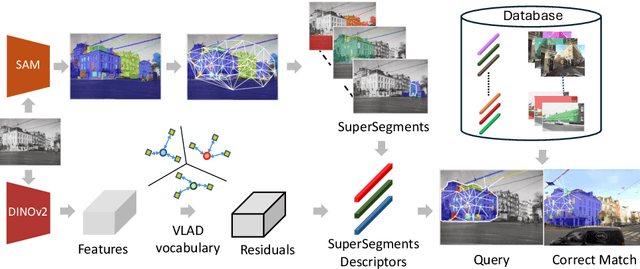
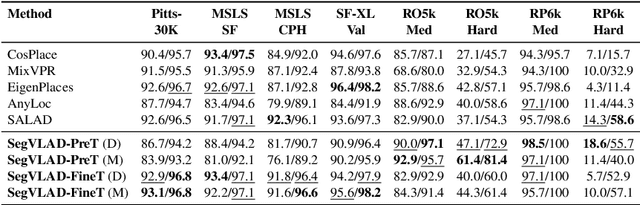

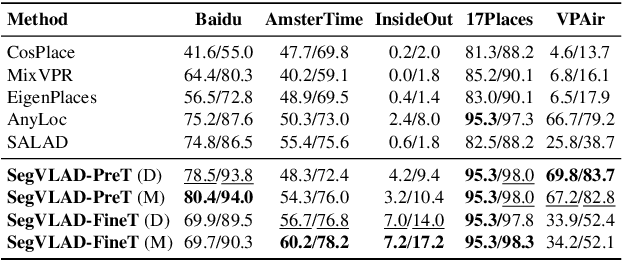
Accurately recognizing a revisited place is crucial for embodied agents to localize and navigate. This requires visual representations to be distinct, despite strong variations in camera viewpoint and scene appearance. Existing visual place recognition pipelines encode the "whole" image and search for matches. This poses a fundamental challenge in matching two images of the same place captured from different camera viewpoints: "the similarity of what overlaps can be dominated by the dissimilarity of what does not overlap". We address this by encoding and searching for "image segments" instead of the whole images. We propose to use open-set image segmentation to decompose an image into `meaningful' entities (i.e., things and stuff). This enables us to create a novel image representation as a collection of multiple overlapping subgraphs connecting a segment with its neighboring segments, dubbed SuperSegment. Furthermore, to efficiently encode these SuperSegments into compact vector representations, we propose a novel factorized representation of feature aggregation. We show that retrieving these partial representations leads to significantly higher recognition recall than the typical whole image based retrieval. Our segments-based approach, dubbed SegVLAD, sets a new state-of-the-art in place recognition on a diverse selection of benchmark datasets, while being applicable to both generic and task-specialized image encoders. Finally, we demonstrate the potential of our method to ``revisit anything'' by evaluating our method on an object instance retrieval task, which bridges the two disparate areas of research: visual place recognition and object-goal navigation, through their common aim of recognizing goal objects specific to a place. Source code: https://github.com/AnyLoc/Revisit-Anything.
LIP-Loc: LiDAR Image Pretraining for Cross-Modal Localization
Dec 27, 2023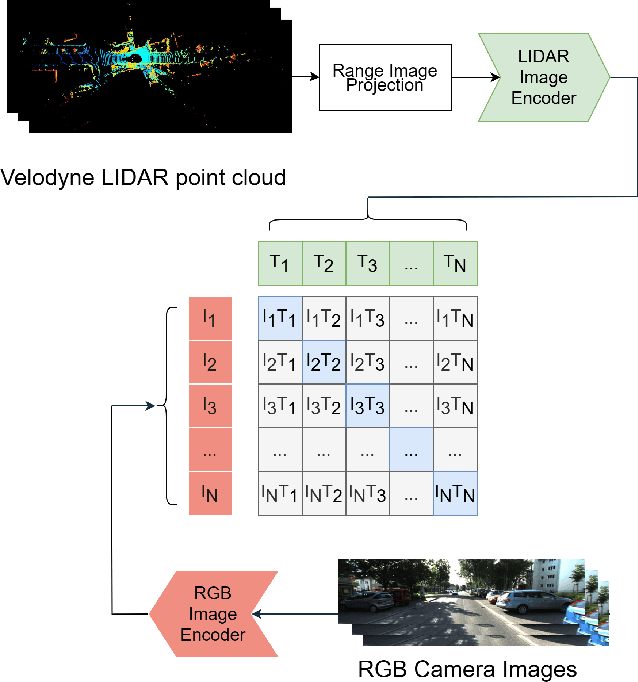
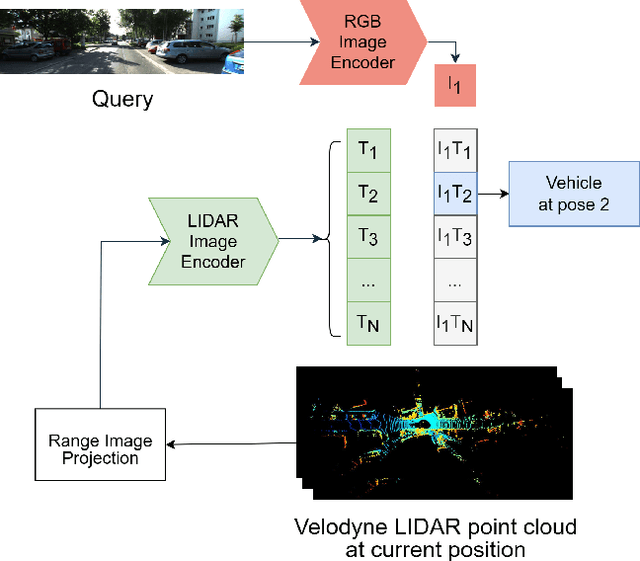
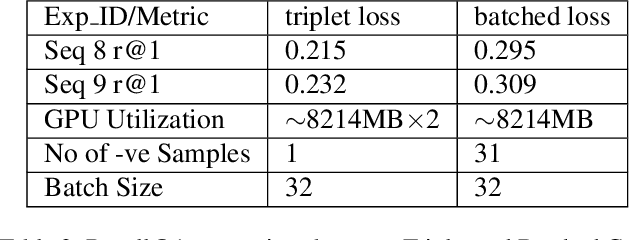
Global visual localization in LiDAR-maps, crucial for autonomous driving applications, remains largely unexplored due to the challenging issue of bridging the cross-modal heterogeneity gap. Popular multi-modal learning approach Contrastive Language-Image Pre-Training (CLIP) has popularized contrastive symmetric loss using batch construction technique by applying it to multi-modal domains of text and image. We apply this approach to the domains of 2D image and 3D LiDAR points on the task of cross-modal localization. Our method is explained as follows: A batch of N (image, LiDAR) pairs is constructed so as to predict what is the right match between N X N possible pairings across the batch by jointly training an image encoder and LiDAR encoder to learn a multi-modal embedding space. In this way, the cosine similarity between N positive pairings is maximized, whereas that between the remaining negative pairings is minimized. Finally, over the obtained similarity scores, a symmetric cross-entropy loss is optimized. To the best of our knowledge, this is the first work to apply batched loss approach to a cross-modal setting of image & LiDAR data and also to show Zero-shot transfer in a visual localization setting. We conduct extensive analyses on standard autonomous driving datasets such as KITTI and KITTI-360 datasets. Our method outperforms state-of-the-art recall@1 accuracy on the KITTI-360 dataset by 22.4%, using only perspective images, in contrast to the state-of-the-art approach, which utilizes the more informative fisheye images. Additionally, this superior performance is achieved without resorting to complex architectures. Moreover, we demonstrate the zero-shot capabilities of our model and we beat SOTA by 8% without even training on it. Furthermore, we establish the first benchmark for cross-modal localization on the KITTI dataset.
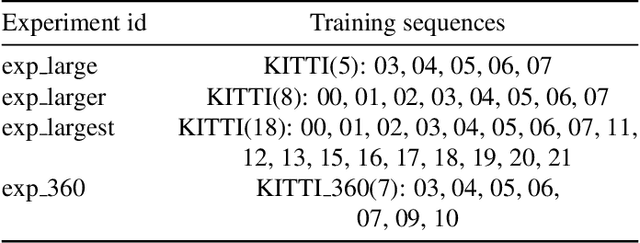
Topological Mapping for Manhattan-like Repetitive Environments
Mar 10, 2020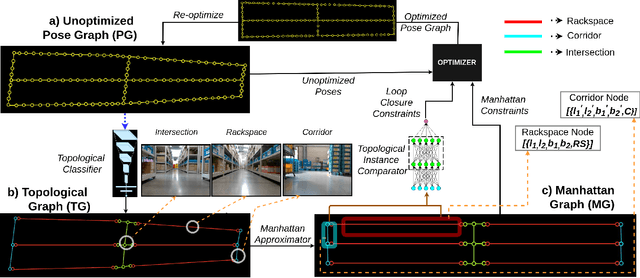

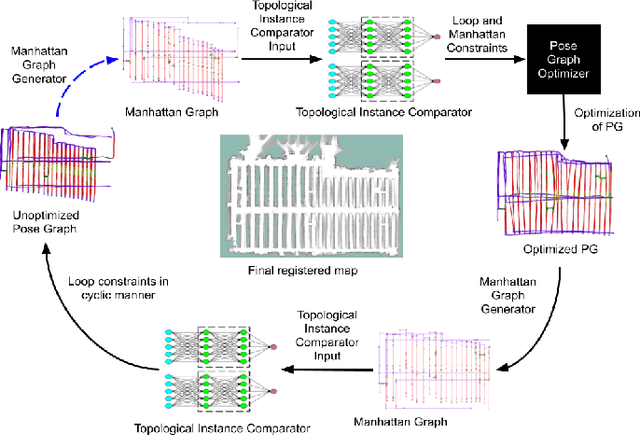
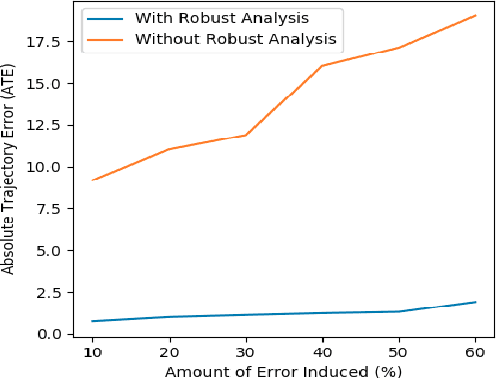
We showcase a topological mapping framework for a challenging indoor warehouse setting. At the most abstract level, the warehouse is represented as a Topological Graph where the nodes of the graph represent a particular warehouse topological construct (e.g. rackspace, corridor) and the edges denote the existence of a path between two neighbouring nodes or topologies. At the intermediate level, the map is represented as a Manhattan Graph where the nodes and edges are characterized by Manhattan properties and as a Pose Graph at the lower-most level of detail. The topological constructs are learned via a Deep Convolutional Network while the relational properties between topological instances are learnt via a Siamese-style Neural Network. In the paper, we show that maintaining abstractions such as Topological Graph and Manhattan Graph help in recovering an accurate Pose Graph starting from a highly erroneous and unoptimized Pose Graph. We show how this is achieved by embedding topological and Manhattan relations as well as Manhattan Graph aided loop closure relations as constraints in the backend Pose Graph optimization framework. The recovery of near ground-truth Pose Graph on real-world indoor warehouse scenes vindicate the efficacy of the proposed framework.