 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoRD: Rotation-Robust Descriptors and Orthographic Views for Local Feature Matching
Paper and Code



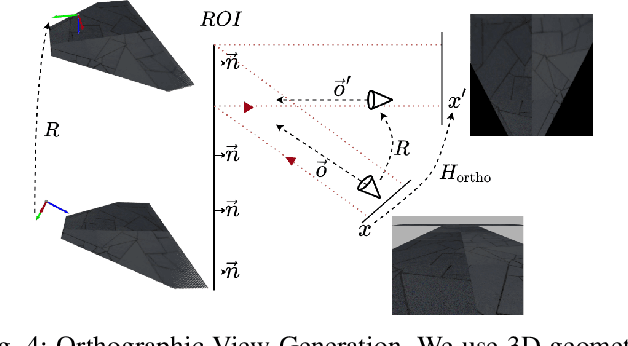
The use of local detectors and descriptors in typical computer vision pipelines work well until variations in viewpoint and appearance change become extreme. Past research in this area has typically focused on one of two approaches to this challenge: the use of projections into spaces more suitable for feature matching under extreme viewpoint changes, and attempting to learn features that are inherently more robust to viewpoint change. In this paper, we present a novel framework that combines learning of invariant descriptors through data augmentation and orthographic viewpoint projection. We propose rotation-robust local descriptors, learnt through training data augmentation based on rotation homographies, and a correspondence ensemble technique that combines vanilla feature correspondences with those obtained through rotation-robust features. Using a range of benchmark datasets as well as contributing a new bespoke dataset for this research domain, we evaluate the effectiveness of the proposed approach on key tasks including pose estimation and visual place recognition. Our system outperforms a range of baseline and state-of-the-art techniques, including enabling higher levels of place recognition precision across opposing place viewpoints and achieves practically-useful performance levels even under extreme viewpoint changes.