 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: A Generic Framework for Text-Aided Map Compression for Localization
Mar 04, 2026Mapping is crucial in robotics for localization and downstream decision-making. As robots are deployed in ever-broader settings, the maps they rely on continue to increase in size. However, storing these maps indefinitely (cold storage), transferring them across networks, or sending localization queries to cloud-hosted maps imposes prohibitive memory and bandwidth costs. We propose a text-enhanced compression framework that reduces both memory and bandwidth footprints while retaining high-fidelity localization. The key idea is to treat text as an alternative modality: one that can be losslessly compressed with large language models. We propose leveraging lightweight text descriptions combined with very small image feature vectors, which capture "complementary information" as a compact representation for the mapping task. Building on this, our novel technique, Similarity Space Replication (SSR), learns an adaptive image embedding in one shot that captures only the information "complementary" to the text descriptions. We validate our compression framework on multiple downstream localization tasks, including Visual Place Recognition as well as object-centric Monte Carlo localization in both indoor and outdoor settings. SSR achieves 2 times better compression than competing baselines on state-of-the-art datasets, including TokyoVal, Pittsburgh30k, Replica, and KITTI.
ViSIL: Unified Evaluation of Information Loss in Multimodal Video Captioning
Jan 14, 2026Multimodal video captioning condenses dense footage into a structured format of keyframes and natural language. By creating a cohesive multimodal summary, this approach anchors generative AI in rich semantic evidence and serves as a lightweight proxy for high-efficiency retrieval. However, traditional metrics like BLEU or ROUGE fail to quantify information coverage across disparate modalities, such as comparing a paragraph of text to a sequence of keyframes. To address this, we propose the Video Summary Information Loss (ViSIL) score, an information-theoretic framework that quantifies the video information not captured by a summary via vision-language model (VLM) inference. By measuring the information loss, ViSIL is a unified metric that enables direct comparison across multimodal summary formats despite their structural discrepancies. Our results demonstrate that ViSIL scores show a statistically significant correlation with both human and VLM performance on Video Question Answering (VQA) tasks. ViSIL also enables summary selection to optimize the trade-off between information loss and processing speed, establishing a Pareto-optimal frontier that outperforms text summaries by $7\%$ in VQA accuracy without increasing processing load.
VIBE: Video-to-Text Information Bottleneck Evaluation for TL;DR
May 23, 2025Many decision-making tasks, where both accuracy and efficiency matter, still require human supervision. For example, tasks like traffic officers reviewing hour-long dashcam footage or researchers screening conference videos can benefit from concise summaries that reduce cognitive load and save time. Yet current vision-language models (VLMs) often produce verbose, redundant outputs that hinder task performance. Existing video caption evaluation depends on costly human annotations and overlooks the summaries' utility in downstream tasks. We address these gaps with Video-to-text Information Bottleneck Evaluation (VIBE), an annotation-free method that scores VLM outputs using two metrics: grounding (how well the summary aligns with visual content) and utility (how informative it is for the task). VIBE selects from randomly sampled VLM outputs by ranking them according to the two scores to support effective human decision-making. Human studies on LearningPaper24, SUTD-TrafficQA, and LongVideoBench show that summaries selected by VIBE consistently improve performance-boosting task accuracy by up to 61.23% and reducing response time by 75.77% compared to naive VLM summaries or raw video.
Dense Dynamics-Aware Reward Synthesis: Integrating Prior Experience with Demonstrations
Dec 02, 2024



Many continuous control problems can be formulated as sparse-reward reinforcement learning (RL) tasks. In principle, online RL methods can automatically explore the state space to solve each new task. However, discovering sequences of actions that lead to a non-zero reward becomes exponentially more difficult as the task horizon increases. Manually shaping rewards can accelerate learning for a fixed task, but it is an arduous process that must be repeated for each new environment. We introduce a systematic reward-shaping framework that distills the information contained in 1) a task-agnostic prior data set and 2) a small number of task-specific expert demonstrations, and then uses these priors to synthesize dense dynamics-aware rewards for the given task. This supervision substantially accelerates learning in our experiments, and we provide analysis demonstrating how the approach can effectively guide online learning agents to faraway goals.
Any2Any: Incomplete Multimodal Retrieval with Conformal Prediction
Nov 25, 2024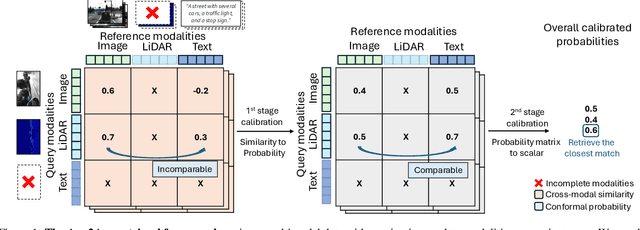
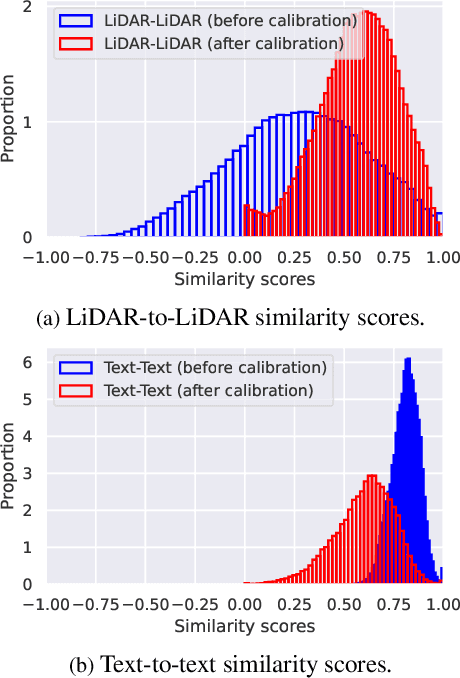
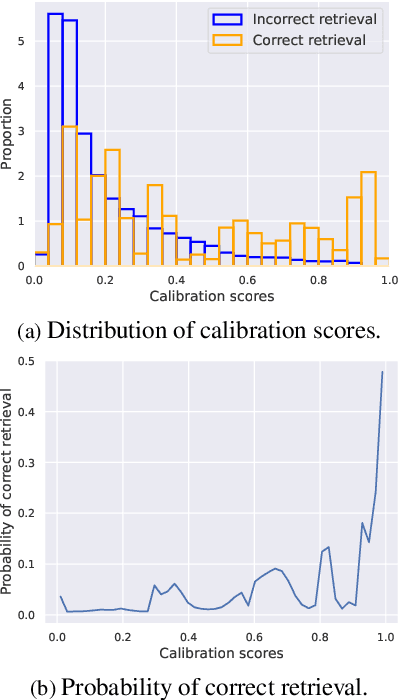
Autonomous agents perceive and interpret their surroundings by integrating multimodal inputs, such as vision, audio, and LiDAR. These perceptual modalities support retrieval tasks, such as place recognition in robotics. However, current multimodal retrieval systems encounter difficulties when parts of the data are missing due to sensor failures or inaccessibility, such as silent videos or LiDAR scans lacking RGB information. We propose Any2Any-a novel retrieval framework that addresses scenarios where both query and reference instances have incomplete modalities. Unlike previous methods limited to the imputation of two modalities, Any2Any handles any number of modalities without training generative models. It calculates pairwise similarities with cross-modal encoders and employs a two-stage calibration process with conformal prediction to align the similarities. Any2Any enables effective retrieval across multimodal datasets, e.g., text-LiDAR and text-time series. It achieves a Recall@5 of 35% on the KITTI dataset, which is on par with baseline models with complete modalities.
CSA: Data-efficient Mapping of Unimodal Features to Multimodal Features
Oct 10, 2024
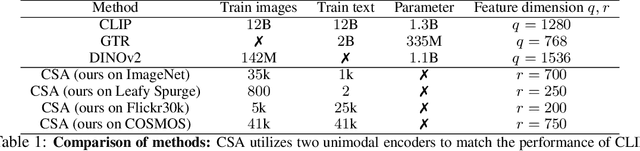
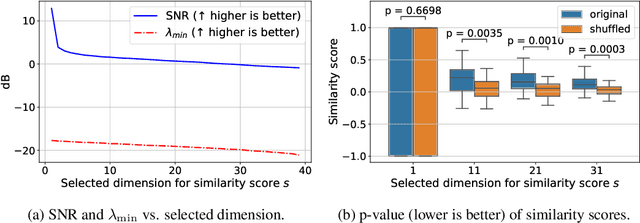
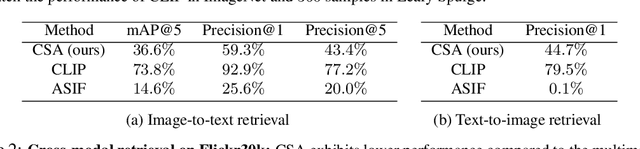
Multimodal encoders like CLIP excel in tasks such as zero-shot image classification and cross-modal retrieval. However, they require excessive training data. We propose canonical similarity analysis (CSA), which uses two unimodal encoders to replicate multimodal encoders using limited data. CSA maps unimodal features into a multimodal space, using a new similarity score to retain only the multimodal information. CSA only involves the inference of unimodal encoders and a cubic-complexity matrix decomposition, eliminating the need for extensive GPU-based model training. Experiments show that CSA outperforms CLIP while requiring $300,000\times$ fewer multimodal data pairs and $6\times$ fewer unimodal data for ImageNet classification and misinformative news captions detection. CSA surpasses the state-of-the-art method to map unimodal features to multimodal features. We also demonstrate the ability of CSA with modalities beyond image and text, paving the way for future modality pairs with limited paired multimodal data but abundant unpaired unimodal data, such as lidar and text.
Exploiting Distribution Constraints for Scalable and Efficient Image Retrieval
Oct 09, 2024



Image retrieval is crucial in robotics and computer vision, with downstream applications in robot place recognition and vision-based product recommendations. Modern retrieval systems face two key challenges: scalability and efficiency. State-of-the-art image retrieval systems train specific neural networks for each dataset, an approach that lacks scalability. Furthermore, since retrieval speed is directly proportional to embedding size, existing systems that use large embeddings lack efficiency. To tackle scalability, recent works propose using off-the-shelf foundation models. However, these models, though applicable across datasets, fall short in achieving performance comparable to that of dataset-specific models. Our key observation is that, while foundation models capture necessary subtleties for effective retrieval, the underlying distribution of their embedding space can negatively impact cosine similarity searches. We introduce Autoencoders with Strong Variance Constraints (AE-SVC), which, when used for projection, significantly improves the performance of foundation models. We provide an in-depth theoretical analysis of AE-SVC. Addressing efficiency, we introduce Single-shot Similarity Space Distillation ((SS)$_2$D), a novel approach to learn embeddings with adaptive sizes that offers a better trade-off between size and performance. We conducted extensive experiments on four retrieval datasets, including Stanford Online Products (SoP) and Pittsburgh30k, using four different off-the-shelf foundation models, including DinoV2 and CLIP. AE-SVC demonstrates up to a $16\%$ improvement in retrieval performance, while (SS)$_2$D shows a further $10\%$ improvement for smaller embedding sizes.
PEERNet: An End-to-End Profiling Tool for Real-Time Networked Robotic Systems
Sep 09, 2024Networked robotic systems balance compute, power, and latency constraints in applications such as self-driving vehicles, drone swarms, and teleoperated surgery. A core problem in this domain is deciding when to offload a computationally expensive task to the cloud, a remote server, at the cost of communication latency. Task offloading algorithms often rely on precise knowledge of system-specific performance metrics, such as sensor data rates, network bandwidth, and machine learning model latency. While these metrics can be modeled during system design, uncertainties in connection quality, server load, and hardware conditions introduce real-time performance variations, hindering overall performance. We introduce PEERNet, an end-to-end and real-time profiling tool for cloud robotics. PEERNet enables performance monitoring on heterogeneous hardware through targeted yet adaptive profiling of system components such as sensors, networks, deep-learning pipelines, and devices. We showcase PEERNet's capabilities through networked robotics tasks, such as image-based teleoperation of a Franka Emika Panda arm and querying vision language models using an Nvidia Jetson Orin. PEERNet reveals non-intuitive behavior in robotic systems, such as asymmetric network transmission and bimodal language model output. Our evaluation underscores the effectiveness and importance of benchmarking in networked robotics, demonstrating PEERNet's adaptability. Our code is open-source and available at github.com/UTAustin-SwarmLab/PEERNet.
Online Foundation Model Selection in Robotics
Feb 13, 2024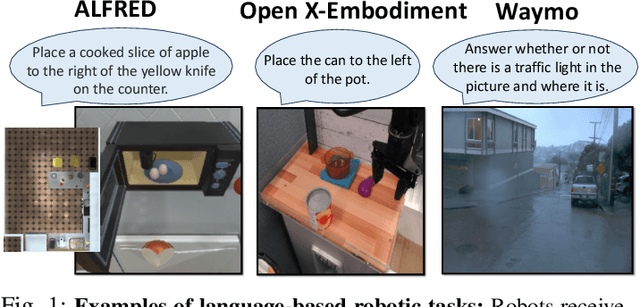
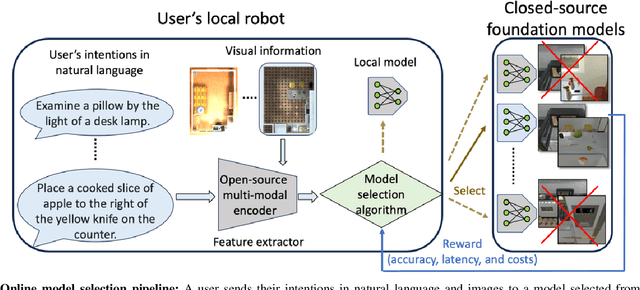
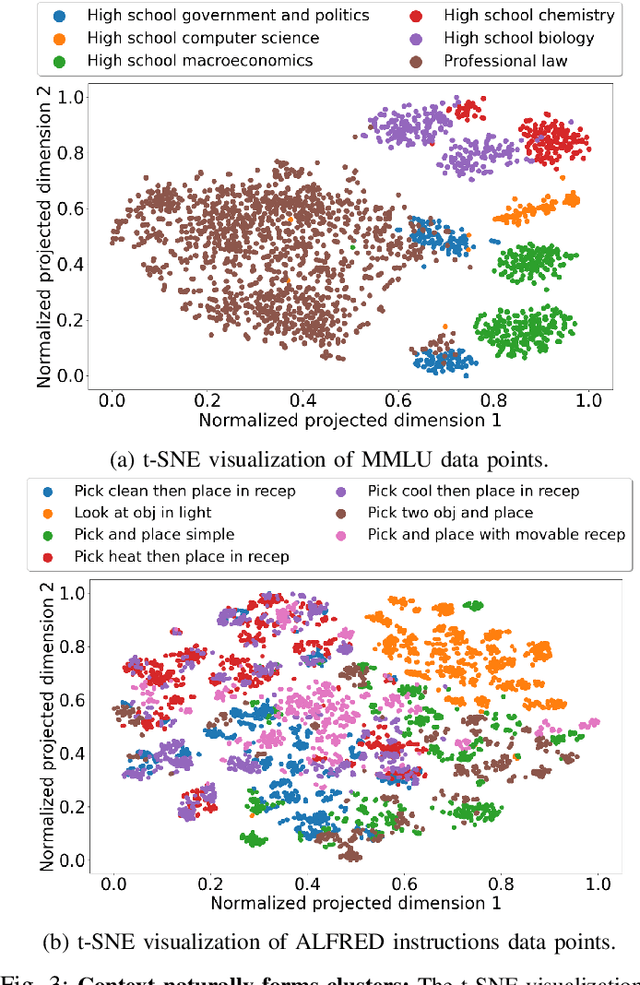
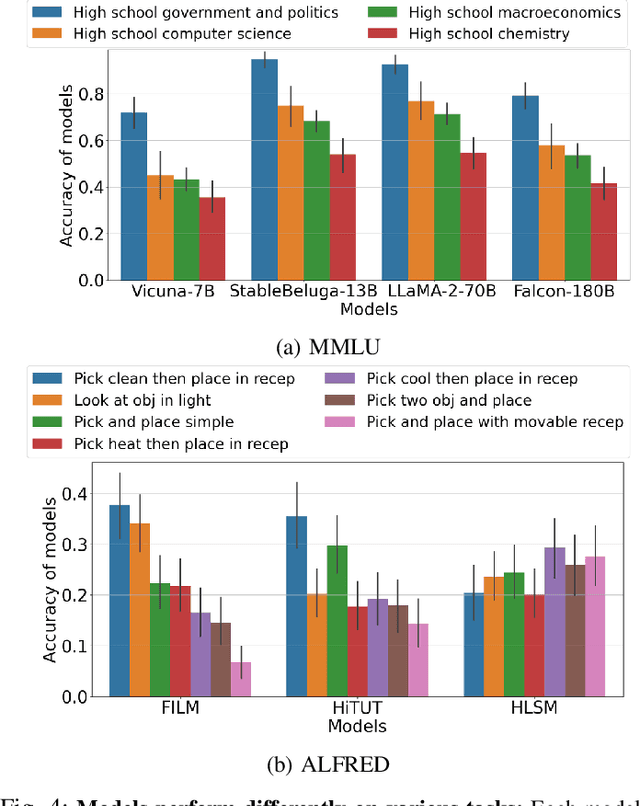
Foundation models have recently expanded into robotics after excelling in computer vision and natural language processing. The models are accessible in two ways: open-source or paid, closed-source options. Users with access to both face a problem when deciding between effective yet costly closed-source models and free but less powerful open-source alternatives. We call it the model selection problem. Existing supervised-learning methods are impractical due to the high cost of collecting extensive training data from closed-source models. Hence, we focus on the online learning setting where algorithms learn while collecting data, eliminating the need for large pre-collected datasets. We thus formulate a user-centric online model selection problem and propose a novel solution that combines an open-source encoder to output context and an online learning algorithm that processes this context. The encoder distills vast data distributions into low-dimensional features, i.e., the context, without additional training. The online learning algorithm aims to maximize a composite reward that includes model performance, execution time, and costs based on the context extracted from the data. It results in an improved trade-off between selecting open-source and closed-source models compared to non-contextual methods, as validated by our theoretical analysis. Experiments across language-based robotic tasks such as Waymo Open Dataset, ALFRED, and Open X-Embodiment demonstrate real-world applications of the solution. The results show that the solution significantly improves the task success rate by up to 14%.
Task-aware Distributed Source Coding under Dynamic Bandwidth
May 24, 2023Efficient compression of correlated data is essential to minimize communication overload in multi-sensor networks. In such networks, each sensor independently compresses the data and transmits them to a central node due to limited communication bandwidth. A decoder at the central node decompresses and passes the data to a pre-trained machine learning-based task to generate the final output. Thus, it is important to compress the features that are relevant to the task. Additionally, the final performance depends heavily on the total available bandwidth. In practice, it is common to encounter varying availability in bandwidth, and higher bandwidth results in better performance of the task. We design a novel distributed compression framework composed of independent encoders and a joint decoder, which we call neural distributed principal component analysis (NDPCA). NDPCA flexibly compresses data from multiple sources to any available bandwidth with a single model, reducing computing and storage overhead. NDPCA achieves this by learning low-rank task representations and efficiently distributing bandwidth among sensors, thus providing a graceful trade-off between performance and bandwidth. Experiments show that NDPCA improves the success rate of multi-view robotic arm manipulation by 9% and the accuracy of object detection tasks on satellite imagery by 14% compared to an autoencoder with uniform bandwidth allocation.