 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSA: Data-efficient Mapping of Unimodal Features to Multimodal Features
Paper and Code
Oct 10, 2024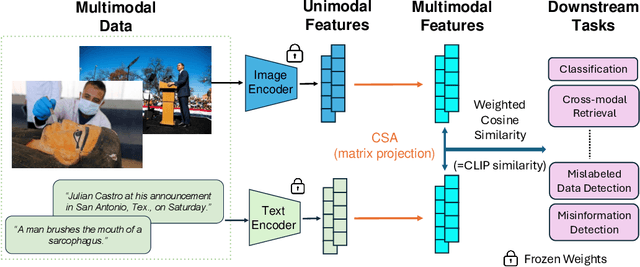
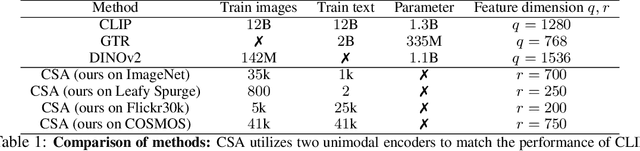
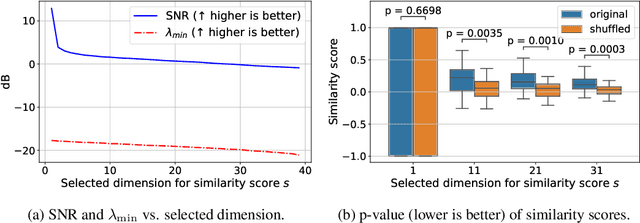
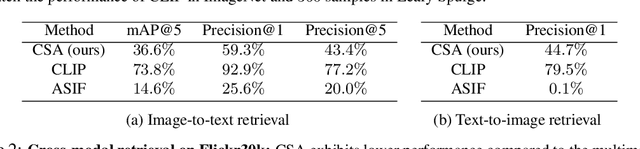
Multimodal encoders like CLIP excel in tasks such as zero-shot image classification and cross-modal retrieval. However, they require excessive training data. We propose canonical similarity analysis (CSA), which uses two unimodal encoders to replicate multimodal encoders using limited data. CSA maps unimodal features into a multimodal space, using a new similarity score to retain only the multimodal information. CSA only involves the inference of unimodal encoders and a cubic-complexity matrix decomposition, eliminating the need for extensive GPU-based model training. Experiments show that CSA outperforms CLIP while requiring $300,000\times$ fewer multimodal data pairs and $6\times$ fewer unimodal data for ImageNet classification and misinformative news captions detection. CSA surpasses the state-of-the-art method to map unimodal features to multimodal features. We also demonstrate the ability of CSA with modalities beyond image and text, paving the way for future modality pairs with limited paired multimodal data but abundant unpaired unimodal data, such as lidar and text.