 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Foundation Model Selection in Robotics
Feb 13, 2024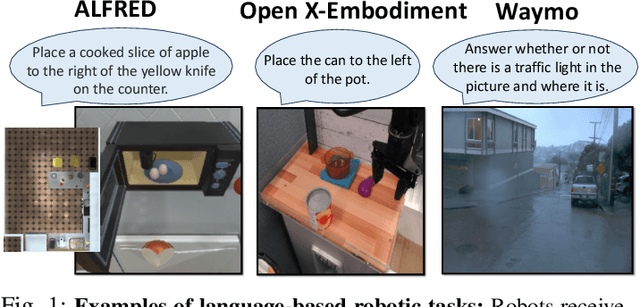
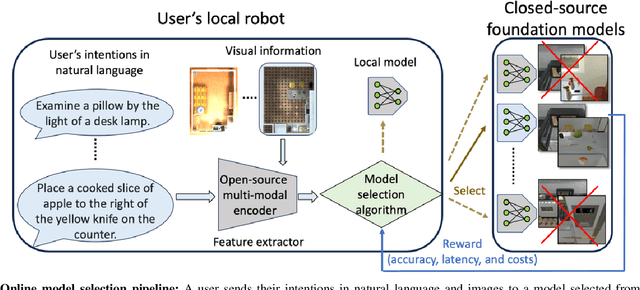
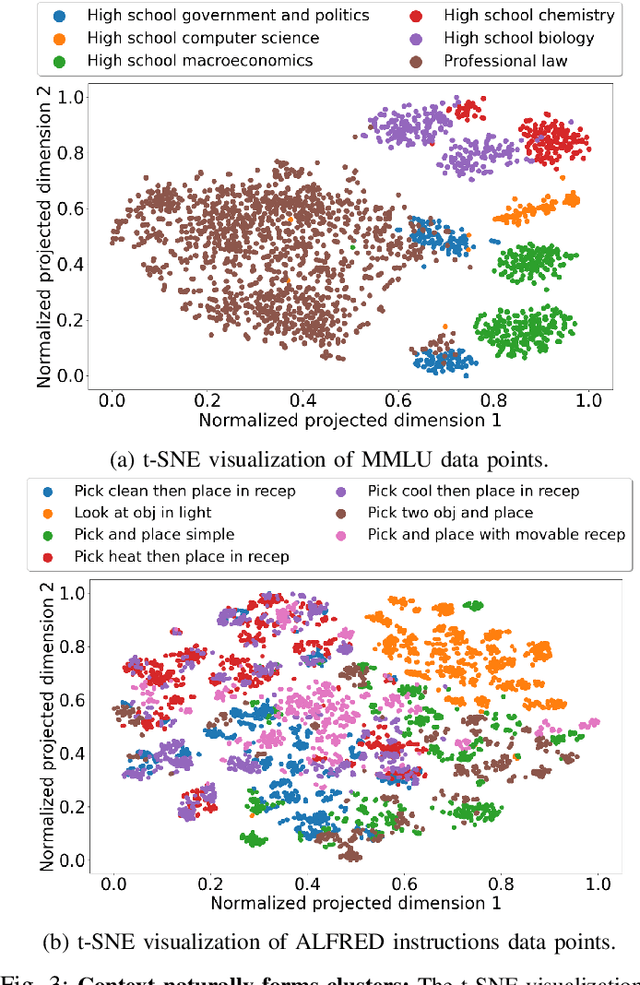
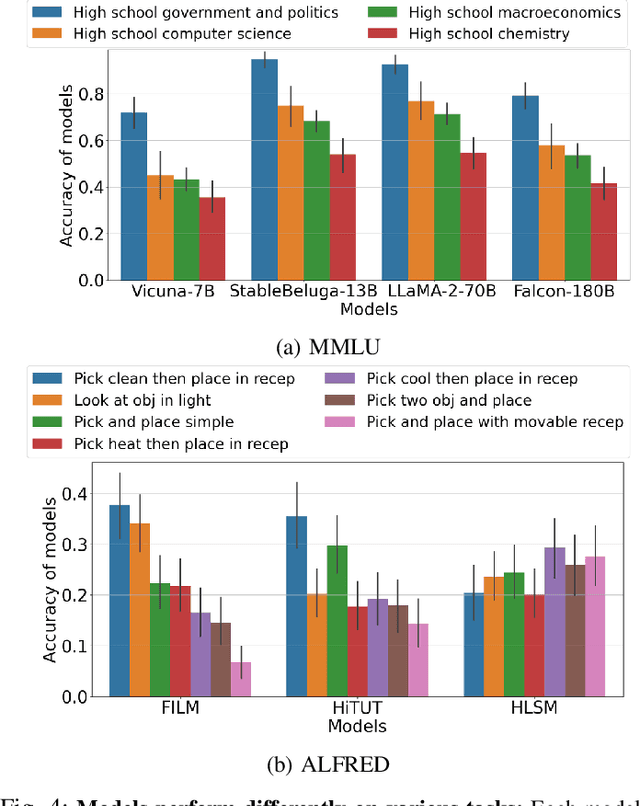
Foundation models have recently expanded into robotics after excelling in computer vision and natural language processing. The models are accessible in two ways: open-source or paid, closed-source options. Users with access to both face a problem when deciding between effective yet costly closed-source models and free but less powerful open-source alternatives. We call it the model selection problem. Existing supervised-learning methods are impractical due to the high cost of collecting extensive training data from closed-source models. Hence, we focus on the online learning setting where algorithms learn while collecting data, eliminating the need for large pre-collected datasets. We thus formulate a user-centric online model selection problem and propose a novel solution that combines an open-source encoder to output context and an online learning algorithm that processes this context. The encoder distills vast data distributions into low-dimensional features, i.e., the context, without additional training. The online learning algorithm aims to maximize a composite reward that includes model performance, execution time, and costs based on the context extracted from the data. It results in an improved trade-off between selecting open-source and closed-source models compared to non-contextual methods, as validated by our theoretical analysis. Experiments across language-based robotic tasks such as Waymo Open Dataset, ALFRED, and Open X-Embodiment demonstrate real-world applications of the solution. The results show that the solution significantly improves the task success rate by up to 14%.