 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViSIL: Unified Evaluation of Information Loss in Multimodal Video Captioning
Jan 14, 2026Multimodal video captioning condenses dense footage into a structured format of keyframes and natural language. By creating a cohesive multimodal summary, this approach anchors generative AI in rich semantic evidence and serves as a lightweight proxy for high-efficiency retrieval. However, traditional metrics like BLEU or ROUGE fail to quantify information coverage across disparate modalities, such as comparing a paragraph of text to a sequence of keyframes. To address this, we propose the Video Summary Information Loss (ViSIL) score, an information-theoretic framework that quantifies the video information not captured by a summary via vision-language model (VLM) inference. By measuring the information loss, ViSIL is a unified metric that enables direct comparison across multimodal summary formats despite their structural discrepancies. Our results demonstrate that ViSIL scores show a statistically significant correlation with both human and VLM performance on Video Question Answering (VQA) tasks. ViSIL also enables summary selection to optimize the trade-off between information loss and processing speed, establishing a Pareto-optimal frontier that outperforms text summaries by $7\%$ in VQA accuracy without increasing processing load.
VIBE: Video-to-Text Information Bottleneck Evaluation for TL;DR
May 23, 2025Many decision-making tasks, where both accuracy and efficiency matter, still require human supervision. For example, tasks like traffic officers reviewing hour-long dashcam footage or researchers screening conference videos can benefit from concise summaries that reduce cognitive load and save time. Yet current vision-language models (VLMs) often produce verbose, redundant outputs that hinder task performance. Existing video caption evaluation depends on costly human annotations and overlooks the summaries' utility in downstream tasks. We address these gaps with Video-to-text Information Bottleneck Evaluation (VIBE), an annotation-free method that scores VLM outputs using two metrics: grounding (how well the summary aligns with visual content) and utility (how informative it is for the task). VIBE selects from randomly sampled VLM outputs by ranking them according to the two scores to support effective human decision-making. Human studies on LearningPaper24, SUTD-TrafficQA, and LongVideoBench show that summaries selected by VIBE consistently improve performance-boosting task accuracy by up to 61.23% and reducing response time by 75.77% compared to naive VLM summaries or raw video.
Evaluating Human Trust in LLM-Based Planners: A Preliminary Study
Feb 27, 2025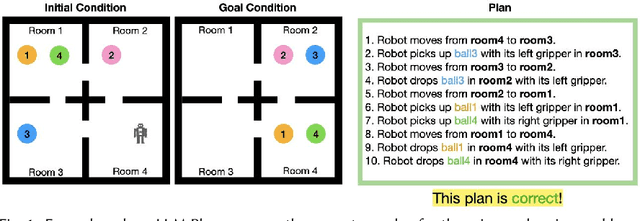

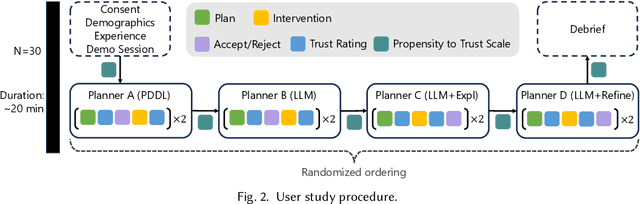
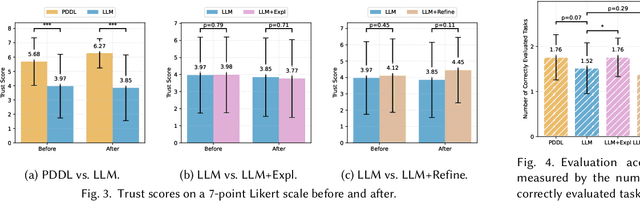
Large Language Models (LLMs) are increasingly used for planning tasks, offering unique capabilities not found in classical planners such as generating explanations and iterative refinement. However, trust--a critical factor in the adoption of planning systems--remains underexplored in the context of LLM-based planning tasks. This study bridges this gap by comparing human trust in LLM-based planners with classical planners through a user study in a Planning Domain Definition Language (PDDL) domain. Combining subjective measures, such as trust questionnaires, with objective metrics like evaluation accuracy, our findings reveal that correctness is the primary driver of trust and performance. Explanations provided by the LLM improved evaluation accuracy but had limited impact on trust, while plan refinement showed potential for increasing trust without significantly enhancing evaluation accuracy.
Learning Human Perception Dynamics for Informative Robot Communication
Feb 03, 2025



Human-robot cooperative navigation is challenging in environments with incomplete information. We introduce CoNav-Maze, a simulated robotics environment where a robot navigates using local perception while a human operator provides guidance based on an inaccurate map. The robot can share its camera views to improve the operator's understanding of the environment. To enable efficient human-robot cooperation, we propose Information Gain Monte Carlo Tree Search (IG-MCTS), an online planning algorithm that balances autonomous movement and informative communication. Central to IG-MCTS is a neural human perception dynamics model that estimates how humans distill information from robot communications. We collect a dataset through a crowdsourced mapping task in CoNav-Maze and train this model using a fully convolutional architecture with data augmentation. User studies show that IG-MCTS outperforms teleoperation and instruction-following baselines, achieving comparable task performance with significantly less communication and lower human cognitive load, as evidenced by eye-tracking metrics.
Human-Agent Coordination in Games under Incomplete Information via Multi-Step Intent
Oct 23, 2024Strategic coordination between autonomous agents and human partners under incomplete information can be modeled as turn-based cooperative games. We extend a turn-based game under incomplete information, the shared-control game, to allow players to take multiple actions per turn rather than a single action. The extension enables the use of multi-step intent, which we hypothesize will improve performance in long-horizon tasks. To synthesize cooperative policies for the agent in this extended game, we propose an approach featuring a memory module for a running probabilistic belief of the environment dynamics and an online planning algorithm called IntentMCTS. This algorithm strategically selects the next action by leveraging any communicated multi-step intent via reward augmentation while considering the current belief. Agent-to-agent simulations in the Gnomes at Night testbed demonstrate that IntentMCTS requires fewer steps and control switches than baseline methods. A human-agent user study corroborates these findings, showing an 18.52% higher success rate compared to the heuristic baseline and a 5.56% improvement over the single-step prior work. Participants also report lower cognitive load, frustration, and higher satisfaction with the IntentMCTS agent partner.
Human-Agent Cooperation in Games under Incomplete Information through Natural Language Communication
May 23, 2024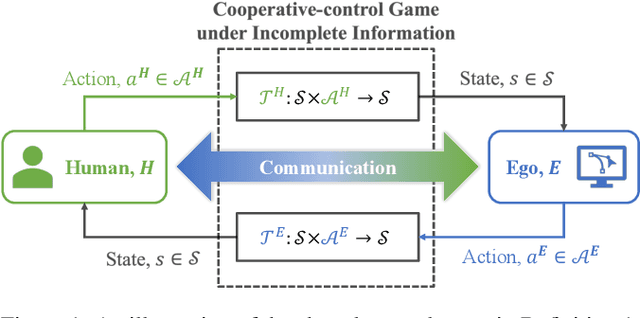

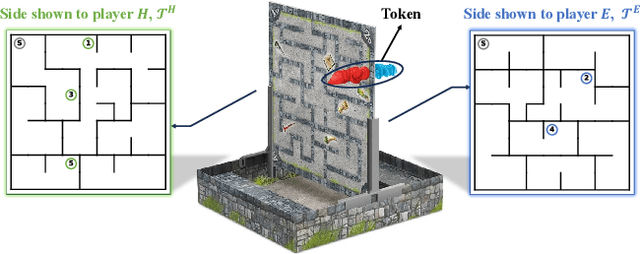
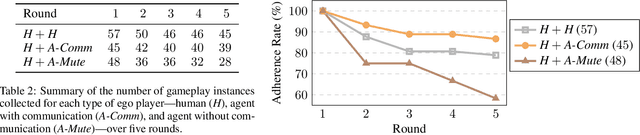
Developing autonomous agents that can strategize and cooperate with humans under information asymmetry is challenging without effective communication in natural language. We introduce a shared-control game, where two players collectively control a token in alternating turns to achieve a common objective under incomplete information. We formulate a policy synthesis problem for an autonomous agent in this game with a human as the other player. To solve this problem, we propose a communication-based approach comprising a language module and a planning module. The language module translates natural language messages into and from a finite set of flags, a compact representation defined to capture player intents. The planning module leverages these flags to compute a policy using an asymmetric information-set Monte Carlo tree search with flag exchange algorithm we present. We evaluate the effectiveness of this approach in a testbed based on Gnomes at Night, a search-and-find maze board game. Results of human subject experiments show that communication narrows the information gap between players and enhances human-agent cooperation efficiency with fewer turns.
Soft-Bellman Equilibrium in Affine Markov Games: Forward Solutions and Inverse Learning
Mar 31, 2023


Markov games model interactions among multiple players in a stochastic, dynamic environment. Each player in a Markov game maximizes its expected total discounted reward, which depends upon the policies of the other players. We formulate a class of Markov games, termed affine Markov games, where an affine reward function couples the players' actions. We introduce a novel solution concept, the soft-Bellman equilibrium, where each player is boundedly rational and chooses a soft-Bellman policy rather than a purely rational policy as in the well-known Nash equilibrium concept. We provide conditions for the existence and uniqueness of the soft-Bellman equilibrium and propose a nonlinear least squares algorithm to compute such an equilibrium in the forward problem. We then solve the inverse game problem of inferring the players' reward parameters from observed state-action trajectories via a projected gradient algorithm. Experiments in a predator-prey OpenAI Gym environment show that the reward parameters inferred by the proposed algorithm outperform those inferred by a baseline algorithm: they reduce the Kullback-Leibler divergence between the equilibrium policies and observed policies by at least two orders of magnitude.
Multi-Objective Controller Synthesis with Uncertain Human Preferences
May 10, 2021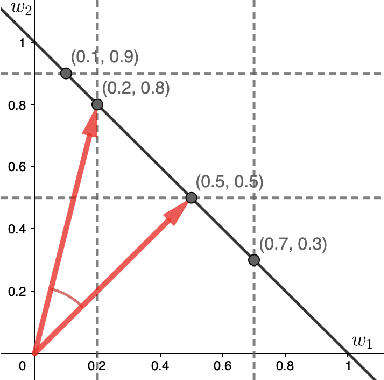
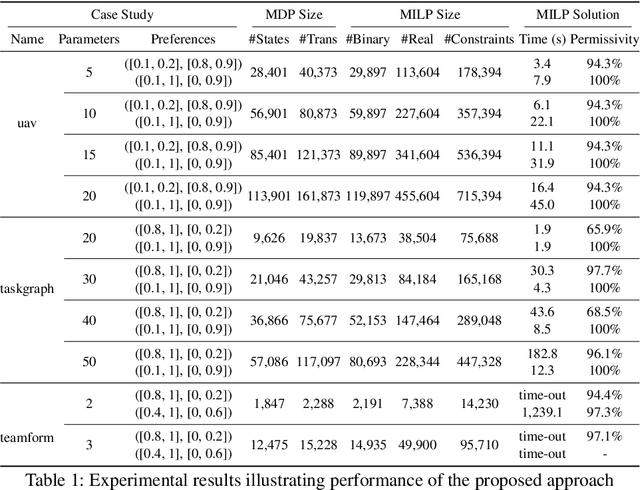


Multi-objective controller synthesis concerns the problem of computing an optimal controller subject to multiple (possibly conflicting) objective properties. The relative importance of objectives is often specified by human decision-makers. However, there is inherent uncertainty in human preferences (e.g., due to different preference elicitation methods). In this paper, we formalize the notion of uncertain human preferences and present a novel approach that accounts for uncertain human preferences in the multi-objective controller synthesis for Markov decision processes (MDPs). Our approach is based on mixed-integer linear programming (MILP) and synthesizes a sound, optimally permissive multi-strategy with respect to a multi-objective property and an uncertain set of human preferences. Experimental results on a range of large case studies show that our MILP-based approach is feasible and scalable to synthesize sound, optimally permissive multi-strategies with varying MDP model sizes and uncertainty levels of human preferences. Evaluation via an online user study also demonstrates the quality and benefits of synthesized (multi-)strategies.
Towards Personalized Explanation of Robotic Planning via User Feedback
Nov 01, 2020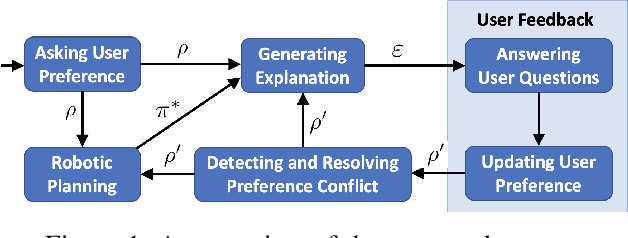

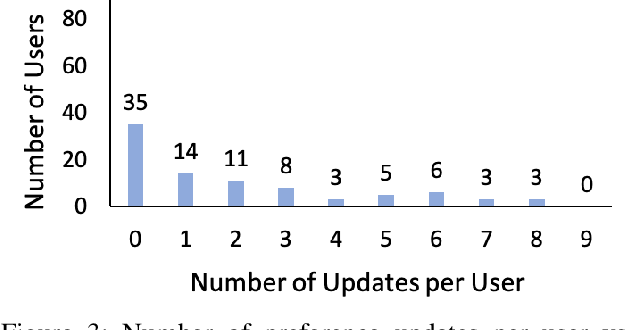
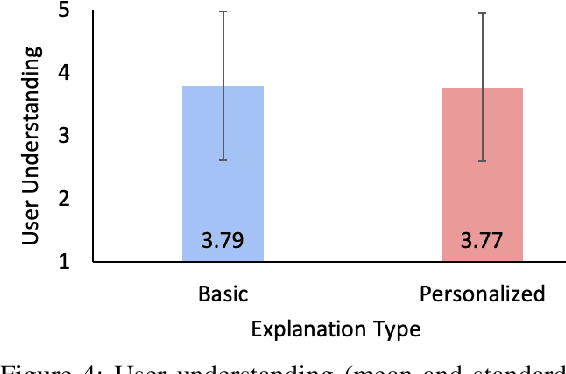
Prior studies have found that providing explanations about robots' decisions and actions help to improve system transparency, increase human users' trust of robots, and enable effective human-robot collaboration. Different users have various preferences about what should be included in explanations. However, little research has been conducted for the generation of personalized explanations. In this paper, we present a system for generating personalized explanations of robotic planning via user feedback. We consider robotic planning using Markov decision processes (MDPs) and develop an algorithm to automatically generate a personalized explanation of an optimal robotic plan (i.e., an optimal MDP policy) based on the user preference regarding four elements (i.e., objective, locality, specificity, and abstraction). In addition, we design the system to interact with users via answering users' further questions about the generated explanations. Users have the option to update their preferences to view different explanations. The system is capable of detecting and resolving any preference conflict via user interaction. Our user study results show that the generated personalized explanations improve user satisfaction, while the majority of users liked the system's capabilities of question-answering, and conflict detection and resolution.
Towards Transparent Robotic Planning via Contrastive Explanations
Mar 16, 2020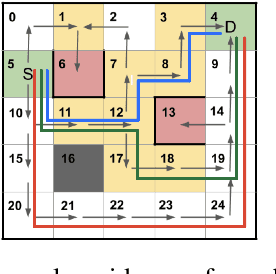
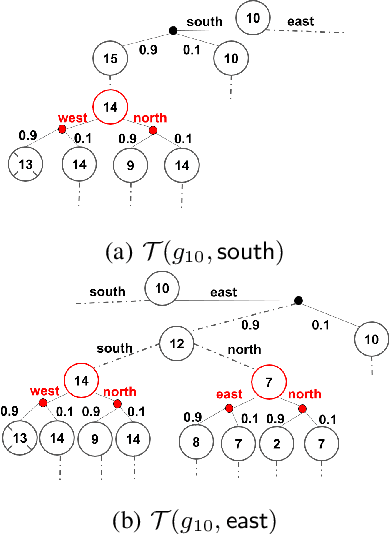
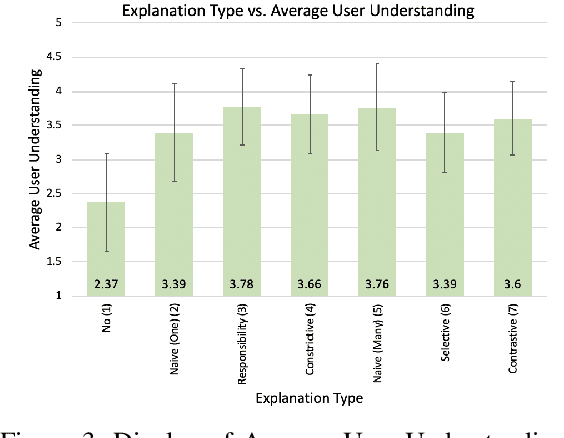
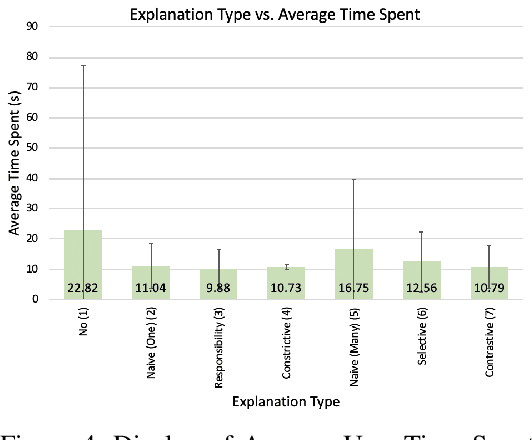
Providing explanations of chosen robotic actions can help to increase the transparency of robotic planning and improve users' trust. Social sciences suggest that the best explanations are contrastive, explaining not just why one action is taken, but why one action is taken instead of another. We formalize the notion of contrastive explanations for robotic planning policies based on Markov decision processes, drawing on insights from the social sciences. We present methods for the automated generation of contrastive explanations with three key factors: selectiveness, constrictiveness, and responsibility. The results of a user study with 100 participants on the Amazon Mechanical Turk platform show that our generated contrastive explanations can help to increase users' understanding and trust of robotic planning policies while reducing users' cognitive burden.