 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Online Dynamics Model Adaptation in Off-Road Autonomous Driving
Apr 23, 2025
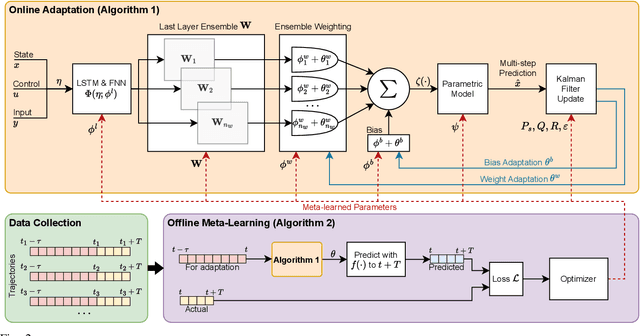

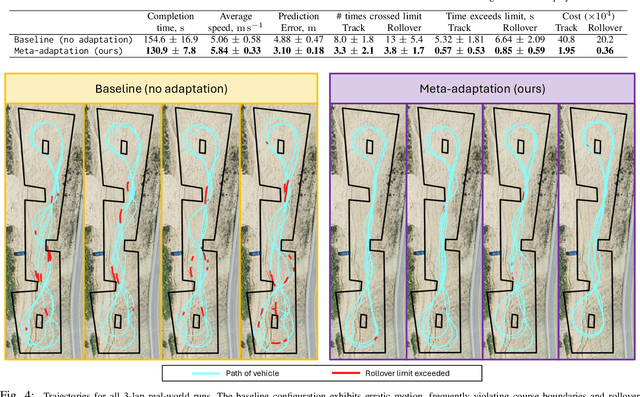
High-speed off-road autonomous driving presents unique challenges due to complex, evolving terrain characteristics and the difficulty of accurately modeling terrain-vehicle interactions. While dynamics models used in model-based control can be learned from real-world data, they often struggle to generalize to unseen terrain, making real-time adaptation essential. We propose a novel framework that combines a Kalman filter-based online adaptation scheme with meta-learned parameters to address these challenges. Offline meta-learning optimizes the basis functions along which adaptation occurs, as well as the adaptation parameters, while online adaptation dynamically adjusts the onboard dynamics model in real time for model-based control. We validate our approach through extensive experiments, including real-world testing on a full-scale autonomous off-road vehicle, demonstrating that our method outperforms baseline approaches in prediction accuracy, performance, and safety metrics, particularly in safety-critical scenarios. Our results underscore the effectiveness of meta-learned dynamics model adaptation, advancing the development of reliable autonomous systems capable of navigating diverse and unseen environments. Video is available at: https://youtu.be/cCKHHrDRQEA
Learning to Walk from Three Minutes of Real-World Data with Semi-structured Dynamics Models
Oct 11, 2024Traditionally, model-based reinforcement learning (MBRL) methods exploit neural networks as flexible function approximators to represent a priori unknown environment dynamics. However, training data are typically scarce in practice, and these black-box models often fail to generalize. Modeling architectures that leverage known physics can substantially reduce the complexity of system-identification, but break down in the face of complex phenomena such as contact. We introduce a novel framework for learning semi-structured dynamics models for contact-rich systems which seamlessly integrates structured first principles modeling techniques with black-box auto-regressive models. Specifically, we develop an ensemble of probabilistic models to estimate external forces, conditioned on historical observations and actions, and integrate these predictions using known Lagrangian dynamics. With this semi-structured approach, we can make accurate long-horizon predictions with substantially less data than prior methods. We leverage this capability and propose Semi-Structured Reinforcement Learning (SSRL) a simple model-based learning framework which pushes the sample complexity boundary for real-world learning. We validate our approach on a real-world Unitree Go1 quadruped robot, learning dynamic gaits -- from scratch -- on both hard and soft surfaces with just a few minutes of real-world data. Video and code are available at: https://sites.google.com/utexas.edu/ssrl
Active Inverse Learning in Stackelberg Trajectory Games
Aug 15, 2023Game-theoretic inverse learning is the problem of inferring the players' objectives from their actions. We formulate an inverse learning problem in a Stackelberg game between a leader and a follower, where each player's action is the trajectory of a dynamical system. We propose an active inverse learning method for the leader to infer which hypothesis among a finite set of candidates describes the follower's objective function. Instead of using passively observed trajectories like existing methods, the proposed method actively maximizes the differences in the follower's trajectories under different hypotheses to accelerate the leader's inference. We demonstrate the proposed method in a receding-horizon repeated trajectory game. Compared with uniformly random inputs, the leader inputs provided by the proposed method accelerate the convergence of the probability of different hypotheses conditioned on the follower's trajectory by orders of magnitude.
Feedback is All You Need: Real-World Reinforcement Learning with Approximate Physics-Based Models
Jul 16, 2023We focus on developing efficient and reliable policy optimization strategies for robot learning with real-world data. In recent years, policy gradient methods have emerged as a promising paradigm for training control policies in simulation. However, these approaches often remain too data inefficient or unreliable to train on real robotic hardware. In this paper we introduce a novel policy gradient-based policy optimization framework which systematically leverages a (possibly highly simplified) first-principles model and enables learning precise control policies with limited amounts of real-world data. Our approach $1)$ uses the derivatives of the model to produce sample-efficient estimates of the policy gradient and $2)$ uses the model to design a low-level tracking controller, which is embedded in the policy class. Theoretical analysis provides insight into how the presence of this feedback controller addresses overcomes key limitations of stand-alone policy gradient methods, while hardware experiments with a small car and quadruped demonstrate that our approach can learn precise control strategies reliably and with only minutes of real-world data.