 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Teacher-Student Deep Reinforcement Learning
Paper and Code
Feb 18, 2021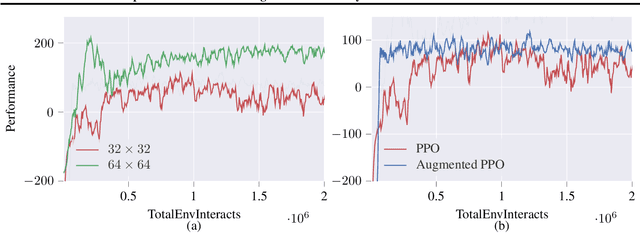
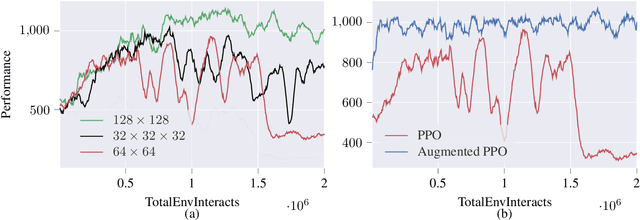
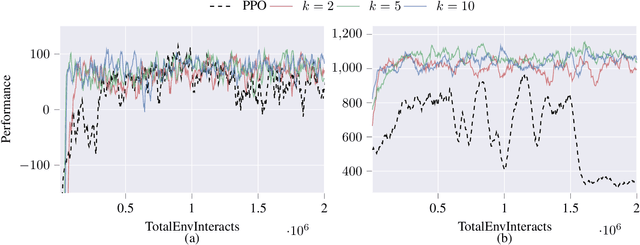
Deep reinforcement learning agents may learn complex tasks more efficiently when they coordinate with one another. We consider a teacher-student coordination scheme wherein an agent may ask another agent for demonstrations. Despite the benefits of sharing demonstrations, however, potential adversaries may obtain sensitive information belonging to the teacher by observing the demonstrations. In particular, deep reinforcement learning algorithms are known to be vulnerable to membership attacks, which make accurate inferences about the membership of the entries of training datasets. Therefore, there is a need to safeguard the teacher against such privacy threats. We fix the teacher's policy as the context of the demonstrations, which allows for different internal models across the student and the teacher, and contrasts the existing methods. We make the following two contributions. (i) We develop a differentially private mechanism that protects the privacy of the teacher's training dataset. (ii) We propose a proximal policy-optimization objective that enables the student to benefit from the demonstrations despite the perturbations of the privacy mechanism. We empirically show that the algorithm improves the student's learning upon convergence rate and utility. Specifically, compared with an agent who learns the same task on its own, we observe that the student's policy converges faster, and the converging policy accumulates higher rewards more robustly.