 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-State Controllers for (Hidden-Model) POMDPs using Deep Reinforcement Learning
Feb 09, 2026Solving partially observable Markov decision processes (POMDPs) requires computing policies under imperfect state information. Despite recent advances, the scalability of existing POMDP solvers remains limited. Moreover, many settings require a policy that is robust across multiple POMDPs, further aggravating the scalability issue. We propose the Lexpop framework for POMDP solving. Lexpop (1) employs deep reinforcement learning to train a neural policy, represented by a recurrent neural network, and (2) constructs a finite-state controller mimicking the neural policy through efficient extraction methods. Crucially, unlike neural policies, such controllers can be formally evaluated, providing performance guarantees. We extend Lexpop to compute robust policies for hidden-model POMDPs (HM-POMDPs), which describe finite sets of POMDPs. We associate every extracted controller with its worst-case POMDP. Using a set of such POMDPs, we iteratively train a robust neural policy and consequently extract a robust controller. Our experiments show that on problems with large state spaces, Lexpop outperforms state-of-the-art solvers for POMDPs as well as HM-POMDPs.
\textsc{rfPG}: Robust Finite-Memory Policy Gradients for Hidden-Model POMDPs
May 14, 2025Partially observable Markov decision processes (POMDPs) model specific environments in sequential decision-making under uncertainty. Critically, optimal policies for POMDPs may not be robust against perturbations in the environment. Hidden-model POMDPs (HM-POMDPs) capture sets of different environment models, that is, POMDPs with a shared action and observation space. The intuition is that the true model is hidden among a set of potential models, and it is unknown which model will be the environment at execution time. A policy is robust for a given HM-POMDP if it achieves sufficient performance for each of its POMDPs. We compute such robust policies by combining two orthogonal techniques: (1) a deductive formal verification technique that supports tractable robust policy evaluation by computing a worst-case POMDP within the HM-POMDP and (2) subgradient ascent to optimize the candidate policy for a worst-case POMDP. The empirical evaluation shows that, compared to various baselines, our approach (1) produces policies that are more robust and generalize better to unseen POMDPs and (2) scales to HM-POMDPs that consist of over a hundred thousand environments.
Pessimistic Iterative Planning for Robust POMDPs
Aug 16, 2024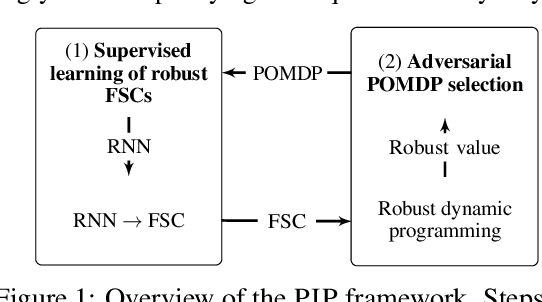
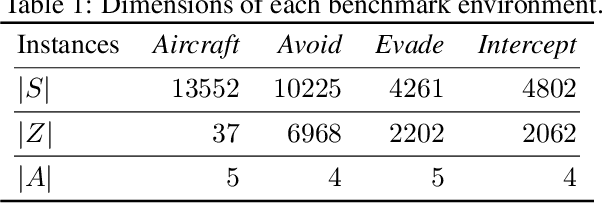
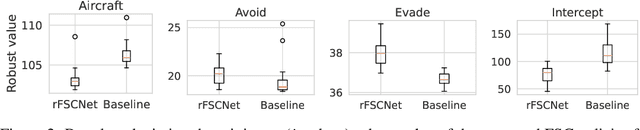
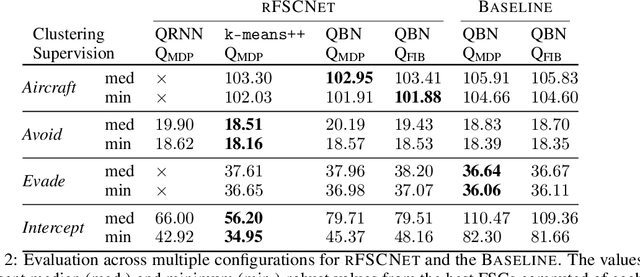
Robust partially observable Markov decision processes (robust POMDPs) extend classical POMDPs to handle additional uncertainty on the transition and observation probabilities via so-called uncertainty sets. Policies for robust POMDPs must not only be memory-based to account for partial observability but also robust against model uncertainty to account for the worst-case instances from the uncertainty sets. We propose the pessimistic iterative planning (PIP) framework, which finds robust memory-based policies for robust POMDPs. PIP alternates between two main steps: (1) selecting an adversarial (non-robust) POMDP via worst-case probability instances from the uncertainty sets; and (2) computing a finite-state controller (FSC) for this adversarial POMDP. We evaluate the performance of this FSC on the original robust POMDP and use this evaluation in step (1) to select the next adversarial POMDP. Within PIP, we propose the rFSCNet algorithm. In each iteration, rFSCNet finds an FSC through a recurrent neural network trained using supervision policies optimized for the adversarial POMDP. The empirical evaluation in four benchmark environments showcases improved robustness against a baseline method in an ablation study and competitive performance compared to a state-of-the-art robust POMDP solver.
Factored Online Planning in Many-Agent POMDPs
Dec 22, 2023



In centralized multi-agent systems, often modeled as multi-agent partially observable Markov decision processes (MPOMDPs), the action and observation spaces grow exponentially with the number of agents, making the value and belief estimation of single-agent online planning ineffective. Prior work partially tackles value estimation by exploiting the inherent structure of multi-agent settings via so-called coordination graphs. Additionally, belief estimation has been improved by incorporating the likelihood of observations into the approximation. However, the challenges of value estimation and belief estimation have only been tackled individually, which prevents existing methods from scaling to many agents. Therefore, we address these challenges simultaneously. First, we introduce weighted particle filtering to a sample-based online planner for MPOMDPs. Second, we present a scalable approximation of the belief. Third, we bring an approach that exploits the typical locality of agent interactions to novel online planning algorithms for MPOMDPs operating on a so-called sparse particle filter tree. Our experimental evaluation against several state-of-the-art baselines shows that our methods (1) are competitive in settings with only a few agents and (2) improve over the baselines in the presence of many agents.