 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Function Encoder-Based Differentiable Predictive Control
Nov 11, 2025We introduce a differentiable framework for zero-shot adaptive control over parametric families of nonlinear dynamical systems. Our approach integrates a function encoder-based neural ODE (FE-NODE) for modeling system dynamics with a differentiable predictive control (DPC) for offline self-supervised learning of explicit control policies. The FE-NODE captures nonlinear behaviors in state transitions and enables zero-shot adaptation to new systems without retraining, while the DPC efficiently learns control policies across system parameterizations, thus eliminating costly online optimization common in classical model predictive control. We demonstrate the efficiency, accuracy, and online adaptability of the proposed method across a range of nonlinear systems with varying parametric scenarios, highlighting its potential as a general-purpose tool for fast zero-shot adaptive control.
Online Adaptation of Terrain-Aware Dynamics for Planning in Unstructured Environments
Jun 04, 2025Autonomous mobile robots operating in remote, unstructured environments must adapt to new, unpredictable terrains that can change rapidly during operation. In such scenarios, a critical challenge becomes estimating the robot's dynamics on changing terrain in order to enable reliable, accurate navigation and planning. We present a novel online adaptation approach for terrain-aware dynamics modeling and planning using function encoders. Our approach efficiently adapts to new terrains at runtime using limited online data without retraining or fine-tuning. By learning a set of neural network basis functions that span the robot dynamics on diverse terrains, we enable rapid online adaptation to new, unseen terrains and environments as a simple least-squares calculation. We demonstrate our approach for terrain adaptation in a Unity-based robotics simulator and show that the downstream controller has better empirical performance due to higher accuracy of the learned model. This leads to fewer collisions with obstacles while navigating in cluttered environments as compared to a neural ODE baseline.
Function Encoders: A Principled Approach to Transfer Learning in Hilbert Spaces
Jan 30, 2025A central challenge in transfer learning is designing algorithms that can quickly adapt and generalize to new tasks without retraining. Yet, the conditions of when and how algorithms can effectively transfer to new tasks is poorly characterized. We introduce a geometric characterization of transfer in Hilbert spaces and define three types of inductive transfer: interpolation within the convex hull, extrapolation to the linear span, and extrapolation outside the span. We propose a method grounded in the theory of function encoders to achieve all three types of transfer. Specifically, we introduce a novel training scheme for function encoders using least-squares optimization, prove a universal approximation theorem for function encoders, and provide a comprehensive comparison with existing approaches such as transformers and meta-learning on four diverse benchmarks. Our experiments demonstrate that the function encoder outperforms state-of-the-art methods on four benchmark tasks and on all three types of transfer.
Zero-Shot Transfer of Neural ODEs
May 14, 2024
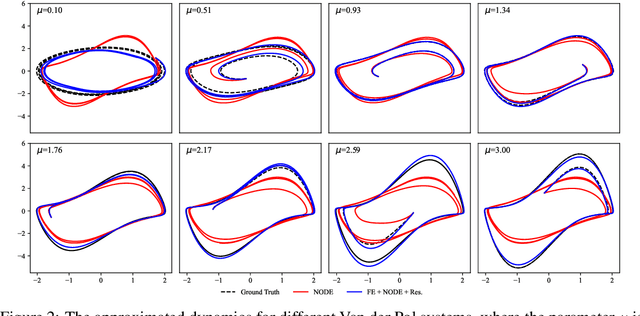
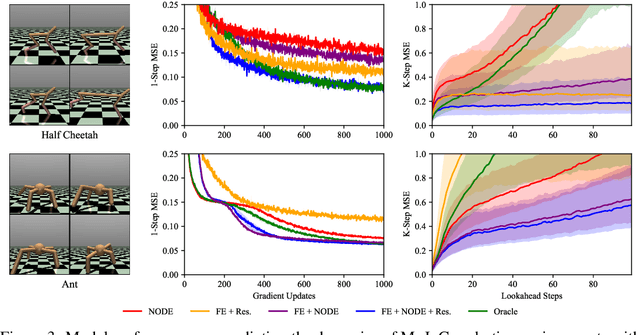
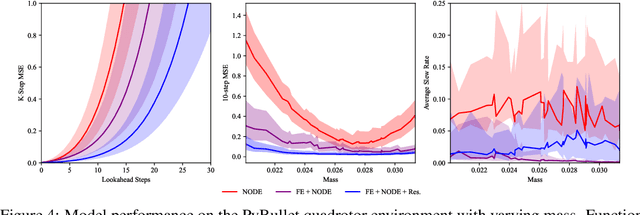
Autonomous systems often encounter environments and scenarios beyond the scope of their training data, which underscores a critical challenge: the need to generalize and adapt to unseen scenarios in real time. This challenge necessitates new mathematical and algorithmic tools that enable adaptation and zero-shot transfer. To this end, we leverage the theory of function encoders, which enables zero-shot transfer by combining the flexibility of neural networks with the mathematical principles of Hilbert spaces. Using this theory, we first present a method for learning a space of dynamics spanned by a set of neural ODE basis functions. After training, the proposed approach can rapidly identify dynamics in the learned space using an efficient inner product calculation. Critically, this calculation requires no gradient calculations or retraining during the online phase. This method enables zero-shot transfer for autonomous systems at runtime and opens the door for a new class of adaptable control algorithms. We demonstrate state-of-the-art system modeling accuracy for two MuJoCo robot environments and show that the learned models can be used for more efficient MPC control of a quadrotor.
Zero-Shot Reinforcement Learning via Function Encoders
Jan 30, 2024Although reinforcement learning (RL) can solve many challenging sequential decision making problems, achieving zero-shot transfer across related tasks remains a challenge. The difficulty lies in finding a good representation for the current task so that the agent understands how it relates to previously seen tasks. To achieve zero-shot transfer, we introduce the function encoder, a representation learning algorithm which represents a function as a weighted combination of learned, non-linear basis functions. By using a function encoder to represent the reward function or the transition function, the agent has information on how the current task relates to previously seen tasks via a coherent vector representation. Thus, the agent is able to achieve transfer between related tasks at run time with no additional training. We demonstrate state-of-the-art data efficiency, asymptotic performance, and training stability in three RL fields by augmenting basic RL algorithms with a function encoder task representation.
Fine-Tuning Language Models Using Formal Methods Feedback
Oct 27, 2023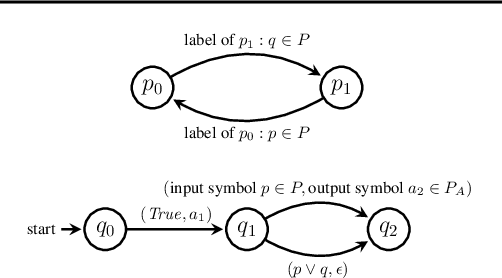
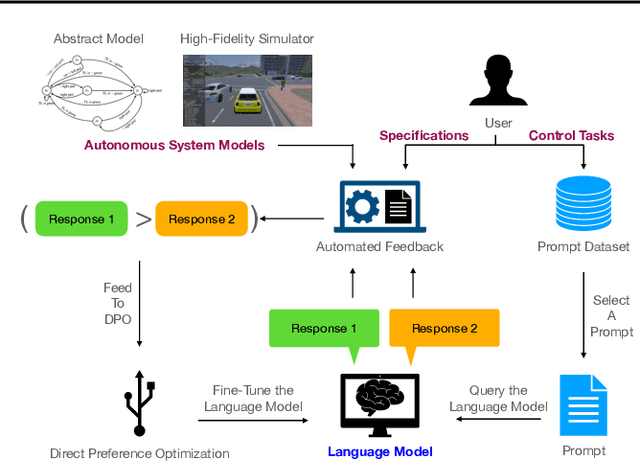

Although pre-trained language models encode generic knowledge beneficial for planning and control, they may fail to generate appropriate control policies for domain-specific tasks. Existing fine-tuning methods use human feedback to address this limitation, however, sourcing human feedback is labor intensive and costly. We present a fully automated approach to fine-tune pre-trained language models for applications in autonomous systems, bridging the gap between generic knowledge and domain-specific requirements while reducing cost. The method synthesizes automaton-based controllers from pre-trained models guided by natural language task descriptions. These controllers are verifiable against independently provided specifications within a world model, which can be abstract or obtained from a high-fidelity simulator. Controllers with high compliance with the desired specifications receive higher ranks, guiding the iterative fine-tuning process. We provide quantitative evidences, primarily in autonomous driving, to demonstrate the method's effectiveness across multiple tasks. The results indicate an improvement in percentage of specifications satisfied by the controller from 60% to 90%.