 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepHQ: Learned Hierarchical Quantizer for Progressive Deep Image Coding
Aug 22, 2024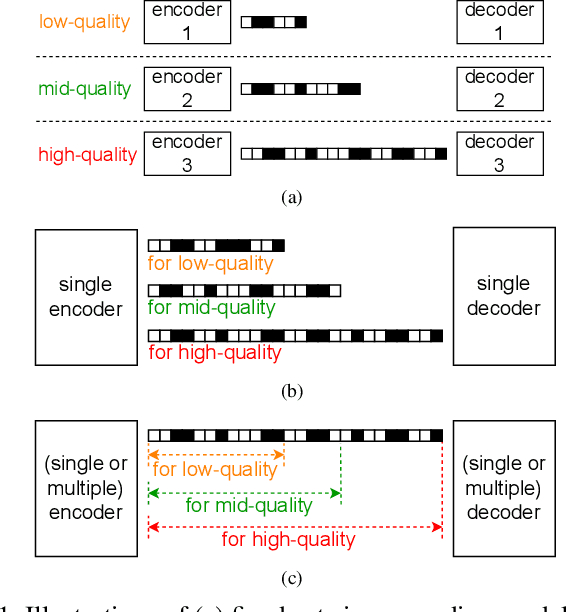



Unlike fixed- or variable-rate image coding, progressive image coding (PIC) aims to compress various qualities of images into a single bitstream, increasing the versatility of bitstream utilization and providing high compression efficiency compared to simulcast compression. Research on neural network (NN)-based PIC is in its early stages, mainly focusing on applying varying quantization step sizes to the transformed latent representations in a hierarchical manner. These approaches are designed to compress only the progressively added information as the quality improves, considering that a wider quantization interval for lower-quality compression includes multiple narrower sub-intervals for higher-quality compression. However, the existing methods are based on handcrafted quantization hierarchies, resulting in sub-optimal compression efficiency. In this paper, we propose an NN-based progressive coding method that firstly utilizes learned quantization step sizes via learning for each quantization layer. We also incorporate selective compression with which only the essential representation components are compressed for each quantization layer. We demonstrate that our method achieves significantly higher coding efficiency than the existing approaches with decreased decoding time and reduced model size.
End-to-End Learnable Multi-Scale Feature Compression for VCM
Jul 16, 2023The proliferation of deep learning-based machine vision applications has given rise to a new type of compression, so called video coding for machine (VCM). VCM differs from traditional video coding in that it is optimized for machine vision performance instead of human visual quality. In the feature compression track of MPEG-VCM, multi-scale features extracted from images are subject to compression. Recent feature compression works have demonstrated that the versatile video coding (VVC) standard-based approach can achieve a BD-rate reduction of up to 96% against MPEG-VCM feature anchor. However, it is still sub-optimal as VVC was not designed for extracted features but for natural images. Moreover, the high encoding complexity of VVC makes it difficult to design a lightweight encoder without sacrificing performance. To address these challenges, we propose a novel multi-scale feature compression method that enables both the end-to-end optimization on the extracted features and the design of lightweight encoders. The proposed model combines a learnable compressor with a multi-scale feature fusion network so that the redundancy in the multi-scale features is effectively removed. Instead of simply cascading the fusion network and the compression network, we integrate the fusion and encoding processes in an interleaved way. Our model first encodes a larger-scale feature to obtain a latent representation and then fuses the latent with a smaller-scale feature. This process is successively performed until the smallest-scale feature is fused and then the encoded latent at the final stage is entropy-coded for transmission. The results show that our model outperforms previous approaches by at least 52% BD-rate reduction and has $\times5$ to $\times27$ times less encoding time for object detection...
A Subjective and Objective Study of Space-Time Subsampled Video Quality
Jan 29, 2021
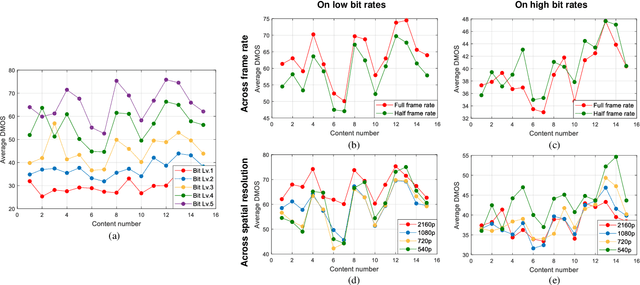
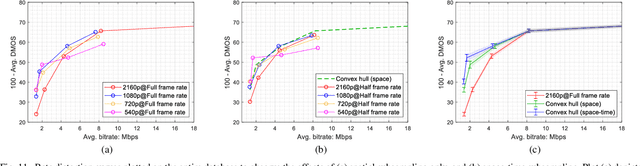
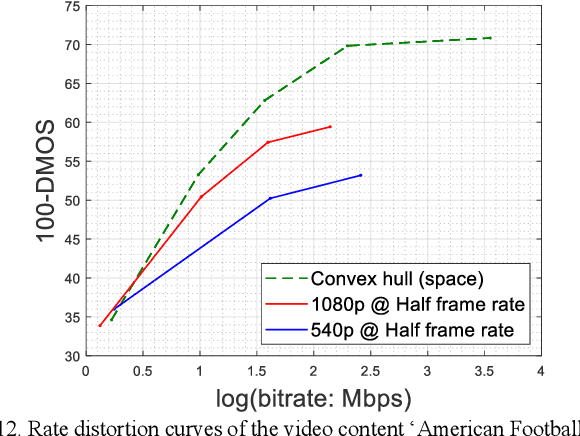
Video dimensions are continuously increasing to provide more realistic and immersive experiences to global streaming and social media viewers. However, increments in video parameters such as spatial resolution and frame rate are inevitably associated with larger data volumes. Transmitting increasingly voluminous videos through limited bandwidth networks in a perceptually optimal way is a current challenge affecting billions of viewers. One recent practice adopted by video service providers is space-time resolution adaptation in conjunction with video compression. Consequently, it is important to understand how different levels of space-time subsampling and compression affect the perceptual quality of videos. Towards making progress in this direction, we constructed a large new resource, called the ETRI-LIVE Space-Time Subsampled Video Quality (ETRI-LIVE STSVQ) database, containing 437 videos generated by applying various levels of combined space-time subsampling and video compression on 15 diverse video contents. We also conducted a large-scale human study on the new dataset, collecting about 15,000 subjective judgments of video quality. We provide a rate-distortion analysis of the collected subjective scores, enabling us to investigate the perceptual impact of space-time subsampling at different bit rates. We also evaluated and compared the performance of leading video quality models on the new database.