 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHessian-aware Training for Enhancing DNNs Resilience to Parameter Corruptions
Apr 02, 2025



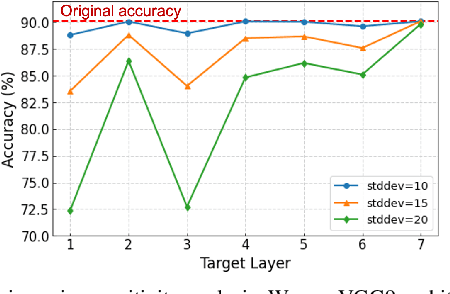
Deep neural networks are not resilient to parameter corruptions: even a single-bitwise error in their parameters in memory can cause an accuracy drop of over 10%, and in the worst cases, up to 99%. This susceptibility poses great challenges in deploying models on computing platforms, where adversaries can induce bit-flips through software or bitwise corruptions may occur naturally. Most prior work addresses this issue with hardware or system-level approaches, such as integrating additional hardware components to verify a model's integrity at inference. However, these methods have not been widely deployed as they require infrastructure or platform-wide modifications. In this paper, we propose a new approach to addressing this issue: training models to be more resilient to bitwise corruptions to their parameters. Our approach, Hessian-aware training, promotes models with $flatter$ loss surfaces. We show that, while there have been training methods, designed to improve generalization through Hessian-based approaches, they do not enhance resilience to parameter corruptions. In contrast, models trained with our method demonstrate increased resilience to parameter corruptions, particularly with a 20$-$50% reduction in the number of bits whose individual flipping leads to a 90$-$100% accuracy drop. Moreover, we show the synergy between ours and existing hardware and system-level defenses.
Gradient-based Bit Encoding Optimization for Noise-Robust Binary Memristive Crossbar
Jan 05, 2022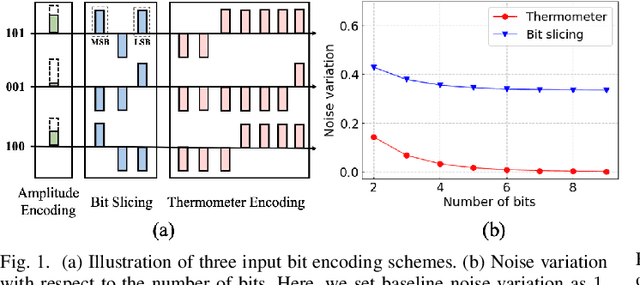
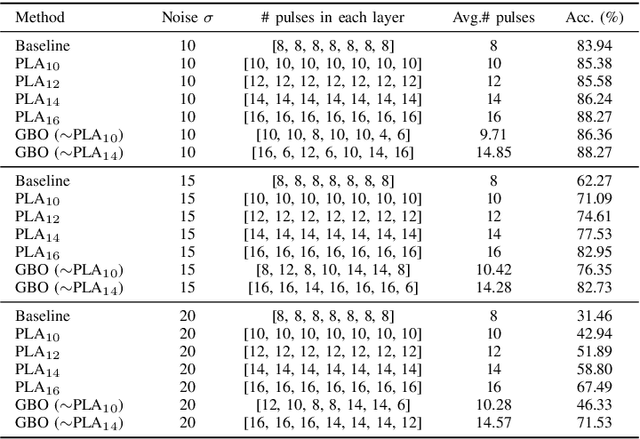

Binary memristive crossbars have gained huge attention as an energy-efficient deep learning hardware accelerator. Nonetheless, they suffer from various noises due to the analog nature of the crossbars. To overcome such limitations, most previous works train weight parameters with noise data obtained from a crossbar. These methods are, however, ineffective because it is difficult to collect noise data in large-volume manufacturing environment where each crossbar has a large device/circuit level variation. Moreover, we argue that there is still room for improvement even though these methods somewhat improve accuracy. This paper explores a new perspective on mitigating crossbar noise in a more generalized way by manipulating input binary bit encoding rather than training the weight of networks with respect to noise data. We first mathematically show that the noise decreases as the number of binary bit encoding pulses increases when representing the same amount of information. In addition, we propose Gradient-based Bit Encoding Optimization (GBO) which optimizes a different number of pulses at each layer, based on our in-depth analysis that each layer has a different level of noise sensitivity. The proposed heterogeneous layer-wise bit encoding scheme achieves high noise robustness with low computational cost. Our experimental results on public benchmark datasets show that GBO improves the classification accuracy by ~5-40% in severe noise scenarios.
Scalable Smartphone Cluster for Deep Learning
Oct 23, 2021
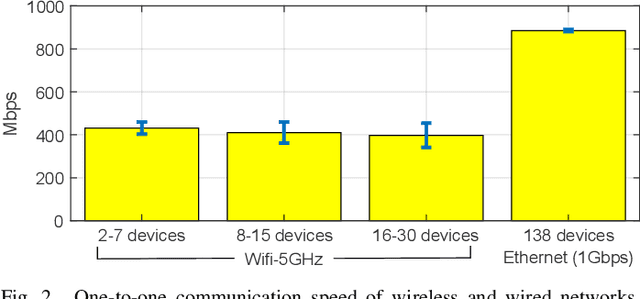

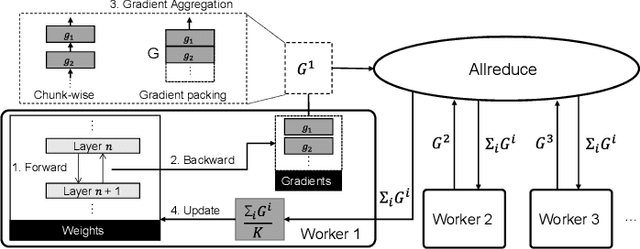
Various deep learning applications on smartphones have been rapidly rising, but training deep neural networks (DNNs) has too large computational burden to be executed on a single smartphone. A portable cluster, which connects smartphones with a wireless network and supports parallel computation using them, can be a potential approach to resolve the issue. However, by our findings, the limitations of wireless communication restrict the cluster size to up to 30 smartphones. Such small-scale clusters have insufficient computational power to train DNNs from scratch. In this paper, we propose a scalable smartphone cluster enabling deep learning training by removing the portability to increase its computational efficiency. The cluster connects 138 Galaxy S10+ devices with a wired network using Ethernet. We implemented large-batch synchronous training of DNNs based on Caffe, a deep learning library. The smartphone cluster yielded 90% of the speed of a P100 when training ResNet-50, and approximately 43x speed-up of a V100 when training MobileNet-v1.
T2FSNN: Deep Spiking Neural Networks with Time-to-first-spike Coding
Mar 26, 2020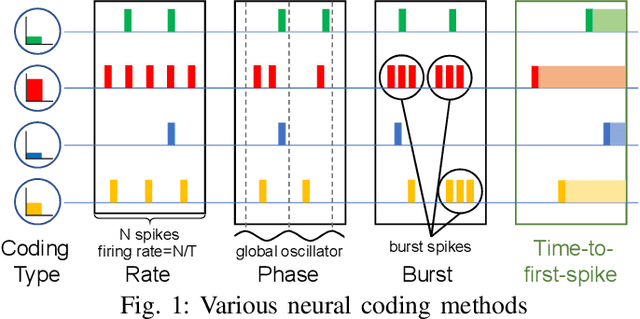
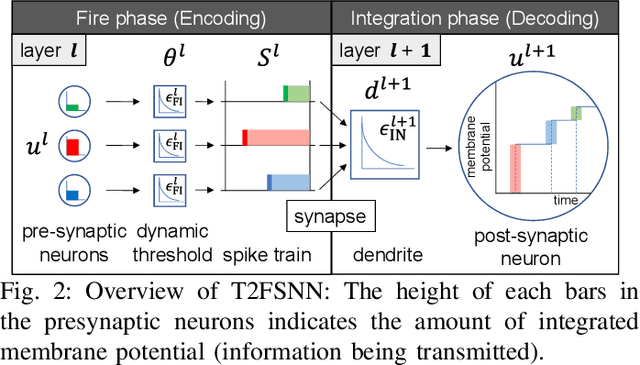
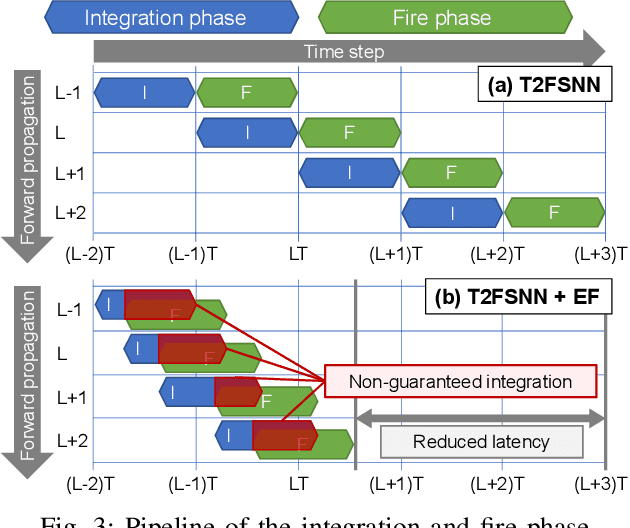
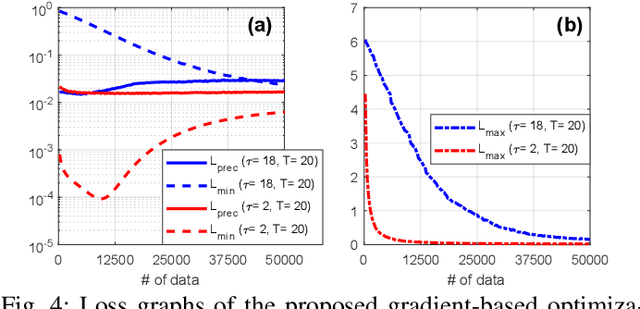
Spiking neural networks (SNNs) have gained considerable interest due to their energy-efficient characteristics, yet lack of a scalable training algorithm has restricted their applicability in practical machine learning problems. The deep neural network-to-SNN conversion approach has been widely studied to broaden the applicability of SNNs. Most previous studies, however, have not fully utilized spatio-temporal aspects of SNNs, which has led to inefficiency in terms of number of spikes and inference latency. In this paper, we present T2FSNN, which introduces the concept of time-to-first-spike coding into deep SNNs using the kernel-based dynamic threshold and dendrite to overcome the aforementioned drawback. In addition, we propose gradient-based optimization and early firing methods to further increase the efficiency of the T2FSNN. According to our results, the proposed methods can reduce inference latency and number of spikes to 22% and less than 1%, compared to those of burst coding, which is the state-of-the-art result on the CIFAR-100.
Spiking-YOLO: Spiking Neural Network for Real-time Object Detection
Mar 12, 2019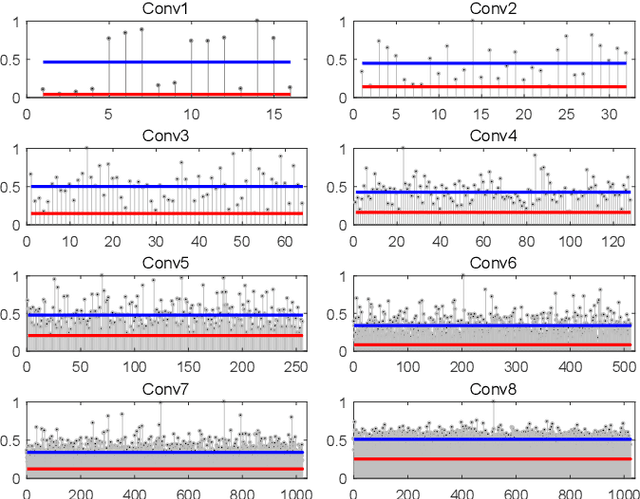
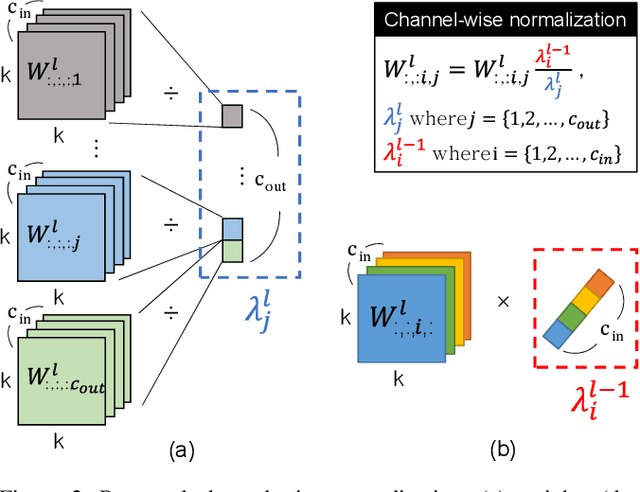
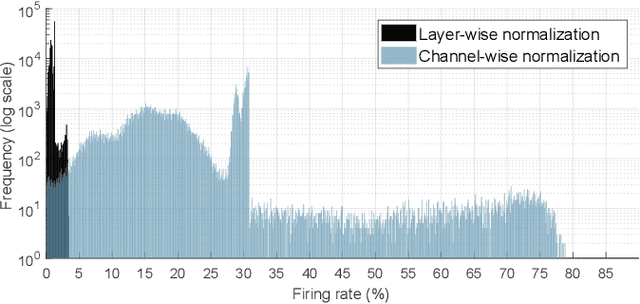
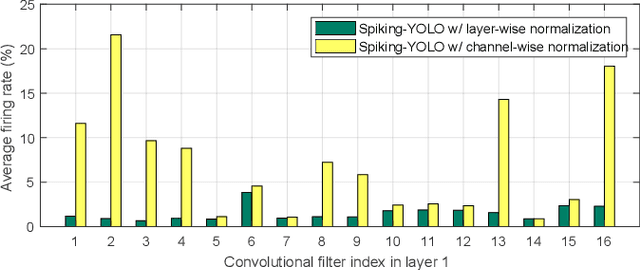
Over the past decade, deep neural networks (DNNs) have become a de-facto standard for solving machine learning problems. As we try to solve more advanced problems, growing demand for computing and power resources are inevitable, nearly impossible to employ DNNs on embedded systems, where available resources are limited. Given these circumstances, spiking neural networks (SNNs) are attracting widespread interest as the third generation of neural network, due to event-driven and low-powered nature. However, SNNs come at the cost of significant performance degradation largely due to complex dynamics of SNN neurons and non-differential spike operation. Thus, its application has been limited to relatively simple tasks such as image classification. In this paper, we investigate the performance degradation of SNNs in the much more challenging task of object detection. From our in-depth analysis, we introduce two novel methods to overcome a significant performance gap: channel-wise normalization and signed neuron with imbalanced threshold. Consequently, we present a spiked-based real-time object detection model, called Spiking-YOLO that provides near-lossless information transmission in a shorter period of time for deep SNN. Our experiments show that the Spiking-YOLO is able to achieve comparable results up to 97% of the original YOLO on a non-trivial dataset, PASCAL VOC.
Fast and Efficient Information Transmission with Burst Spikes in Deep Spiking Neural Networks
Sep 10, 2018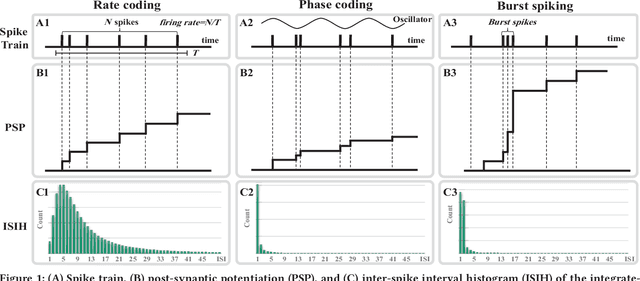
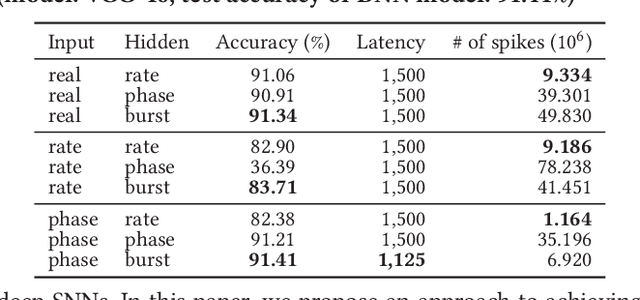
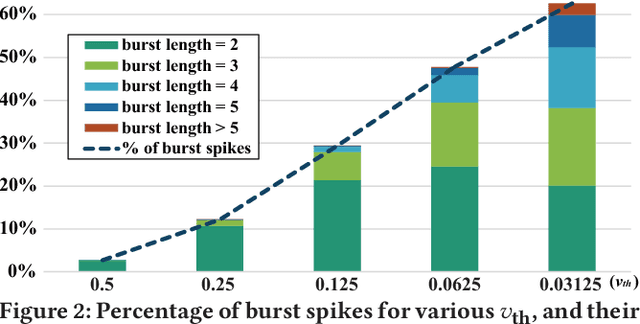
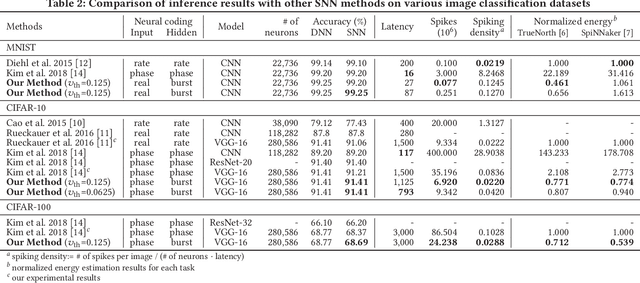
The spiking neural networks (SNNs), the 3rd generation of neural networks, are considered as one of the most promising artificial neural networks due to their energy-efficient computing capability. Despite their potential, the SNNs have a limited applicability owing to difficulties in training. Recently, conversion of a trained deep neural network (DNN) model to an SNN model has been extensively studied as an alternative approach. The result appears to be comparable to that of the DNN in image classification tasks. However, rate coding, one of the techniques used in modeling the SNNs, suffers from long latency due to its inability to transmit sufficient information to a subsequent neuron and this could have a catastrophic effect on a deeper SNN model. Another type of neural coding, called phase coding, also determines the amount of information being transmitted according to a global reference oscillator, and therefore, is inefficient in hidden layers where dynamics of neurons can change. In this paper, we propose a deep SNN model that can transmit information faster, and more efficiently between neurons by adopting a notion of burst spiking. Furthermore, we introduce a novel hybrid neural coding scheme that uses different neural coding schemes for different types of layers. Our experimental results for various image classification datasets, such as MNIST, CIFAR-10 and CIFAR-100, showed that the proposed methods can improve inference efficiency and shorten the latency while preserving high accuracy. Lastly, we validated the proposed methods through firing pattern analysis.
Streaming MANN: A Streaming-Based Inference for Energy-Efficient Memory-Augmented Neural Networks
May 21, 2018
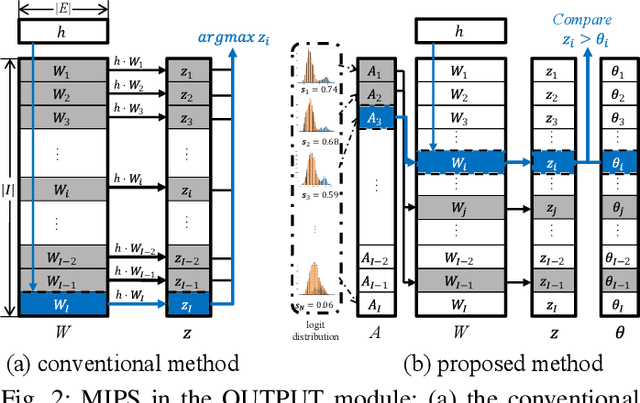


With the successful development of artificial intelligence using deep learning, there has been growing interest in its deployment. The mobile environment is the closest hardware platform to real life, and it has become an important platform for the success or failure of artificial intelligence. Memory-augmented neural networks (MANNs) are neural networks proposed to efficiently handle question-and-answer (Q&A) tasks, well-suited for mobile devices. As a MANN requires various types of operations and recurrent data paths, it is difficult to accelerate the inference in the structure designed for other conventional neural network models, which is one of the biggest obstacles to deploying MANNs in mobile environments. To address the aforementioned issues, we propose Streaming MANN. This is the first attempt to implement and demonstrate the architecture for energy-efficient inference of MANNs with the concept of streaming processing. To achieve the full potential of the streaming process, we propose a novel approach, called inference thresholding, using Bayesian approach considering the characteristics of natural language processing (NLP) tasks. To evaluate our proposed approaches, we implemented the architecture and method in a field-programmable gate array (FPGA) which is suitable for streaming processing. We measured the execution time and power consumption of the inference for the bAbI dataset. The experimental results showed that the performance efficiency per energy (FLOPS/kJ) of the Streaming MANN increased by a factor of up to about 126 compared to the results of NVIDIA TITAN V, and up to 140 if inference thresholding is applied.
Quantized Memory-Augmented Neural Networks
Nov 10, 2017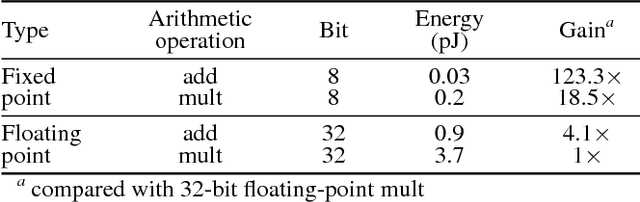

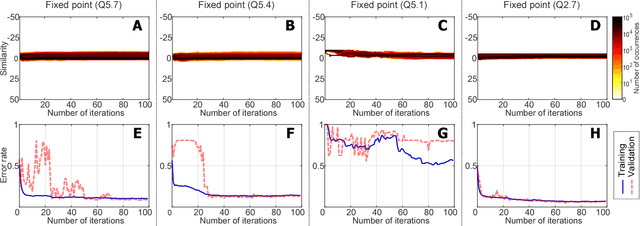
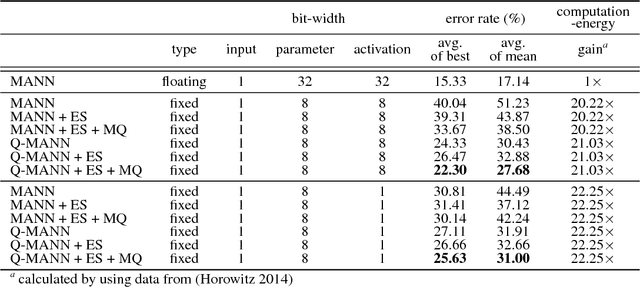
Memory-augmented neural networks (MANNs) refer to a class of neural network models equipped with external memory (such as neural Turing machines and memory networks). These neural networks outperform conventional recurrent neural networks (RNNs) in terms of learning long-term dependency, allowing them to solve intriguing AI tasks that would otherwise be hard to address. This paper concerns the problem of quantizing MANNs. Quantization is known to be effective when we deploy deep models on embedded systems with limited resources. Furthermore, quantization can substantially reduce the energy consumption of the inference procedure. These benefits justify recent developments of quantized multi layer perceptrons, convolutional networks, and RNNs. However, no prior work has reported the successful quantization of MANNs. The in-depth analysis presented here reveals various challenges that do not appear in the quantization of the other networks. Without addressing them properly, quantized MANNs would normally suffer from excessive quantization error which leads to degraded performance. In this paper, we identify memory addressing (specifically, content-based addressing) as the main reason for the performance degradation and propose a robust quantization method for MANNs to address the challenge. In our experiments, we achieved a computation-energy gain of 22x with 8-bit fixed-point and binary quantization compared to the floating-point implementation. Measured on the bAbI dataset, the resulting model, named the quantized MANN (Q-MANN), improved the error rate by 46% and 30% with 8-bit fixed-point and binary quantization, respectively, compared to the MANN quantized using conventional techniques.
Near-Data Processing for Differentiable Machine Learning Models
Apr 28, 2017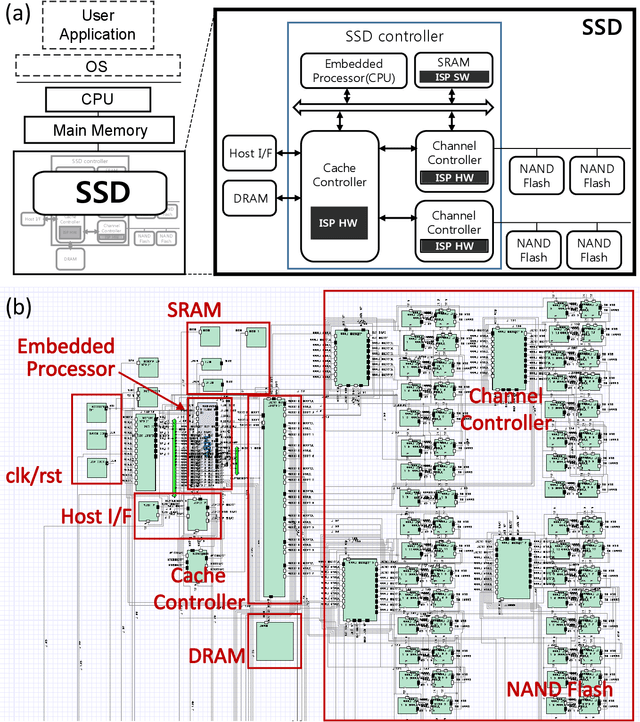

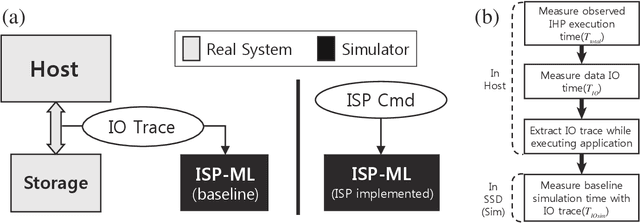
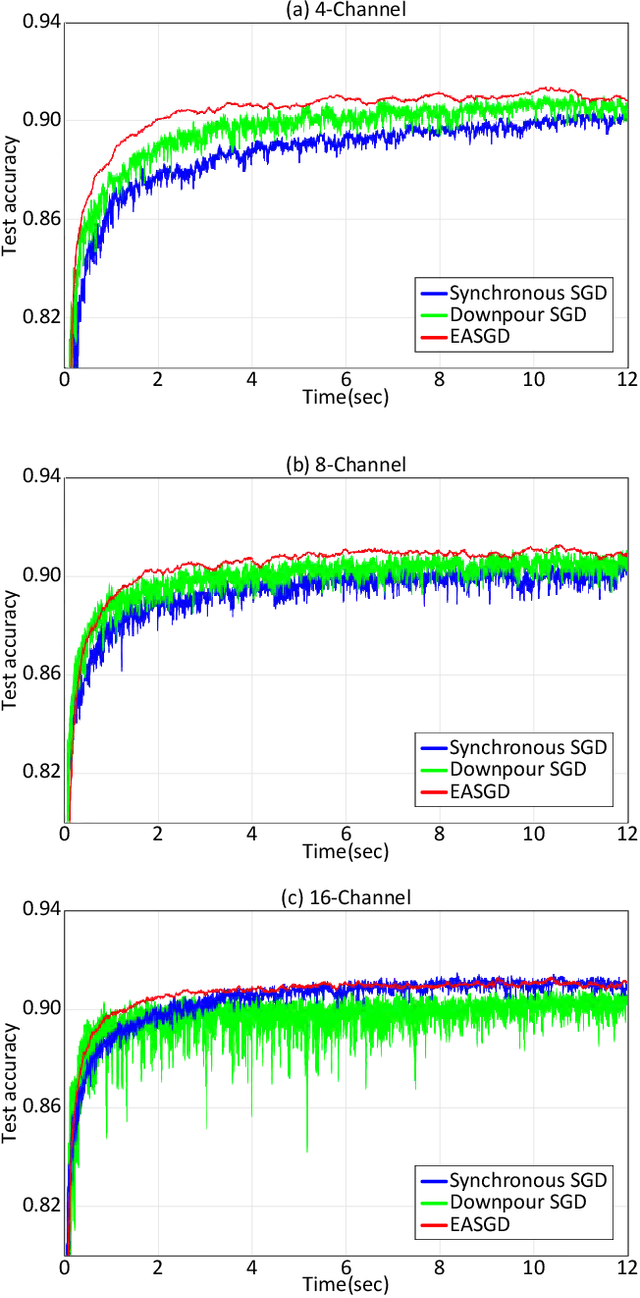
Near-data processing (NDP) refers to augmenting memory or storage with processing power. Despite its potential for acceleration computing and reducing power requirements, only limited progress has been made in popularizing NDP for various reasons. Recently, two major changes have occurred that have ignited renewed interest and caused a resurgence of NDP. The first is the success of machine learning (ML), which often demands a great deal of computation for training, requiring frequent transfers of big data. The second is the popularity of NAND flash-based solid-state drives (SSDs) containing multicore processors that can accommodate extra computation for data processing. In this paper, we evaluate the potential of NDP for ML using a new SSD platform that allows us to simulate instorage processing (ISP) of ML workloads. Our platform (named ISP-ML) is a full-fledged simulator of a realistic multi-channel SSD that can execute various ML algorithms using data stored in the SSD. To conduct a thorough performance analysis and an in-depth comparison with alternative techniques, we focus on a specific algorithm: stochastic gradient descent (SGD), which is the de facto standard for training differentiable models such as logistic regression and neural networks. We implement and compare three SGD variants (synchronous, Downpour, and elastic averaging) using ISP-ML, exploiting the multiple NAND channels to parallelize SGD. In addition, we compare the performance of ISP and that of conventional in-host processing, revealing the advantages of ISP. Based on the advantages and limitations identified through our experiments, we further discuss directions for future research on ISP for accelerating ML.