 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Speech-to-Spatial: Grounding Utterances on A Live Shared View with Augmented Reality
Feb 03, 2026We introduce Speech-to-Spatial, a referent disambiguation framework that converts verbal remote-assistance instructions into spatially grounded AR guidance. Unlike prior systems that rely on additional cues (e.g., gesture, gaze) or manual expert annotations, Speech-to-Spatial infers the intended target solely from spoken references (speech input). Motivated by our formative study of speech referencing patterns, we characterize recurring ways people specify targets (Direct Attribute, Relational, Remembrance, and Chained) and ground them to our object-centric relational graph. Given an utterance, referent cues are parsed and rendered as persistent in-situ AR visual guidance, reducing iterative micro-guidance ("a bit more to the right", "now, stop.") during remote guidance. We demonstrate the use cases of our system with remote guided assistance and intent disambiguation scenarios. Our evaluation shows that Speechto-Spatial improves task efficiency, reduces cognitive load, and enhances usability compared to a conventional voice-only baseline, transforming disembodied verbal instruction into visually explainable, actionable guidance on a live shared view.
SpeechLess: Micro-utterance with Personalized Spatial Memory-aware Assistant in Everyday Augmented Reality
Jan 31, 2026Speaking aloud to a wearable AR assistant in public can be socially awkward, and re-articulating the same requests every day creates unnecessary effort. We present SpeechLess, a wearable AR assistant that introduces a speech-based intent granularity control paradigm grounded in personalized spatial memory. SpeechLess helps users "speak less," while still obtaining the information they need, and supports gradual explicitation of intent when more complex expression is required. SpeechLess binds prior interactions to multimodal personal context-space, time, activity, and referents-to form spatial memories, and leverages them to extrapolate missing intent dimensions from under-specified user queries. This enables users to dynamically adjust how explicitly they express their informational needs, from full-utterance to micro/zero-utterance interaction. We motivate our design through a week-long formative study using a commercial smart glasses platform, revealing discomfort with public voice use, frustration with repetitive speech, and hardware constraints. Building on these insights, we design SpeechLess, and evaluate it through controlled lab and in-the-wild studies. Our results indicate that regulated speech-based interaction, can improve everyday information access, reduce articulation effort, and support socially acceptable use without substantially degrading perceived usability or intent resolution accuracy across diverse everyday environments.
Evaluating Spatialized Auditory Cues for Rapid Attention Capture in XR
Jan 29, 2026In time-critical eXtended reality (XR) scenarios where users must rapidly reorient their attention to hazards, alerts, or instructions while engaged in a primary task, spatial audio can provide an immediate directional cue without occupying visual bandwidth. However, such scenarios can afford only a brief auditory exposure, requiring users to interpret sound direction quickly and without extended listening or head-driven refinement. This paper reports a controlled exploratory study of rapid spatial-audio localization in XR. Using HRTF-rendered broadband stimuli presented from a semi-dense set of directions around the listener, we quantify how accurately users can infer coarse direction from brief audio alone. We further examine the effects of short-term visuo-auditory feedback training as a lightweight calibration mechanism. Our findings show that brief spatial cues can convey coarse directional information, and that even short calibration can improve users' perception of aural signals. While these results highlight the potential of spatial audio for rapid attention guidance, they also show that auditory cues alone may not provide sufficient precision for complex or high-stakes tasks, and that spatial audio may be most effective when complemented by other sensory modalities or visual cues, without relying on head-driven refinement. We leverage this study on spatial audio as a preliminary investigation into a first-stage attention-guidance channel for wearable XR (e.g., VR head-mounted displays and AR smart glasses), and provide design insights on stimulus selection and calibration for time-critical use.
Memento: Towards Proactive Visualization of Everyday Memories with Personal Wearable AR Assistant
Jan 27, 2026We introduce Memento, a conversational AR assistant that permanently captures and memorizes user's verbal queries alongside their spatiotemporal and activity contexts. By storing these "memories," Memento discovers connections between users' recurring interests and the contexts that trigger them. Upon detection of similar or identical spatiotemporal activity, Memento proactively recalls user interests and delivers up-to-date responses through AR, seamlessly integrating AR experience into their daily routine. Unlike prior work, each interaction in Memento is not a transient event, but a connected series of interactions with coherent long--term perspective, tailored to the user's broader multimodal (visual, spatial, temporal, and embodied) context. We conduct preliminary evaluation through user feedbacks with participants of diverse expertise in immersive apps, and explore the value of proactive context-aware AR assistant in everyday settings. We share our findings and challenges in designing a proactive, context-aware AR system.
Explainable XR: Understanding User Behaviors of XR Environments using LLM-assisted Analytics Framework
Jan 23, 2025



We present Explainable XR, an end-to-end framework for analyzing user behavior in diverse eXtended Reality (XR) environments by leveraging Large Language Models (LLMs) for data interpretation assistance. Existing XR user analytics frameworks face challenges in handling cross-virtuality - AR, VR, MR - transitions, multi-user collaborative application scenarios, and the complexity of multimodal data. Explainable XR addresses these challenges by providing a virtuality-agnostic solution for the collection, analysis, and visualization of immersive sessions. We propose three main components in our framework: (1) A novel user data recording schema, called User Action Descriptor (UAD), that can capture the users' multimodal actions, along with their intents and the contexts; (2) a platform-agnostic XR session recorder, and (3) a visual analytics interface that offers LLM-assisted insights tailored to the analysts' perspectives, facilitating the exploration and analysis of the recorded XR session data. We demonstrate the versatility of Explainable XR by demonstrating five use-case scenarios, in both individual and collaborative XR applications across virtualities. Our technical evaluation and user studies show that Explainable XR provides a highly usable analytics solution for understanding user actions and delivering multifaceted, actionable insights into user behaviors in immersive environments.
Scalable Smartphone Cluster for Deep Learning
Oct 23, 2021
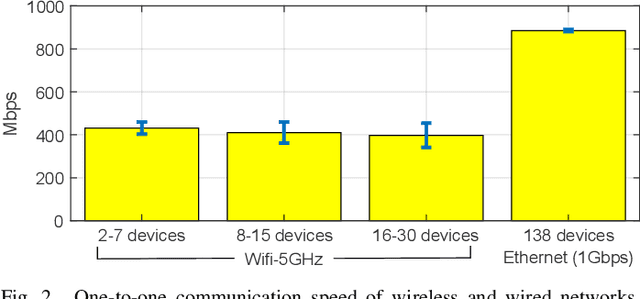

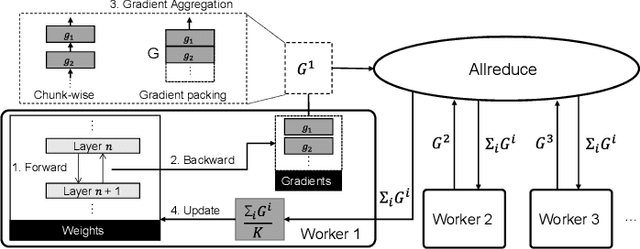
Various deep learning applications on smartphones have been rapidly rising, but training deep neural networks (DNNs) has too large computational burden to be executed on a single smartphone. A portable cluster, which connects smartphones with a wireless network and supports parallel computation using them, can be a potential approach to resolve the issue. However, by our findings, the limitations of wireless communication restrict the cluster size to up to 30 smartphones. Such small-scale clusters have insufficient computational power to train DNNs from scratch. In this paper, we propose a scalable smartphone cluster enabling deep learning training by removing the portability to increase its computational efficiency. The cluster connects 138 Galaxy S10+ devices with a wired network using Ethernet. We implemented large-batch synchronous training of DNNs based on Caffe, a deep learning library. The smartphone cluster yielded 90% of the speed of a P100 when training ResNet-50, and approximately 43x speed-up of a V100 when training MobileNet-v1.