 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedClassAvg: Local Representation Learning for Personalized Federated Learning on Heterogeneous Neural Networks
Oct 27, 2022



Personalized federated learning is aimed at allowing numerous clients to train personalized models while participating in collaborative training in a communication-efficient manner without exchanging private data. However, many personalized federated learning algorithms assume that clients have the same neural network architecture, and those for heterogeneous models remain understudied. In this study, we propose a novel personalized federated learning method called federated classifier averaging (FedClassAvg). Deep neural networks for supervised learning tasks consist of feature extractor and classifier layers. FedClassAvg aggregates classifier weights as an agreement on decision boundaries on feature spaces so that clients with not independently and identically distributed (non-iid) data can learn about scarce labels. In addition, local feature representation learning is applied to stabilize the decision boundaries and improve the local feature extraction capabilities for clients. While the existing methods require the collection of auxiliary data or model weights to generate a counterpart, FedClassAvg only requires clients to communicate with a couple of fully connected layers, which is highly communication-efficient. Moreover, FedClassAvg does not require extra optimization problems such as knowledge transfer, which requires intensive computation overhead. We evaluated FedClassAvg through extensive experiments and demonstrated it outperforms the current state-of-the-art algorithms on heterogeneous personalized federated learning tasks.
Scalable Smartphone Cluster for Deep Learning
Oct 23, 2021
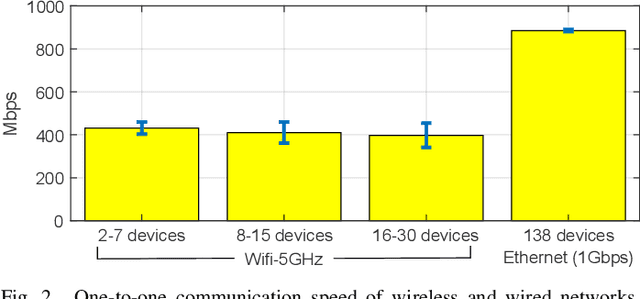

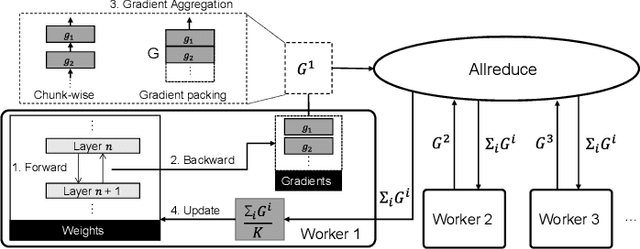
Various deep learning applications on smartphones have been rapidly rising, but training deep neural networks (DNNs) has too large computational burden to be executed on a single smartphone. A portable cluster, which connects smartphones with a wireless network and supports parallel computation using them, can be a potential approach to resolve the issue. However, by our findings, the limitations of wireless communication restrict the cluster size to up to 30 smartphones. Such small-scale clusters have insufficient computational power to train DNNs from scratch. In this paper, we propose a scalable smartphone cluster enabling deep learning training by removing the portability to increase its computational efficiency. The cluster connects 138 Galaxy S10+ devices with a wired network using Ethernet. We implemented large-batch synchronous training of DNNs based on Caffe, a deep learning library. The smartphone cluster yielded 90% of the speed of a P100 when training ResNet-50, and approximately 43x speed-up of a V100 when training MobileNet-v1.
Security and Privacy Issues in Deep Learning
Jul 31, 2018
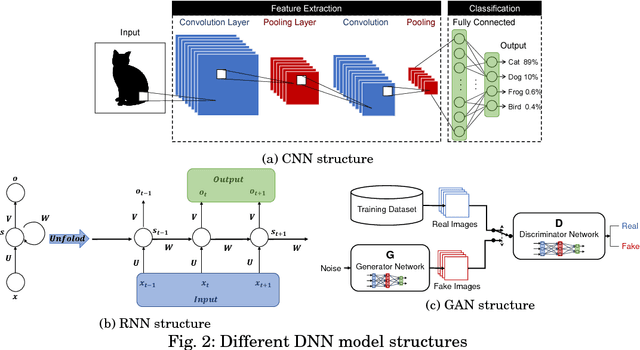
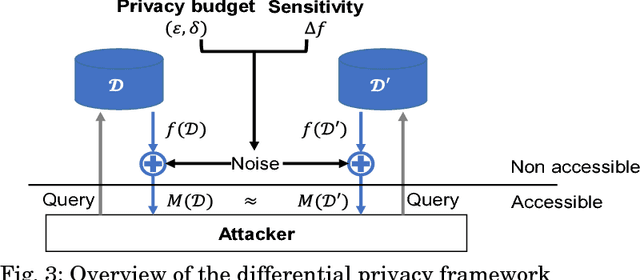
With the development of machine learning, expectations for artificial intelligence (AI) technology are increasing day by day. In particular, deep learning has shown enriched performance results in a variety of fields. There are many applications that are closely related to our daily life, such as making significant decisions in application area based on predictions or classifications, in which a deep learning (DL) model could be relevant. Hence, if a DL model causes mispredictions or misclassifications due to malicious external influences, it can cause very large difficulties in real life. Moreover, training deep learning models involves relying on an enormous amount of data and the training data often includes sensitive information. Therefore, deep learning models should not expose the privacy of such data. In this paper, we reviewed the threats and developed defense methods on the security of the models and the data privacy under the notion of SPAI: Secure and Private AI. We also discuss current challenges and open issues.
Streaming MANN: A Streaming-Based Inference for Energy-Efficient Memory-Augmented Neural Networks
May 21, 2018
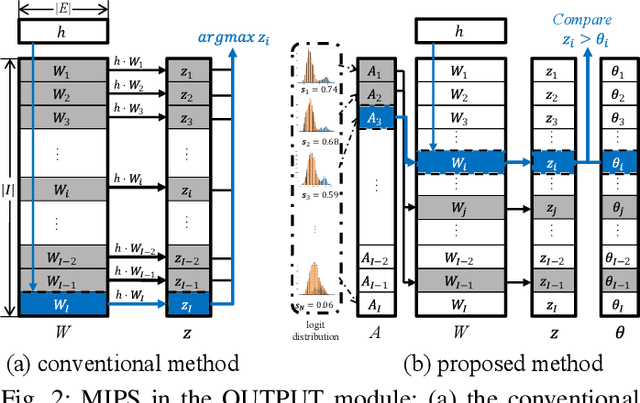


With the successful development of artificial intelligence using deep learning, there has been growing interest in its deployment. The mobile environment is the closest hardware platform to real life, and it has become an important platform for the success or failure of artificial intelligence. Memory-augmented neural networks (MANNs) are neural networks proposed to efficiently handle question-and-answer (Q&A) tasks, well-suited for mobile devices. As a MANN requires various types of operations and recurrent data paths, it is difficult to accelerate the inference in the structure designed for other conventional neural network models, which is one of the biggest obstacles to deploying MANNs in mobile environments. To address the aforementioned issues, we propose Streaming MANN. This is the first attempt to implement and demonstrate the architecture for energy-efficient inference of MANNs with the concept of streaming processing. To achieve the full potential of the streaming process, we propose a novel approach, called inference thresholding, using Bayesian approach considering the characteristics of natural language processing (NLP) tasks. To evaluate our proposed approaches, we implemented the architecture and method in a field-programmable gate array (FPGA) which is suitable for streaming processing. We measured the execution time and power consumption of the inference for the bAbI dataset. The experimental results showed that the performance efficiency per energy (FLOPS/kJ) of the Streaming MANN increased by a factor of up to about 126 compared to the results of NVIDIA TITAN V, and up to 140 if inference thresholding is applied.
Homomorphic Parameter Compression for Distributed Deep Learning Training
Nov 28, 2017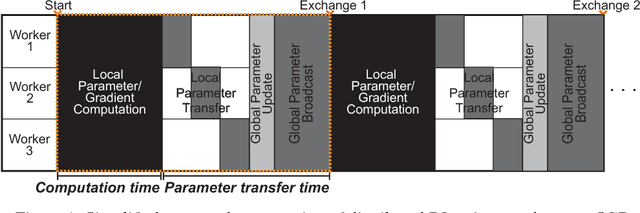



Distributed training of deep neural networks has received significant research interest, and its major approaches include implementations on multiple GPUs and clusters. Parallelization can dramatically improve the efficiency of training deep and complicated models with large-scale data. A fundamental barrier against the speedup of DNN training, however, is the trade-off between computation and communication time. In other words, increasing the number of worker nodes decreases the time consumed in computation while simultaneously increasing communication overhead under constrained network bandwidth, especially in commodity hardware environments. To alleviate this trade-off, we suggest the idea of homomorphic parameter compression, which compresses parameters with the least expense and trains the DNN with the compressed representation. Although the specific method is yet to be discovered, we demonstrate that there is a high probability that the homomorphism can reduce the communication overhead, thanks to little compression and decompression times. We also provide theoretical speedup of homomorphic compression.
DeepSpark: A Spark-Based Distributed Deep Learning Framework for Commodity Clusters
Oct 01, 2016
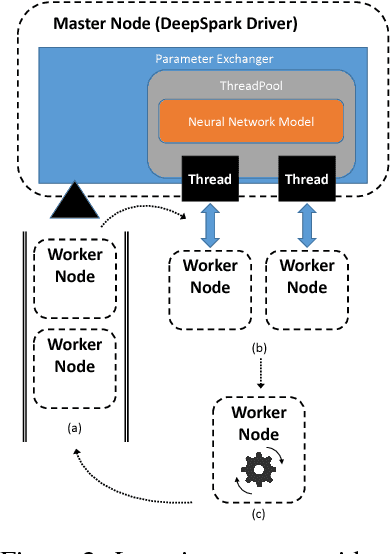

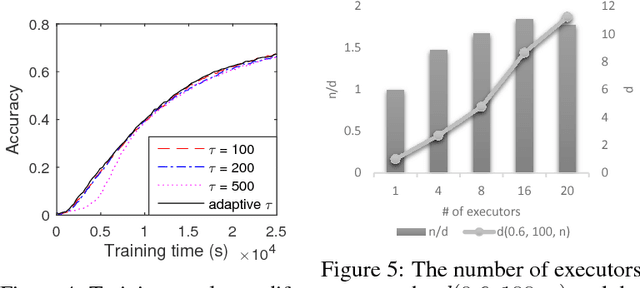
The increasing complexity of deep neural networks (DNNs) has made it challenging to exploit existing large-scale data processing pipelines for handling massive data and parameters involved in DNN training. Distributed computing platforms and GPGPU-based acceleration provide a mainstream solution to this computational challenge. In this paper, we propose DeepSpark, a distributed and parallel deep learning framework that exploits Apache Spark on commodity clusters. To support parallel operations, DeepSpark automatically distributes workloads and parameters to Caffe/Tensorflow-running nodes using Spark, and iteratively aggregates training results by a novel lock-free asynchronous variant of the popular elastic averaging stochastic gradient descent based update scheme, effectively complementing the synchronized processing capabilities of Spark. DeepSpark is an on-going project, and the current release is available at http://deepspark.snu.ac.kr.