 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomomorphic Parameter Compression for Distributed Deep Learning Training
Paper and Code
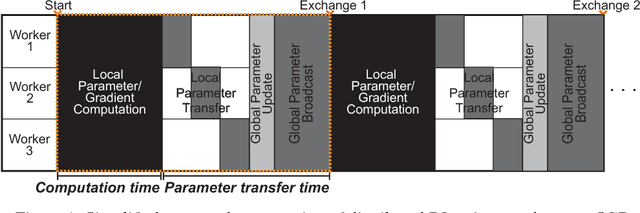



Distributed training of deep neural networks has received significant research interest, and its major approaches include implementations on multiple GPUs and clusters. Parallelization can dramatically improve the efficiency of training deep and complicated models with large-scale data. A fundamental barrier against the speedup of DNN training, however, is the trade-off between computation and communication time. In other words, increasing the number of worker nodes decreases the time consumed in computation while simultaneously increasing communication overhead under constrained network bandwidth, especially in commodity hardware environments. To alleviate this trade-off, we suggest the idea of homomorphic parameter compression, which compresses parameters with the least expense and trains the DNN with the compressed representation. Although the specific method is yet to be discovered, we demonstrate that there is a high probability that the homomorphism can reduce the communication overhead, thanks to little compression and decompression times. We also provide theoretical speedup of homomorphic compression.