 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Summarize Long Texts with Memory Compression and Transfer
Oct 21, 2020



We introduce Mem2Mem, a memory-to-memory mechanism for hierarchical recurrent neural network based encoder decoder architectures and we explore its use for abstractive document summarization. Mem2Mem transfers "memories" via readable/writable external memory modules that augment both the encoder and decoder. Our memory regularization compresses an encoded input article into a more compact set of sentence representations. Most importantly, the memory compression step performs implicit extraction without labels, sidestepping issues with suboptimal ground-truth data and exposure bias of hybrid extractive-abstractive summarization techniques. By allowing the decoder to read/write over the encoded input memory, the model learns to read salient information about the input article while keeping track of what has been generated. Our Mem2Mem approach yields results that are competitive with state of the art transformer based summarization methods, but with 16 times fewer parameters
On the impressive performance of randomly weighted encoders in summarization tasks
Feb 21, 2020


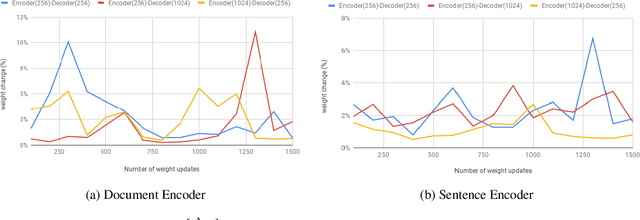
In this work, we investigate the performance of untrained randomly initialized encoders in a general class of sequence to sequence models and compare their performance with that of fully-trained encoders on the task of abstractive summarization. We hypothesize that random projections of an input text have enough representational power to encode the hierarchical structure of sentences and semantics of documents. Using a trained decoder to produce abstractive text summaries, we empirically demonstrate that architectures with untrained randomly initialized encoders perform competitively with respect to the equivalent architectures with fully-trained encoders. We further find that the capacity of the encoder not only improves overall model generalization but also closes the performance gap between untrained randomly initialized and full-trained encoders. To our knowledge, it is the first time that general sequence to sequence models with attention are assessed for trained and randomly projected representations on abstractive summarization.
Building a Neural Machine Translation System Using Only Synthetic Parallel Data
Sep 17, 2017
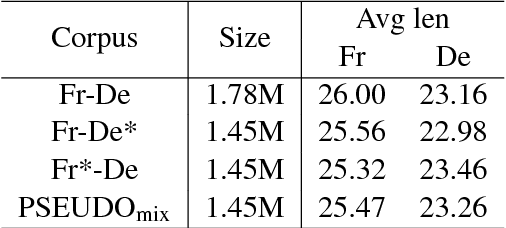


Recent works have shown that synthetic parallel data automatically generated by translation models can be effective for various neural machine translation (NMT) issues. In this study, we build NMT systems using only synthetic parallel data. As an efficient alternative to real parallel data, we also present a new type of synthetic parallel corpus. The proposed pseudo parallel data are distinct from previous works in that ground truth and synthetic examples are mixed on both sides of sentence pairs. Experiments on Czech-German and French-German translations demonstrate the efficacy of the proposed pseudo parallel corpus, which shows not only enhanced results for bidirectional translation tasks but also substantial improvement with the aid of a ground truth real parallel corpus.
DeepSpark: A Spark-Based Distributed Deep Learning Framework for Commodity Clusters
Oct 01, 2016
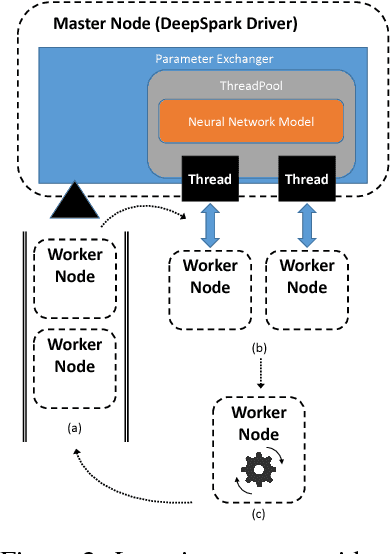

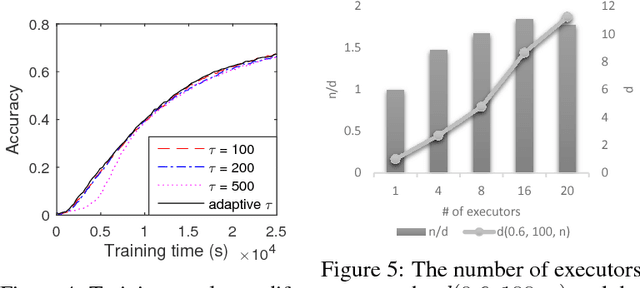
The increasing complexity of deep neural networks (DNNs) has made it challenging to exploit existing large-scale data processing pipelines for handling massive data and parameters involved in DNN training. Distributed computing platforms and GPGPU-based acceleration provide a mainstream solution to this computational challenge. In this paper, we propose DeepSpark, a distributed and parallel deep learning framework that exploits Apache Spark on commodity clusters. To support parallel operations, DeepSpark automatically distributes workloads and parameters to Caffe/Tensorflow-running nodes using Spark, and iteratively aggregates training results by a novel lock-free asynchronous variant of the popular elastic averaging stochastic gradient descent based update scheme, effectively complementing the synchronized processing capabilities of Spark. DeepSpark is an on-going project, and the current release is available at http://deepspark.snu.ac.kr.