 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Neural Machine Translation System Using Only Synthetic Parallel Data
Paper and Code
Sep 17, 2017
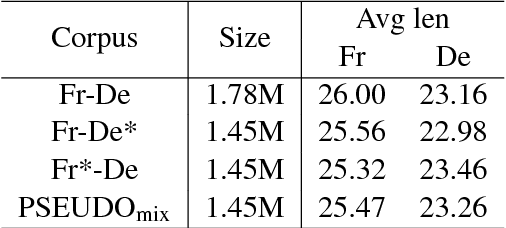


Recent works have shown that synthetic parallel data automatically generated by translation models can be effective for various neural machine translation (NMT) issues. In this study, we build NMT systems using only synthetic parallel data. As an efficient alternative to real parallel data, we also present a new type of synthetic parallel corpus. The proposed pseudo parallel data are distinct from previous works in that ground truth and synthetic examples are mixed on both sides of sentence pairs. Experiments on Czech-German and French-German translations demonstrate the efficacy of the proposed pseudo parallel corpus, which shows not only enhanced results for bidirectional translation tasks but also substantial improvement with the aid of a ground truth real parallel corpus.