 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Data Processing for Differentiable Machine Learning Models
Apr 28, 2017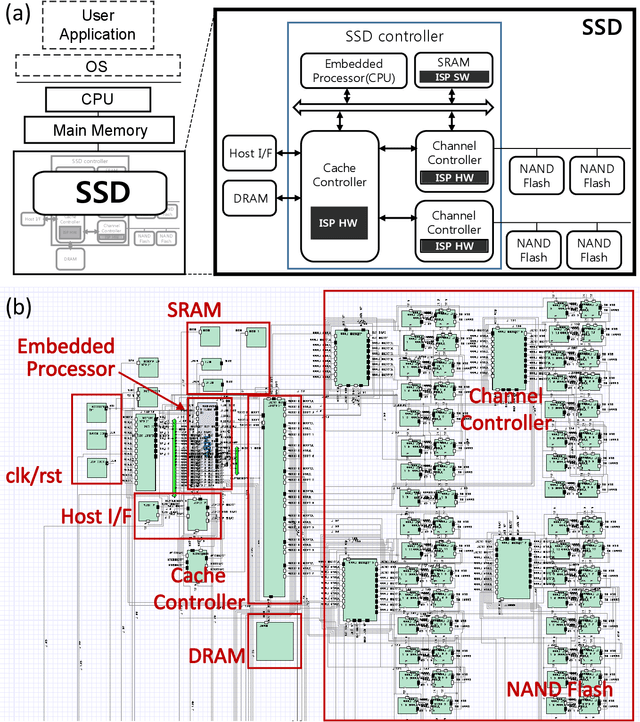

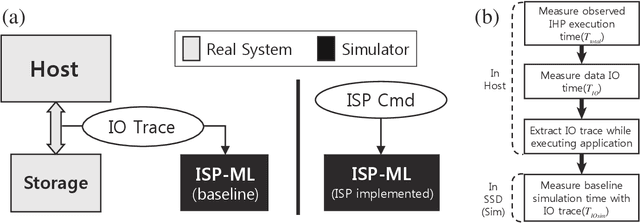
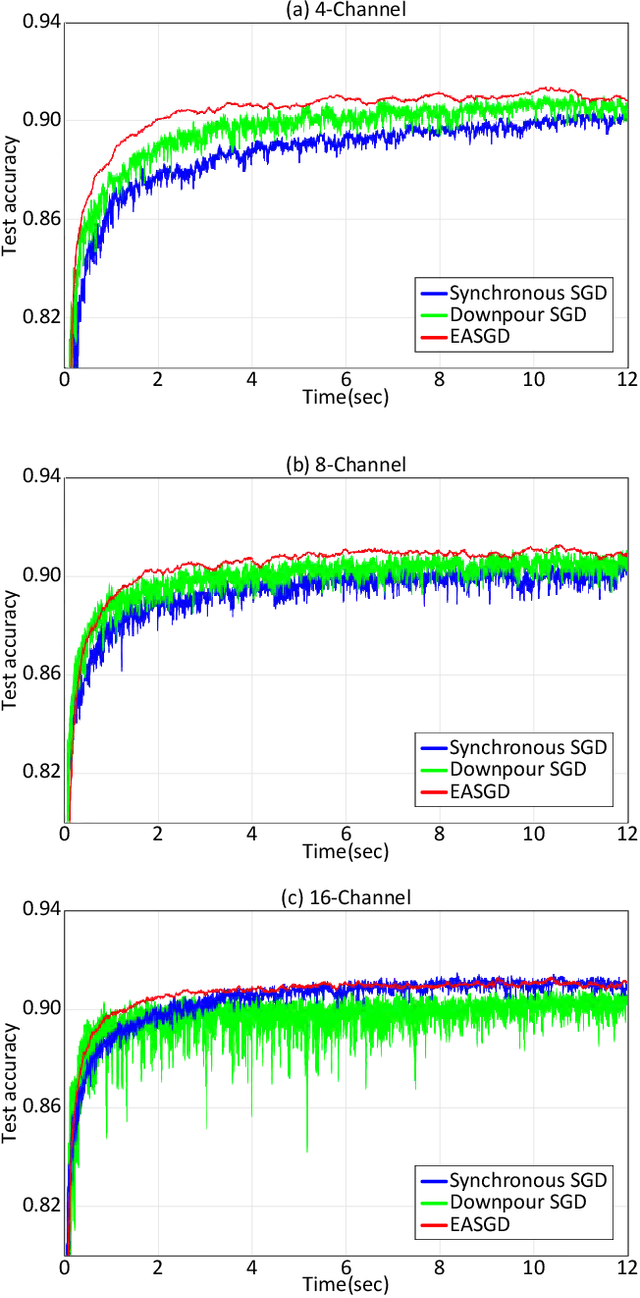
Near-data processing (NDP) refers to augmenting memory or storage with processing power. Despite its potential for acceleration computing and reducing power requirements, only limited progress has been made in popularizing NDP for various reasons. Recently, two major changes have occurred that have ignited renewed interest and caused a resurgence of NDP. The first is the success of machine learning (ML), which often demands a great deal of computation for training, requiring frequent transfers of big data. The second is the popularity of NAND flash-based solid-state drives (SSDs) containing multicore processors that can accommodate extra computation for data processing. In this paper, we evaluate the potential of NDP for ML using a new SSD platform that allows us to simulate instorage processing (ISP) of ML workloads. Our platform (named ISP-ML) is a full-fledged simulator of a realistic multi-channel SSD that can execute various ML algorithms using data stored in the SSD. To conduct a thorough performance analysis and an in-depth comparison with alternative techniques, we focus on a specific algorithm: stochastic gradient descent (SGD), which is the de facto standard for training differentiable models such as logistic regression and neural networks. We implement and compare three SGD variants (synchronous, Downpour, and elastic averaging) using ISP-ML, exploiting the multiple NAND channels to parallelize SGD. In addition, we compare the performance of ISP and that of conventional in-host processing, revealing the advantages of ISP. Based on the advantages and limitations identified through our experiments, we further discuss directions for future research on ISP for accelerating ML.
An Efficient Approach to Boosting Performance of Deep Spiking Network Training
Nov 08, 2016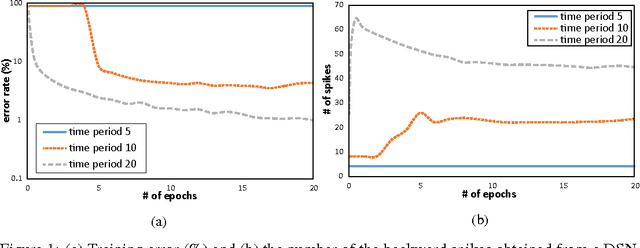



Nowadays deep learning is dominating the field of machine learning with state-of-the-art performance in various application areas. Recently, spiking neural networks (SNNs) have been attracting a great deal of attention, notably owning to their power efficiency, which can potentially allow us to implement a low-power deep learning engine suitable for real-time/mobile applications. However, implementing SNN-based deep learning remains challenging, especially gradient-based training of SNNs by error backpropagation. We cannot simply propagate errors through SNNs in conventional way because of the property of SNNs that process discrete data in the form of a series. Consequently, most of the previous studies employ a workaround technique, which first trains a conventional weighted-sum deep neural network and then maps the learning weights to the SNN under training, instead of training SNN parameters directly. In order to eliminate this workaround, recently proposed is a new class of SNN named deep spiking networks (DSNs), which can be trained directly (without a mapping from conventional deep networks) by error backpropagation with stochastic gradient descent. In this paper, we show that the initialization of the membrane potential on the backward path is an important step in DSN training, through diverse experiments performed under various conditions. Furthermore, we propose a simple and efficient method that can improve DSN training by controlling the initial membrane potential on the backward path. In our experiments, adopting the proposed approach allowed us to boost the performance of DSN training in terms of converging time and accuracy.