 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaCluster: Enabling Deep Compression of Kolmogorov-Arnold Network
Oct 21, 2025Kolmogorov-Arnold Networks (KANs) replace scalar weights with per-edge vectors of basis coefficients, thereby boosting expressivity and accuracy but at the same time resulting in a multiplicative increase in parameters and memory. We propose MetaCluster, a framework that makes KANs highly compressible without sacrificing accuracy. Specifically, a lightweight meta-learner, trained jointly with the KAN, is used to map low-dimensional embedding to coefficient vectors, shaping them to lie on a low-dimensional manifold that is amenable to clustering. We then run K-means in coefficient space and replace per-edge vectors with shared centroids. Afterwards, the meta-learner can be discarded, and a brief fine-tuning of the centroid codebook recovers any residual accuracy loss. The resulting model stores only a small codebook and per-edge indices, exploiting the vector nature of KAN parameters to amortize storage across multiple coefficients. On MNIST, CIFAR-10, and CIFAR-100, across standard KANs and ConvKANs using multiple basis functions, MetaCluster achieves a reduction of up to 80$\times$ in parameter storage, with no loss in accuracy. Code will be released upon publication.
BeaverTalk: Oregon State University's IWSLT 2025 Simultaneous Speech Translation System
May 29, 2025This paper discusses the construction, fine-tuning, and deployment of BeaverTalk, a cascaded system for speech-to-text translation as part of the IWSLT 2025 simultaneous translation task. The system architecture employs a VAD segmenter for breaking a speech stream into segments, Whisper Large V2 for automatic speech recognition (ASR), and Gemma 3 12B for simultaneous translation. Regarding the simultaneous translation LLM, it is fine-tuned via low-rank adaptors (LoRAs) for a conversational prompting strategy that leverages a single prior-sentence memory bank from the source language as context. The cascaded system participated in the English$\rightarrow$German and English$\rightarrow$Chinese language directions for both the low and high latency regimes. In particular, on the English$\rightarrow$German task, the system achieves a BLEU of 24.64 and 27.83 at a StreamLAAL of 1837.86 and 3343.73, respectively. Then, on the English$\rightarrow$Chinese task, the system achieves a BLEU of 34.07 and 37.23 at a StreamLAAL of 2216.99 and 3521.35, respectively.
FlashKAT: Understanding and Addressing Performance Bottlenecks in the Kolmogorov-Arnold Transformer
May 20, 2025The Kolmogorov-Arnold Network (KAN) has been gaining popularity as an alternative to the multi-layer perceptron (MLP) with its increased expressiveness and interpretability. However, the KAN can be orders of magnitude slower due to its increased computational cost and training instability, limiting its applicability to larger-scale tasks. Recently, the Kolmogorov-Arnold Transformer (KAT) has been proposed, which can achieve FLOPs similar to the traditional Transformer with MLPs by leveraging Group-Rational KAN (GR-KAN). Unfortunately, despite the comparable FLOPs, our characterizations reveal that the KAT is still 123x slower in training speeds, indicating that there are other performance bottlenecks beyond FLOPs. In this paper, we conduct a series of experiments to understand the root cause of the slowdown in KAT. We uncover that the slowdown can be isolated to memory stalls and, more specifically, in the backward pass of GR-KAN caused by inefficient gradient accumulation. To address this memory bottleneck, we propose FlashKAT, which builds on our restructured kernel that minimizes gradient accumulation with atomic adds and accesses to slow memory. Evaluations demonstrate that FlashKAT can achieve a training speedup of 86.5x compared with the state-of-the-art KAT, while reducing rounding errors in the coefficient gradients. Our code is available at https://github.com/OSU-STARLAB/FlashKAT.
Towards Universal Semantics With Large Language Models
May 17, 2025The Natural Semantic Metalanguage (NSM) is a linguistic theory based on a universal set of semantic primes: simple, primitive word-meanings that have been shown to exist in most, if not all, languages of the world. According to this framework, any word, regardless of complexity, can be paraphrased using these primes, revealing a clear and universally translatable meaning. These paraphrases, known as explications, can offer valuable applications for many natural language processing (NLP) tasks, but producing them has traditionally been a slow, manual process. In this work, we present the first study of using large language models (LLMs) to generate NSM explications. We introduce automatic evaluation methods, a tailored dataset for training and evaluation, and fine-tuned models for this task. Our 1B and 8B models outperform GPT-4o in producing accurate, cross-translatable explications, marking a significant step toward universal semantic representation with LLMs and opening up new possibilities for applications in semantic analysis, translation, and beyond.
ML For Hardware Design Interpretability: Challenges and Opportunities
Apr 11, 2025



The increasing size and complexity of machine learning (ML) models have driven the growing need for custom hardware accelerators capable of efficiently supporting ML workloads. However, the design of such accelerators remains a time-consuming process, heavily relying on engineers to manually ensure design interpretability through clear documentation and effective communication. Recent advances in large language models (LLMs) offer a promising opportunity to automate these design interpretability tasks, particularly the generation of natural language descriptions for register-transfer level (RTL) code, what we refer to as "RTL-to-NL tasks." In this paper, we examine how design interpretability, particularly in RTL-to-NL tasks, influences the efficiency of the hardware design process. We review existing work adapting LLMs for these tasks, highlight key challenges that remain unaddressed, including those related to data, computation, and model development, and identify opportunities to address them. By doing so, we aim to guide future research in leveraging ML to automate RTL-to-NL tasks and improve hardware design interpretability, thereby accelerating the hardware design process and meeting the increasing demand for custom hardware accelerators in machine learning and beyond.
Hessian-aware Training for Enhancing DNNs Resilience to Parameter Corruptions
Apr 02, 2025



Deep neural networks are not resilient to parameter corruptions: even a single-bitwise error in their parameters in memory can cause an accuracy drop of over 10%, and in the worst cases, up to 99%. This susceptibility poses great challenges in deploying models on computing platforms, where adversaries can induce bit-flips through software or bitwise corruptions may occur naturally. Most prior work addresses this issue with hardware or system-level approaches, such as integrating additional hardware components to verify a model's integrity at inference. However, these methods have not been widely deployed as they require infrastructure or platform-wide modifications. In this paper, we propose a new approach to addressing this issue: training models to be more resilient to bitwise corruptions to their parameters. Our approach, Hessian-aware training, promotes models with $flatter$ loss surfaces. We show that, while there have been training methods, designed to improve generalization through Hessian-based approaches, they do not enhance resilience to parameter corruptions. In contrast, models trained with our method demonstrate increased resilience to parameter corruptions, particularly with a 20$-$50% reduction in the number of bits whose individual flipping leads to a 90$-$100% accuracy drop. Moreover, we show the synergy between ours and existing hardware and system-level defenses.
MatrixKAN: Parallelized Kolmogorov-Arnold Network
Feb 11, 2025Kolmogorov-Arnold Networks (KAN) are a new class of neural network architecture representing a promising alternative to the Multilayer Perceptron (MLP), demonstrating improved expressiveness and interpretability. However, KANs suffer from slow training and inference speeds relative to MLPs due in part to the recursive nature of the underlying B-spline calculations. This issue is particularly apparent with respect to KANs utilizing high-degree B-splines, as the number of required non-parallelizable recursions is proportional to B-spline degree. We solve this issue by proposing MatrixKAN, a novel optimization that parallelizes B-spline calculations with matrix representation and operations, thus significantly improving effective computation time for models utilizing high-degree B-splines. In this paper, we demonstrate the superior scaling of MatrixKAN's computation time relative to B-spline degree. Further, our experiments demonstrate speedups of approximately 40x relative to KAN, with significant additional speedup potential for larger datasets or higher spline degrees.
Neurons for Neutrons: A Transformer Model for Computation Load Estimation on Domain-Decomposed Neutron Transport Problems
Nov 05, 2024Domain decomposition is a technique used to reduce memory overhead on large neutron transport problems. Currently, the optimal load-balanced processor allocation for these domains is typically determined through small-scale simulations of the problem, which can be time-consuming for researchers and must be repeated anytime a problem input is changed. We propose a Transformer model with a unique 3D input embedding, and input representations designed for domain-decomposed neutron transport problems, which can predict the subdomain computation loads generated by small-scale simulations. We demonstrate that such a model trained on domain-decomposed Small Modular Reactor (SMR) simulations achieves 98.2% accuracy while being able to skip the small-scale simulation step entirely. Tests of the model's robustness on variant fuel assemblies, other problem geometries, and changes in simulation parameters are also discussed.
LLM-Ref: Enhancing Reference Handling in Technical Writing with Large Language Models
Nov 04, 2024Large Language Models (LLMs) excel in data synthesis but can be inaccurate in domain-specific tasks, which retrieval-augmented generation (RAG) systems address by leveraging user-provided data. However, RAGs require optimization in both retrieval and generation stages, which can affect output quality. In this paper, we present LLM-Ref, a writing assistant tool that aids researchers in writing articles from multiple source documents with enhanced reference synthesis and handling capabilities. Unlike traditional RAG systems that use chunking and indexing, our tool retrieves and generates content directly from text paragraphs. This method facilitates direct reference extraction from the generated outputs, a feature unique to our tool. Additionally, our tool employs iterative response generation, effectively managing lengthy contexts within the language model's constraints. Compared to baseline RAG-based systems, our approach achieves a $3.25\times$ to $6.26\times$ increase in Ragas score, a comprehensive metric that provides a holistic view of a RAG system's ability to produce accurate, relevant, and contextually appropriate responses. This improvement shows our method enhances the accuracy and contextual relevance of writing assistance tools.
LLM-RankFusion: Mitigating Intrinsic Inconsistency in LLM-based Ranking
May 31, 2024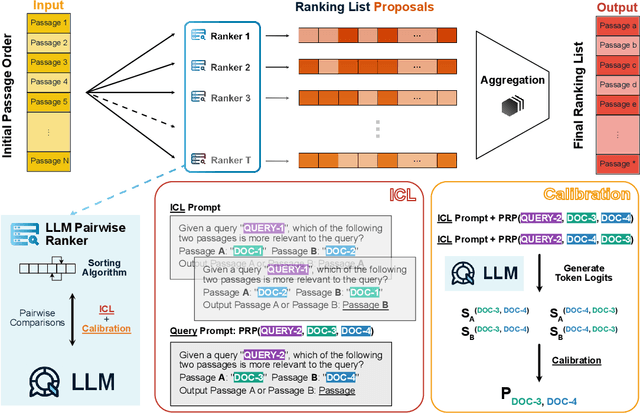
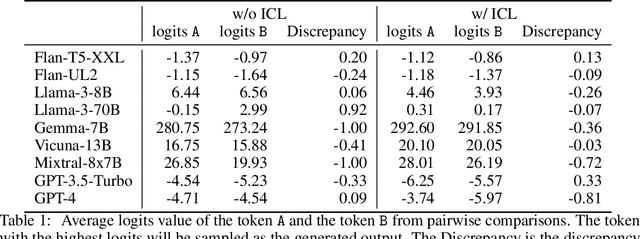
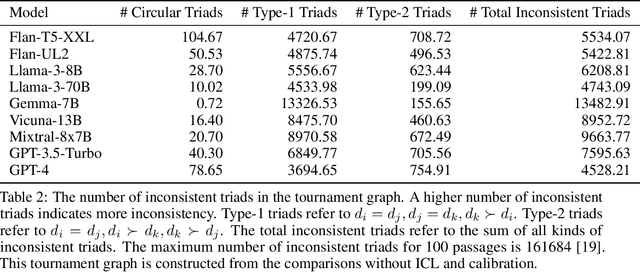
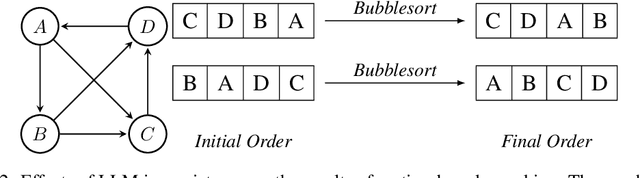
Ranking passages by prompting a large language model (LLM) can achieve promising performance in modern information retrieval (IR) systems. A common approach is to sort the ranking list by prompting LLMs for pairwise comparison. However, sorting-based methods require consistent comparisons to correctly sort the passages, which we show that LLMs often violate. We identify two kinds of intrinsic inconsistency in LLM-based pairwise comparisons: order inconsistency which leads to conflicting results when switching the passage order, and transitive inconsistency which leads to non-transitive triads among all preference pairs. In this paper, we propose LLM-RankFusion, an LLM-based ranking framework that mitigates these inconsistencies and produces a robust ranking list. LLM-RankFusion mitigates order inconsistency using in-context learning (ICL) to demonstrate order-agnostic comparisons and calibration to estimate the underlying preference probability between two passages. We then address transitive inconsistency by aggregating the ranking results from multiple rankers. In our experiments, we empirically show that LLM-RankFusion can significantly reduce inconsistent pairwise comparison results, and improve the ranking quality by making the final ranking list more robust.