 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Semantics With Large Language Models
May 17, 2025The Natural Semantic Metalanguage (NSM) is a linguistic theory based on a universal set of semantic primes: simple, primitive word-meanings that have been shown to exist in most, if not all, languages of the world. According to this framework, any word, regardless of complexity, can be paraphrased using these primes, revealing a clear and universally translatable meaning. These paraphrases, known as explications, can offer valuable applications for many natural language processing (NLP) tasks, but producing them has traditionally been a slow, manual process. In this work, we present the first study of using large language models (LLMs) to generate NSM explications. We introduce automatic evaluation methods, a tailored dataset for training and evaluation, and fine-tuned models for this task. Our 1B and 8B models outperform GPT-4o in producing accurate, cross-translatable explications, marking a significant step toward universal semantic representation with LLMs and opening up new possibilities for applications in semantic analysis, translation, and beyond.
ML For Hardware Design Interpretability: Challenges and Opportunities
Apr 11, 2025



The increasing size and complexity of machine learning (ML) models have driven the growing need for custom hardware accelerators capable of efficiently supporting ML workloads. However, the design of such accelerators remains a time-consuming process, heavily relying on engineers to manually ensure design interpretability through clear documentation and effective communication. Recent advances in large language models (LLMs) offer a promising opportunity to automate these design interpretability tasks, particularly the generation of natural language descriptions for register-transfer level (RTL) code, what we refer to as "RTL-to-NL tasks." In this paper, we examine how design interpretability, particularly in RTL-to-NL tasks, influences the efficiency of the hardware design process. We review existing work adapting LLMs for these tasks, highlight key challenges that remain unaddressed, including those related to data, computation, and model development, and identify opportunities to address them. By doing so, we aim to guide future research in leveraging ML to automate RTL-to-NL tasks and improve hardware design interpretability, thereby accelerating the hardware design process and meeting the increasing demand for custom hardware accelerators in machine learning and beyond.
LLM-RankFusion: Mitigating Intrinsic Inconsistency in LLM-based Ranking
May 31, 2024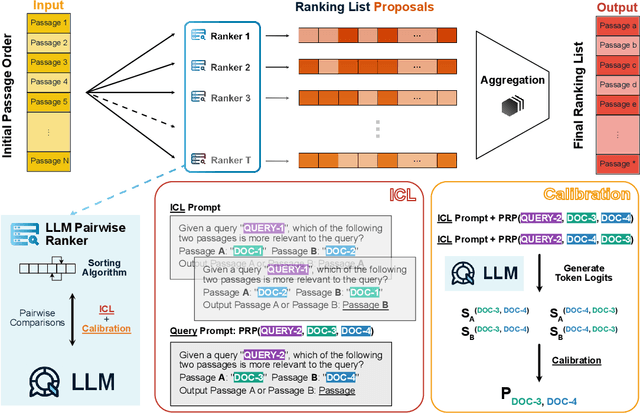
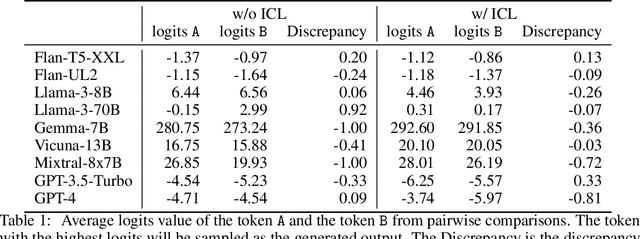
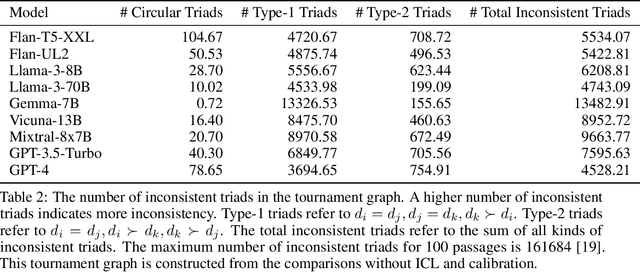
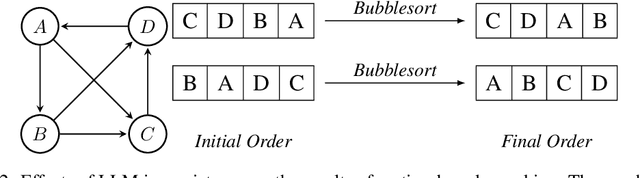
Ranking passages by prompting a large language model (LLM) can achieve promising performance in modern information retrieval (IR) systems. A common approach is to sort the ranking list by prompting LLMs for pairwise comparison. However, sorting-based methods require consistent comparisons to correctly sort the passages, which we show that LLMs often violate. We identify two kinds of intrinsic inconsistency in LLM-based pairwise comparisons: order inconsistency which leads to conflicting results when switching the passage order, and transitive inconsistency which leads to non-transitive triads among all preference pairs. In this paper, we propose LLM-RankFusion, an LLM-based ranking framework that mitigates these inconsistencies and produces a robust ranking list. LLM-RankFusion mitigates order inconsistency using in-context learning (ICL) to demonstrate order-agnostic comparisons and calibration to estimate the underlying preference probability between two passages. We then address transitive inconsistency by aggregating the ranking results from multiple rankers. In our experiments, we empirically show that LLM-RankFusion can significantly reduce inconsistent pairwise comparison results, and improve the ranking quality by making the final ranking list more robust.