 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeaverTalk: Oregon State University's IWSLT 2025 Simultaneous Speech Translation System
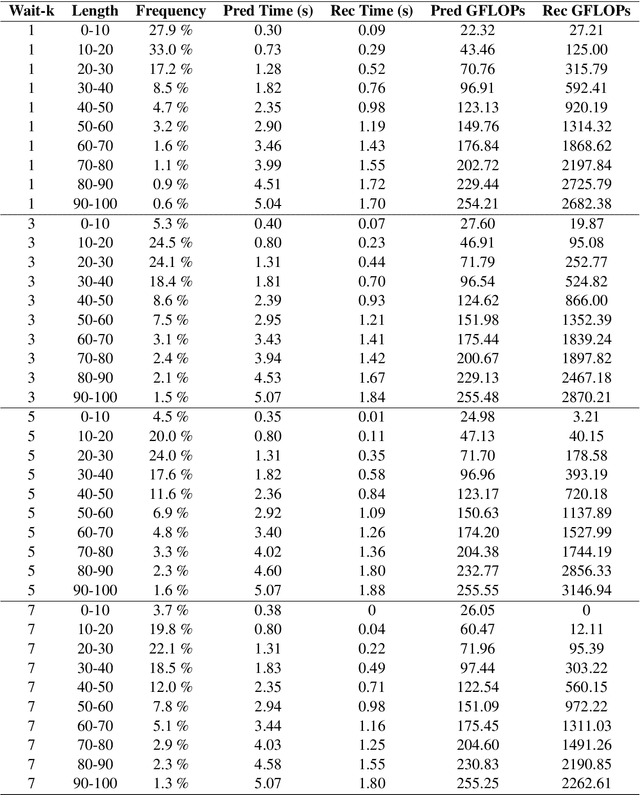
May 29, 2025This paper discusses the construction, fine-tuning, and deployment of BeaverTalk, a cascaded system for speech-to-text translation as part of the IWSLT 2025 simultaneous translation task. The system architecture employs a VAD segmenter for breaking a speech stream into segments, Whisper Large V2 for automatic speech recognition (ASR), and Gemma 3 12B for simultaneous translation. Regarding the simultaneous translation LLM, it is fine-tuned via low-rank adaptors (LoRAs) for a conversational prompting strategy that leverages a single prior-sentence memory bank from the source language as context. The cascaded system participated in the English$\rightarrow$German and English$\rightarrow$Chinese language directions for both the low and high latency regimes. In particular, on the English$\rightarrow$German task, the system achieves a BLEU of 24.64 and 27.83 at a StreamLAAL of 1837.86 and 3343.73, respectively. Then, on the English$\rightarrow$Chinese task, the system achieves a BLEU of 34.07 and 37.23 at a StreamLAAL of 2216.99 and 3521.35, respectively.
ML For Hardware Design Interpretability: Challenges and Opportunities
Apr 11, 2025



The increasing size and complexity of machine learning (ML) models have driven the growing need for custom hardware accelerators capable of efficiently supporting ML workloads. However, the design of such accelerators remains a time-consuming process, heavily relying on engineers to manually ensure design interpretability through clear documentation and effective communication. Recent advances in large language models (LLMs) offer a promising opportunity to automate these design interpretability tasks, particularly the generation of natural language descriptions for register-transfer level (RTL) code, what we refer to as "RTL-to-NL tasks." In this paper, we examine how design interpretability, particularly in RTL-to-NL tasks, influences the efficiency of the hardware design process. We review existing work adapting LLMs for these tasks, highlight key challenges that remain unaddressed, including those related to data, computation, and model development, and identify opportunities to address them. By doing so, we aim to guide future research in leveraging ML to automate RTL-to-NL tasks and improve hardware design interpretability, thereby accelerating the hardware design process and meeting the increasing demand for custom hardware accelerators in machine learning and beyond.
LeaPformer: Enabling Linear Transformers for Autoregressive and Simultaneous Tasks via Learned Proportions
May 18, 2024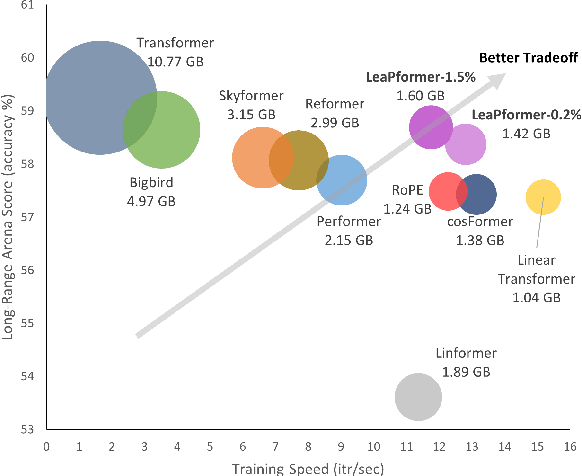
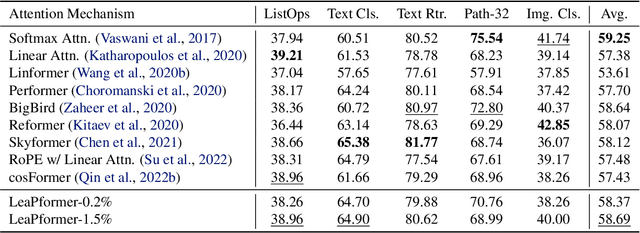
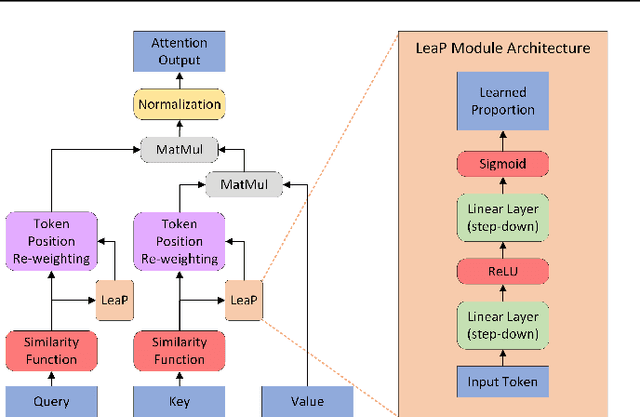
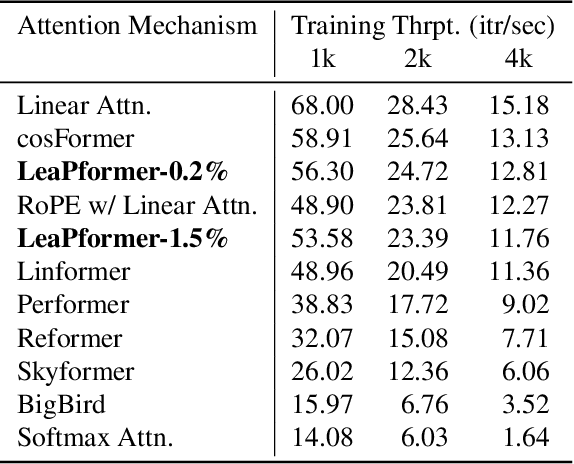
A promising approach to preserving model performance in linearized transformers is to employ position-based re-weighting functions. However, state-of-the-art re-weighting functions rely heavily on target sequence lengths, making it difficult or impossible to apply them to autoregressive and simultaneous tasks, where the target and sometimes even the input sequence length are unknown. To address this issue, we propose Learned Proportions (LeaP) and LeaPformers. Our contribution is built on two major components. First, we generalize the dependence on explicit positional representations and sequence lengths into dependence on sequence proportions for re-weighting. Second, we replace static positional representations with dynamic proportions derived via a compact module, enabling more flexible attention concentration patterns. We evaluate LeaPformer against eight representative efficient transformers on the Long-Range Arena benchmark, showing that LeaPformer achieves the best quality-throughput trade-off, as well as LeaPformer to Wikitext-103 autoregressive language modeling and simultaneous speech-to-text translation for two language pairs, achieving competitive results.
Simultaneous Masking, Not Prompting Optimization: A Paradigm Shift in Fine-tuning LLMs for Simultaneous Translation
May 16, 2024


Large language models (LLMs) have achieved state-of-the-art performance in various language processing tasks, motivating their adoption in simultaneous translation. Current fine-tuning methods to adapt LLMs for simultaneous translation focus on prompting optimization strategies using either data augmentation or prompt structure modifications. However, these methods suffer from several issues, such as an unnecessarily expanded training set, computational inefficiency from dumping the KV cache, increased prompt sizes, or restriction to a single decision policy. To eliminate these issues, we propose a new paradigm in fine-tuning LLMs for simultaneous translation, called SimulMask. It utilizes a novel attention mask technique that models simultaneous translation during fine-tuning by masking attention connections under a desired decision policy. Applying the proposed SimulMask on a Falcon LLM for the IWSLT 2017 dataset, we have observed a significant translation quality improvement compared to state-of-the-art prompting optimization strategies on three language pairs when averaged across four different latency regimes while reducing the computational cost.
Simul-LLM: A Framework for Exploring High-Quality Simultaneous Translation with Large Language Models
Dec 12, 2023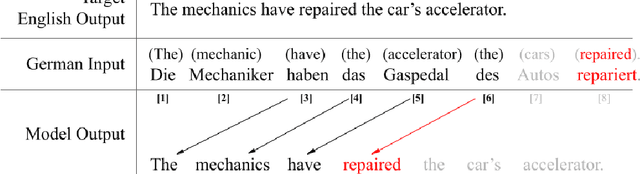

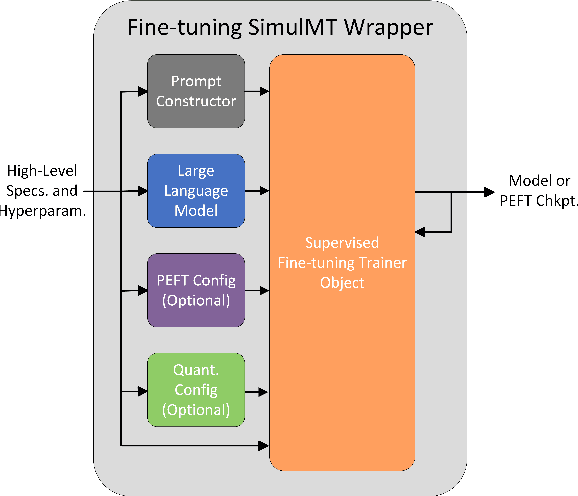

Large language models (LLMs) with billions of parameters and pretrained on massive amounts of data are now capable of near or better than state-of-the-art performance in a variety of downstream natural language processing tasks. Neural machine translation (NMT) is one such task that LLMs have been applied to with great success. However, little research has focused on applying LLMs to the more difficult subset of NMT called simultaneous translation (SimulMT), where translation begins before the entire source context is available to the model. In this paper, we address key challenges facing LLMs fine-tuned for SimulMT, validate classical SimulMT concepts and practices in the context of LLMs, explore adapting LLMs that are fine-tuned for NMT to the task of SimulMT, and introduce Simul-LLM, the first open-source fine-tuning and evaluation pipeline development framework for LLMs focused on SimulMT.
Partitioning-Guided K-Means: Extreme Empty Cluster Resolution for Extreme Model Compression
Jun 24, 2023Compactness in deep learning can be critical to a model's viability in low-resource applications, and a common approach to extreme model compression is quantization. We consider Iterative Product Quantization (iPQ) with Quant-Noise to be state-of-the-art in this area, but this quantization framework suffers from preventable inference quality degradation due to prevalent empty clusters. In this paper, we propose several novel enhancements aiming to improve the accuracy of iPQ with Quant-Noise by focusing on resolving empty clusters. Our contribution, which we call Partitioning-Guided k-means (PG k-means), is a heavily augmented k-means implementation composed of three main components. First, we propose a partitioning-based pre-assignment strategy that ensures no initial empty clusters and encourages an even weight-to-cluster distribution. Second, we propose an empirically superior empty cluster resolution heuristic executed via cautious partitioning of large clusters. Finally, we construct an optional optimization step that consolidates intuitively dense clusters of weights to ensure shared representation. The proposed approach consistently reduces the number of empty clusters in iPQ with Quant-Noise by 100x on average, uses 8x fewer iterations during empty cluster resolution, and improves overall model accuracy by up to 12%, when applied to RoBERTa on a variety of tasks in the GLUE benchmark.
Improving Autoregressive NLP Tasks via Modular Linearized Attention
Apr 24, 2023Various natural language processing (NLP) tasks necessitate models that are efficient and small based on their ultimate application at the edge or in other resource-constrained environments. While prior research has reduced the size of these models, increasing computational efficiency without considerable performance impacts remains difficult, especially for autoregressive tasks. This paper proposes {modular linearized attention (MLA), which combines multiple efficient attention mechanisms, including cosFormer, to maximize inference quality while achieving notable speedups. We validate this approach on several autoregressive NLP tasks, including speech-to-text neural machine translation (S2T NMT), speech-to-text simultaneous translation (SimulST), and autoregressive text-to-spectrogram, noting efficiency gains on TTS and competitive performance for NMT and SimulST during training and inference.