 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpurBreast: A Curated Dataset for Investigating Spurious Correlations in Real-world Breast MRI Classification
Oct 02, 2025Deep neural networks (DNNs) have demonstrated remarkable success in medical imaging, yet their real-world deployment remains challenging due to spurious correlations, where models can learn non-clinical features instead of meaningful medical patterns. Existing medical imaging datasets are not designed to systematically study this issue, largely due to restrictive licensing and limited supplementary patient data. To address this gap, we introduce SpurBreast, a curated breast MRI dataset that intentionally incorporates spurious correlations to evaluate their impact on model performance. Analyzing over 100 features involving patient, device, and imaging protocol, we identify two dominant spurious signals: magnetic field strength (a global feature influencing the entire image) and image orientation (a local feature affecting spatial alignment). Through controlled dataset splits, we demonstrate that DNNs can exploit these non-clinical signals, achieving high validation accuracy while failing to generalize to unbiased test data. Alongside these two datasets containing spurious correlations, we also provide benchmark datasets without spurious correlations, allowing researchers to systematically investigate clinically relevant and irrelevant features, uncertainty estimation, adversarial robustness, and generalization strategies. Models and datasets are available at https://github.com/utkuozbulak/spurbreast.
When Tracking Fails: Analyzing Failure Modes of SAM2 for Point-Based Tracking in Surgical Videos
Oct 02, 2025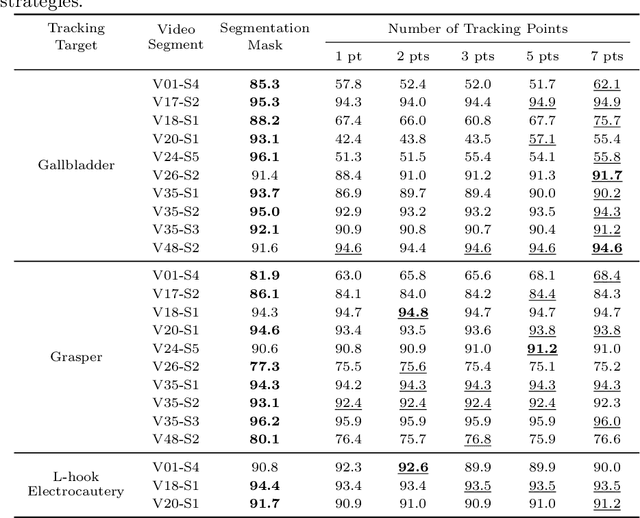
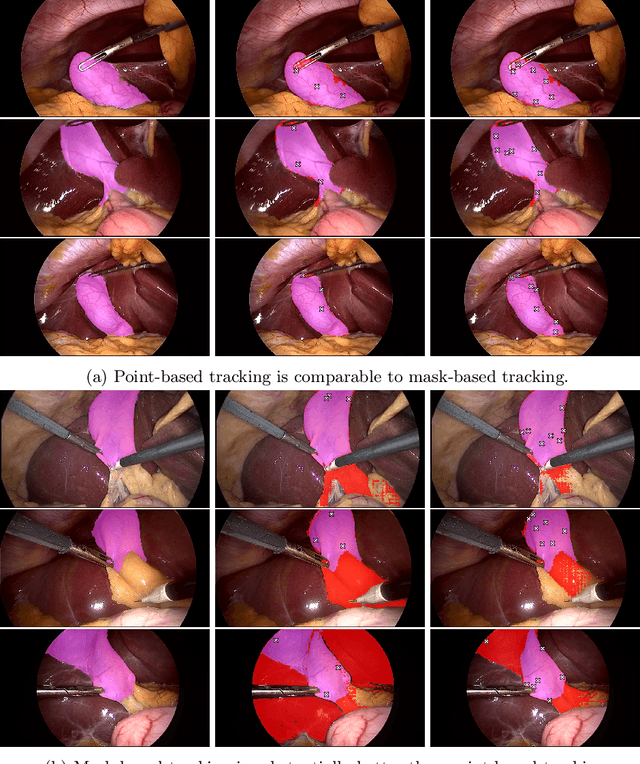
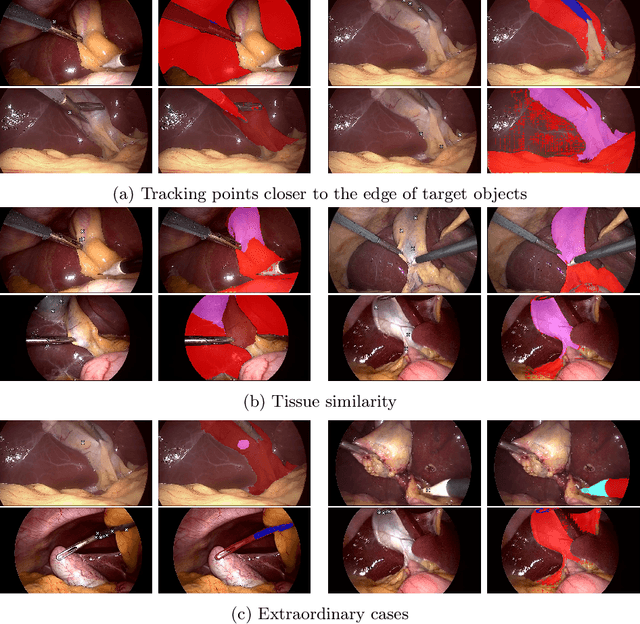
Video object segmentation (VOS) models such as SAM2 offer promising zero-shot tracking capabilities for surgical videos using minimal user input. Among the available input types, point-based tracking offers an efficient and low-cost alternative, yet its reliability and failure cases in complex surgical environments are not well understood. In this work, we systematically analyze the failure modes of point-based tracking in laparoscopic cholecystectomy videos. Focusing on three surgical targets, the gallbladder, grasper, and L-hook electrocautery, we compare the performance of point-based tracking with segmentation mask initialization. Our results show that point-based tracking is competitive for surgical tools but consistently underperforms for anatomical targets, where tissue similarity and ambiguous boundaries lead to failure. Through qualitative analysis, we reveal key factors influencing tracking outcomes and provide several actionable recommendations for selecting and placing tracking points to improve performance in surgical video analysis.
Detecting Regional Spurious Correlations in Vision Transformers via Token Discarding
Sep 04, 2025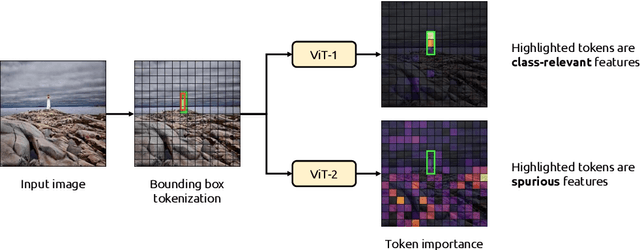

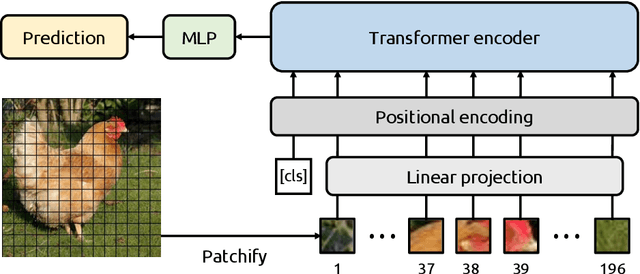

Due to their powerful feature association capabilities, neural network-based computer vision models have the ability to detect and exploit unintended patterns within the data, potentially leading to correct predictions based on incorrect or unintended but statistically relevant signals. These clues may vary from simple color aberrations to small texts within the image. In situations where these unintended signals align with the predictive task, models can mistakenly link these features with the task and rely on them for making predictions. This phenomenon is referred to as spurious correlations, where patterns appear to be associated with the task but are actually coincidental. As a result, detection and mitigation of spurious correlations have become crucial tasks for building trustworthy, reliable, and generalizable machine learning models. In this work, we present a novel method to detect spurious correlations in vision transformers, a type of neural network architecture that gained significant popularity in recent years. Using both supervised and self-supervised trained models, we present large-scale experiments on the ImageNet dataset demonstrating the ability of the proposed method to identify spurious correlations. We also find that, even if the same architecture is used, the training methodology has a significant impact on the model's reliance on spurious correlations. Furthermore, we show that certain classes in the ImageNet dataset contain spurious signals that are easily detected by the models and discuss the underlying reasons for those spurious signals. In light of our findings, we provide an exhaustive list of the aforementioned images and call for caution in their use in future research efforts. Lastly, we present a case study investigating spurious signals in invasive breast mass classification, grounding our work in real-world scenarios.
Evaluating Visual Explanations of Attention Maps for Transformer-based Medical Imaging
Mar 12, 2025Although Vision Transformers (ViTs) have recently demonstrated superior performance in medical imaging problems, they face explainability issues similar to previous architectures such as convolutional neural networks. Recent research efforts suggest that attention maps, which are part of decision-making process of ViTs can potentially address the explainability issue by identifying regions influencing predictions, especially in models pretrained with self-supervised learning. In this work, we compare the visual explanations of attention maps to other commonly used methods for medical imaging problems. To do so, we employ four distinct medical imaging datasets that involve the identification of (1) colonic polyps, (2) breast tumors, (3) esophageal inflammation, and (4) bone fractures and hardware implants. Through large-scale experiments on the aforementioned datasets using various supervised and self-supervised pretrained ViTs, we find that although attention maps show promise under certain conditions and generally surpass GradCAM in explainability, they are outperformed by transformer-specific interpretability methods. Our findings indicate that the efficacy of attention maps as a method of interpretability is context-dependent and may be limited as they do not consistently provide the comprehensive insights required for robust medical decision-making.
One Patient's Annotation is Another One's Initialization: Towards Zero-Shot Surgical Video Segmentation with Cross-Patient Initialization
Mar 04, 2025Video object segmentation is an emerging technology that is well-suited for real-time surgical video segmentation, offering valuable clinical assistance in the operating room by ensuring consistent frame tracking. However, its adoption is limited by the need for manual intervention to select the tracked object, making it impractical in surgical settings. In this work, we tackle this challenge with an innovative solution: using previously annotated frames from other patients as the tracking frames. We find that this unconventional approach can match or even surpass the performance of using patients' own tracking frames, enabling more autonomous and efficient AI-assisted surgical workflows. Furthermore, we analyze the benefits and limitations of this approach, highlighting its potential to enhance segmentation accuracy while reducing the need for manual input. Our findings provide insights into key factors influencing performance, offering a foundation for future research on optimizing cross-patient frame selection for real-time surgical video analysis.
Less is More? Revisiting the Importance of Frame Rate in Real-Time Zero-Shot Surgical Video Segmentation
Feb 28, 2025Real-time video segmentation is a promising feature for AI-assisted surgery, providing intraoperative guidance by identifying surgical tools and anatomical structures. However, deploying state-of-the-art segmentation models, such as SAM2, in real-time settings is computationally demanding, which makes it essential to balance frame rate and segmentation performance. In this study, we investigate the impact of frame rate on zero-shot surgical video segmentation, evaluating SAM2's effectiveness across multiple frame sampling rates for cholecystectomy procedures. Surprisingly, our findings indicate that in conventional evaluation settings, frame rates as low as a single frame per second can outperform 25 FPS, as fewer frames smooth out segmentation inconsistencies. However, when assessed in a real-time streaming scenario, higher frame rates yield superior temporal coherence and stability, particularly for dynamic objects such as surgical graspers. Finally, we investigate human perception of real-time surgical video segmentation among professionals who work closely with such data and find that respondents consistently prefer high FPS segmentation mask overlays, reinforcing the importance of real-time evaluation in AI-assisted surgery.
Exploring Patient Data Requirements in Training Effective AI Models for MRI-based Breast Cancer Classification
Feb 22, 2025The past decade has witnessed a substantial increase in the number of startups and companies offering AI-based solutions for clinical decision support in medical institutions. However, the critical nature of medical decision-making raises several concerns about relying on external software. Key issues include potential variations in image modalities and the medical devices used to obtain these images, potential legal issues, and adversarial attacks. Fortunately, the open-source nature of machine learning research has made foundation models publicly available and straightforward to use for medical applications. This accessibility allows medical institutions to train their own AI-based models, thereby mitigating the aforementioned concerns. Given this context, an important question arises: how much data do medical institutions need to train effective AI models? In this study, we explore this question in relation to breast cancer detection, a particularly contested area due to the prevalence of this disease, which affects approximately 1 in every 8 women. Through large-scale experiments on various patient sizes in the training set, we show that medical institutions do not need a decade's worth of MRI images to train an AI model that performs competitively with the state-of-the-art, provided the model leverages foundation models. Furthermore, we observe that for patient counts greater than 50, the number of patients in the training set has a negligible impact on the performance of models and that simple ensembles further improve the results without additional complexity.
Identifying Critical Tokens for Accurate Predictions in Transformer-based Medical Imaging Models
Jan 26, 2025With the advancements in self-supervised learning (SSL), transformer-based computer vision models have recently demonstrated superior results compared to convolutional neural networks (CNNs) and are poised to dominate the field of artificial intelligence (AI)-based medical imaging in the upcoming years. Nevertheless, similar to CNNs, unveiling the decision-making process of transformer-based models remains a challenge. In this work, we take a step towards demystifying the decision-making process of transformer-based medical imaging models and propose Token Insight, a novel method that identifies the critical tokens that contribute to the prediction made by the model. Our method relies on the principled approach of token discarding native to transformer-based models, requires no additional module, and can be applied to any transformer model. Using the proposed approach, we quantify the importance of each token based on its contribution to the prediction and enable a more nuanced understanding of the model's decisions. Our experimental results which are showcased on the problem of colonic polyp identification using both supervised and self-supervised pretrained vision transformers indicate that Token Insight contributes to a more transparent and interpretable transformer-based medical imaging model, fostering trust and facilitating broader adoption in clinical settings.
Self-supervised Benchmark Lottery on ImageNet: Do Marginal Improvements Translate to Improvements on Similar Datasets?
Jan 26, 2025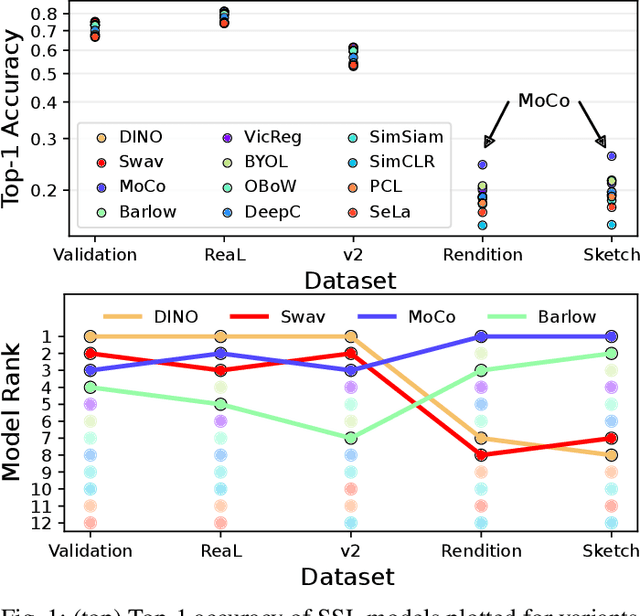

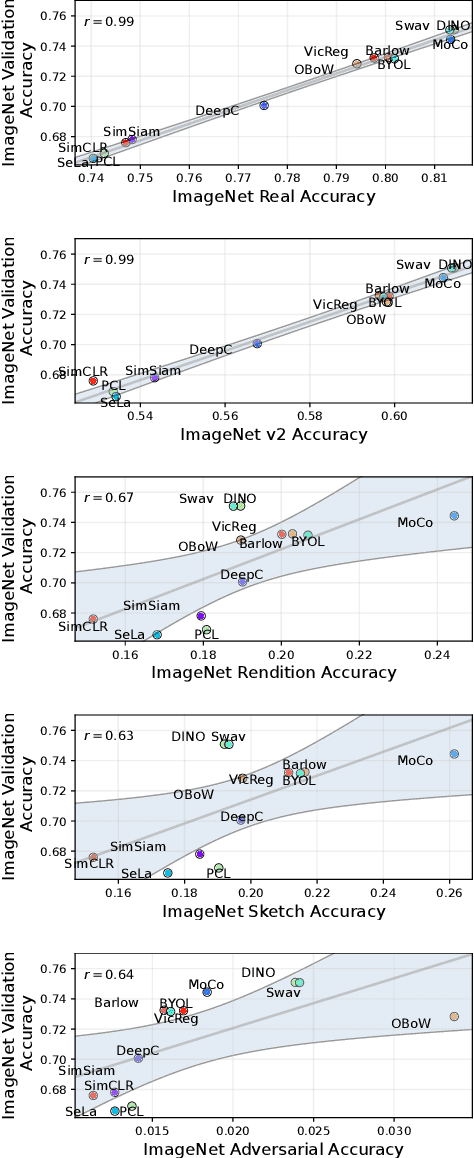
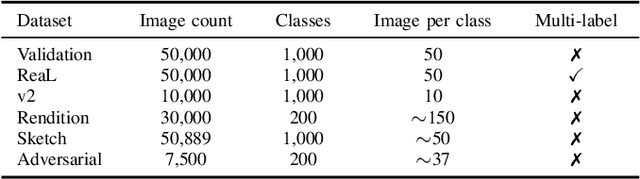
Machine learning (ML) research strongly relies on benchmarks in order to determine the relative effectiveness of newly proposed models. Recently, a number of prominent research effort argued that a number of models that improve the state-of-the-art by a small margin tend to do so by winning what they call a "benchmark lottery". An important benchmark in the field of machine learning and computer vision is the ImageNet where newly proposed models are often showcased based on their performance on this dataset. Given the large number of self-supervised learning (SSL) frameworks that has been proposed in the past couple of years each coming with marginal improvements on the ImageNet dataset, in this work, we evaluate whether those marginal improvements on ImageNet translate to improvements on similar datasets or not. To do so, we investigate twelve popular SSL frameworks on five ImageNet variants and discover that models that seem to perform well on ImageNet may experience significant performance declines on similar datasets. Specifically, state-of-the-art frameworks such as DINO and Swav, which are praised for their performance, exhibit substantial drops in performance while MoCo and Barlow Twins displays comparatively good results. As a result, we argue that otherwise good and desirable properties of models remain hidden when benchmarking is only performed on the ImageNet validation set, making us call for more adequate benchmarking. To avoid the "benchmark lottery" on ImageNet and to ensure a fair benchmarking process, we investigate the usage of a unified metric that takes into account the performance of models on other ImageNet variant datasets.
Color Flow Imaging Microscopy Improves Identification of Stress Sources of Protein Aggregates in Biopharmaceuticals
Jan 26, 2025Protein-based therapeutics play a pivotal role in modern medicine targeting various diseases. Despite their therapeutic importance, these products can aggregate and form subvisible particles (SvPs), which can compromise their efficacy and trigger immunological responses, emphasizing the critical need for robust monitoring techniques. Flow Imaging Microscopy (FIM) has been a significant advancement in detecting SvPs, evolving from monochrome to more recently incorporating color imaging. Complementing SvP images obtained via FIM, deep learning techniques have recently been employed successfully for stress source identification of monochrome SvPs. In this study, we explore the potential of color FIM to enhance the characterization of stress sources in SvPs. To achieve this, we curate a new dataset comprising 16,000 SvPs from eight commercial monoclonal antibodies subjected to heat and mechanical stress. Using both supervised and self-supervised convolutional neural networks, as well as vision transformers in large-scale experiments, we demonstrate that deep learning with color FIM images consistently outperforms monochrome images, thus highlighting the potential of color FIM in stress source classification compared to its monochrome counterparts.