 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Regional Spurious Correlations in Vision Transformers via Token Discarding
Sep 04, 2025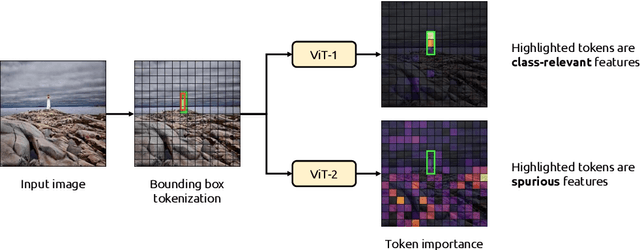


Due to their powerful feature association capabilities, neural network-based computer vision models have the ability to detect and exploit unintended patterns within the data, potentially leading to correct predictions based on incorrect or unintended but statistically relevant signals. These clues may vary from simple color aberrations to small texts within the image. In situations where these unintended signals align with the predictive task, models can mistakenly link these features with the task and rely on them for making predictions. This phenomenon is referred to as spurious correlations, where patterns appear to be associated with the task but are actually coincidental. As a result, detection and mitigation of spurious correlations have become crucial tasks for building trustworthy, reliable, and generalizable machine learning models. In this work, we present a novel method to detect spurious correlations in vision transformers, a type of neural network architecture that gained significant popularity in recent years. Using both supervised and self-supervised trained models, we present large-scale experiments on the ImageNet dataset demonstrating the ability of the proposed method to identify spurious correlations. We also find that, even if the same architecture is used, the training methodology has a significant impact on the model's reliance on spurious correlations. Furthermore, we show that certain classes in the ImageNet dataset contain spurious signals that are easily detected by the models and discuss the underlying reasons for those spurious signals. In light of our findings, we provide an exhaustive list of the aforementioned images and call for caution in their use in future research efforts. Lastly, we present a case study investigating spurious signals in invasive breast mass classification, grounding our work in real-world scenarios.
Re-assessing ImageNet: How aligned is its single-label assumption with its multi-label nature?
Dec 24, 2024ImageNet, an influential dataset in computer vision, is traditionally evaluated using single-label classification, which assumes that an image can be adequately described by a single concept or label. However, this approach may not fully capture the complex semantics within the images available in ImageNet, potentially hindering the development of models that effectively learn these intricacies. This study critically examines the prevalent single-label benchmarking approach and advocates for a shift to multi-label benchmarking for ImageNet. This shift would enable a more comprehensive assessment of the capabilities of deep neural network (DNN) models. We analyze the effectiveness of pre-trained state-of-the-art DNNs on ImageNet and one of its variants, ImageNetV2. Studies in the literature have reported unexpected accuracy drops of 11% to 14% on ImageNetV2. Our findings show that these reported declines are largely attributable to a characteristic of the dataset that has not received sufficient attention -- the proportion of images with multiple labels. Taking this characteristic into account, the results of our experiments provide evidence that there is no substantial degradation in effectiveness on ImageNetV2. Furthermore, we acknowledge that ImageNet pre-trained models exhibit some capability at capturing the multi-label nature of the dataset even though they were trained under the single-label assumption. Consequently, we propose a new evaluation approach to augment existing approaches that assess this capability. Our findings highlight the importance of considering the multi-label nature of the ImageNet dataset during benchmarking. Failing to do so could lead to incorrect conclusions regarding the effectiveness of DNNs and divert research efforts from addressing other substantial challenges related to the reliability and robustness of these models.
Leveraging Human-Machine Interactions for Computer Vision Dataset Quality Enhancement
Jan 31, 2024Large-scale datasets for single-label multi-class classification, such as \emph{ImageNet-1k}, have been instrumental in advancing deep learning and computer vision. However, a critical and often understudied aspect is the comprehensive quality assessment of these datasets, especially regarding potential multi-label annotation errors. In this paper, we introduce a lightweight, user-friendly, and scalable framework that synergizes human and machine intelligence for efficient dataset validation and quality enhancement. We term this novel framework \emph{Multilabelfy}. Central to Multilabelfy is an adaptable web-based platform that systematically guides annotators through the re-evaluation process, effectively leveraging human-machine interactions to enhance dataset quality. By using Multilabelfy on the ImageNetV2 dataset, we found that approximately $47.88\%$ of the images contained at least two labels, underscoring the need for more rigorous assessments of such influential datasets. Furthermore, our analysis showed a negative correlation between the number of potential labels per image and model top-1 accuracy, illuminating a crucial factor in model evaluation and selection. Our open-source framework, Multilabelfy, offers a convenient, lightweight solution for dataset enhancement, emphasizing multi-label proportions. This study tackles major challenges in dataset integrity and provides key insights into model performance evaluation. Moreover, it underscores the advantages of integrating human expertise with machine capabilities to produce more robust models and trustworthy data development. The source code for Multilabelfy will be available at https://github.com/esla/Multilabelfy. \keywords{Computer Vision \and Dataset Quality Enhancement \and Dataset Validation \and Human-Computer Interaction \and Multi-label Annotation.}
Know Your Self-supervised Learning: A Survey on Image-based Generative and Discriminative Training
May 23, 2023

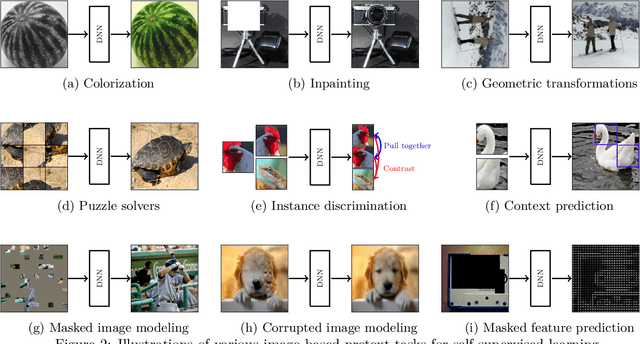
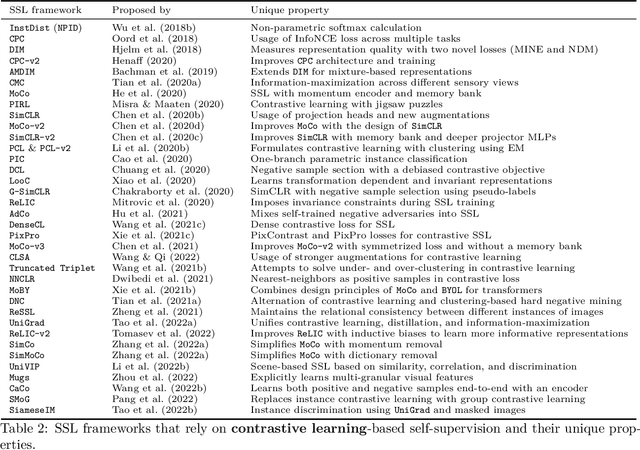
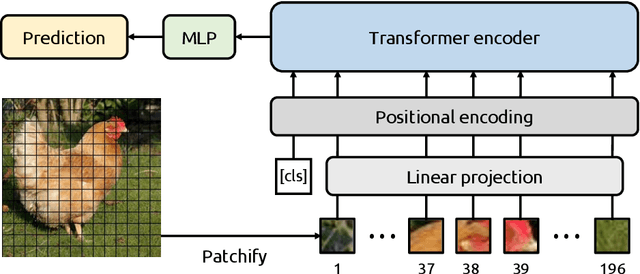
Although supervised learning has been highly successful in improving the state-of-the-art in the domain of image-based computer vision in the past, the margin of improvement has diminished significantly in recent years, indicating that a plateau is in sight. Meanwhile, the use of self-supervised learning (SSL) for the purpose of natural language processing (NLP) has seen tremendous successes during the past couple of years, with this new learning paradigm yielding powerful language models. Inspired by the excellent results obtained in the field of NLP, self-supervised methods that rely on clustering, contrastive learning, distillation, and information-maximization, which all fall under the banner of discriminative SSL, have experienced a swift uptake in the area of computer vision. Shortly afterwards, generative SSL frameworks that are mostly based on masked image modeling, complemented and surpassed the results obtained with discriminative SSL. Consequently, within a span of three years, over $100$ unique general-purpose frameworks for generative and discriminative SSL, with a focus on imaging, were proposed. In this survey, we review a plethora of research efforts conducted on image-oriented SSL, providing a historic view and paying attention to best practices as well as useful software packages. While doing so, we discuss pretext tasks for image-based SSL, as well as techniques that are commonly used in image-based SSL. Lastly, to aid researchers who aim at contributing to image-focused SSL, we outline a number of promising research directions.
* Published in Transactions on Machine Learning Research
A Principled Evaluation Protocol for Comparative Investigation of the Effectiveness of DNN Classification Models on Similar-but-non-identical Datasets
Sep 05, 2022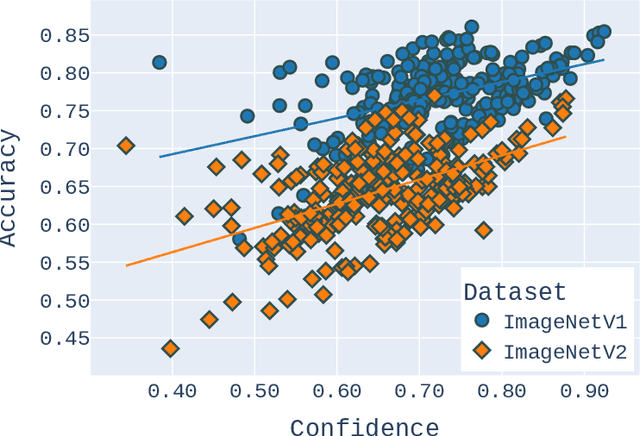

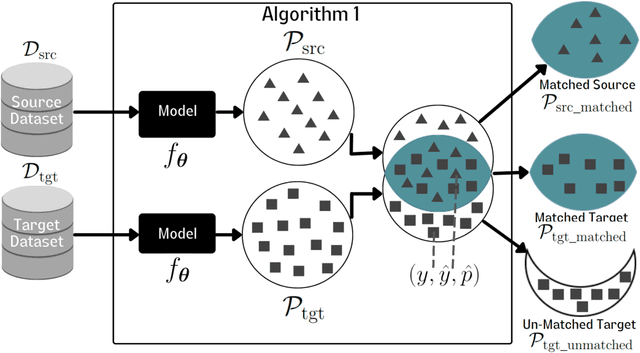

Deep Neural Network (DNN) models are increasingly evaluated using new replication test datasets, which have been carefully created to be similar to older and popular benchmark datasets. However, running counter to expectations, DNN classification models show significant, consistent, and largely unexplained degradation in accuracy on these replication test datasets. While the popular evaluation approach is to assess the accuracy of a model by making use of all the datapoints available in the respective test datasets, we argue that doing so hinders us from adequately capturing the behavior of DNN models and from having realistic expectations about their accuracy. Therefore, we propose a principled evaluation protocol that is suitable for performing comparative investigations of the accuracy of a DNN model on multiple test datasets, leveraging subsets of datapoints that can be selected using different criteria, including uncertainty-related information. By making use of this new evaluation protocol, we determined the accuracy of $564$ DNN models on both (1) the CIFAR-10 and ImageNet datasets and (2) their replication datasets. Our experimental results indicate that the observed accuracy degradation between established benchmark datasets and their replications is consistently lower (that is, models do perform better on the replication test datasets) than the accuracy degradation reported in published works, with these published works relying on conventional evaluation approaches that do not utilize uncertainty-related information.
Exact Feature Collisions in Neural Networks
May 31, 2022
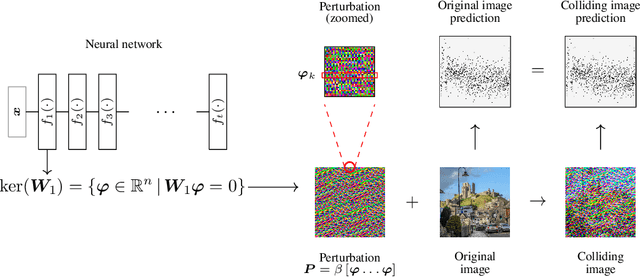

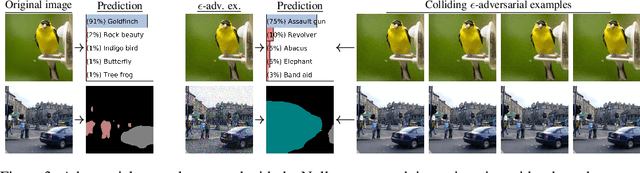
Predictions made by deep neural networks were shown to be highly sensitive to small changes made in the input space where such maliciously crafted data points containing small perturbations are being referred to as adversarial examples. On the other hand, recent research suggests that the same networks can also be extremely insensitive to changes of large magnitude, where predictions of two largely different data points can be mapped to approximately the same output. In such cases, features of two data points are said to approximately collide, thus leading to the largely similar predictions. Our results improve and extend the work of Li et al.(2019), laying out theoretical grounds for the data points that have colluding features from the perspective of weights of neural networks, revealing that neural networks not only suffer from features that approximately collide but also suffer from features that exactly collide. We identify the necessary conditions for the existence of such scenarios, hereby investigating a large number of DNNs that have been used to solve various computer vision problems. Furthermore, we propose the Null-space search, a numerical approach that does not rely on heuristics, to create data points with colliding features for any input and for any task, including, but not limited to, classification, localization, and segmentation.
Evaluating Adversarial Attacks on ImageNet: A Reality Check on Misclassification Classes
Nov 22, 2021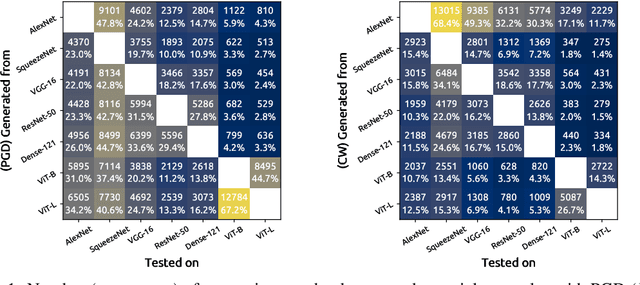


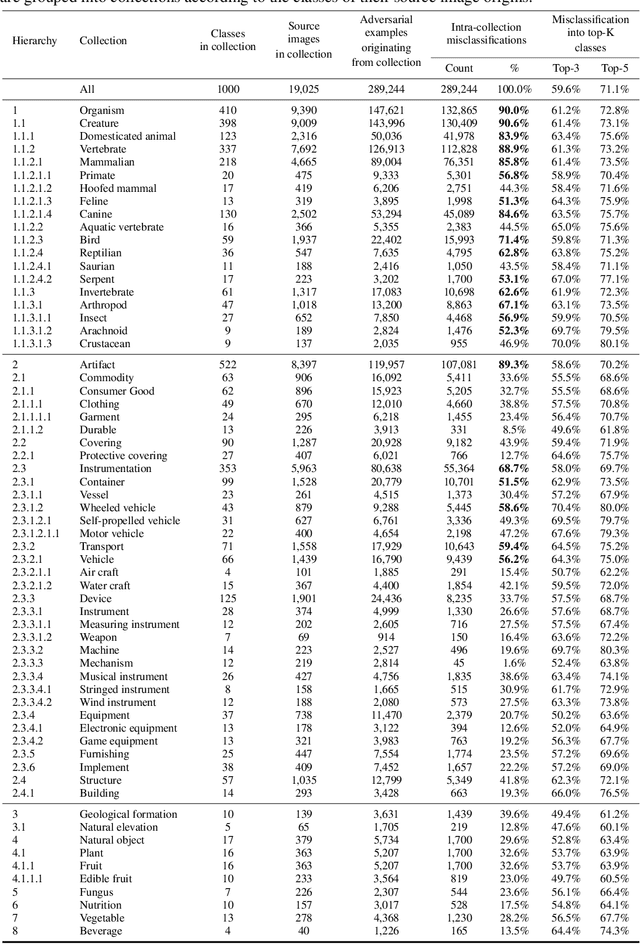
Although ImageNet was initially proposed as a dataset for performance benchmarking in the domain of computer vision, it also enabled a variety of other research efforts. Adversarial machine learning is one such research effort, employing deceptive inputs to fool models in making wrong predictions. To evaluate attacks and defenses in the field of adversarial machine learning, ImageNet remains one of the most frequently used datasets. However, a topic that is yet to be investigated is the nature of the classes into which adversarial examples are misclassified. In this paper, we perform a detailed analysis of these misclassification classes, leveraging the ImageNet class hierarchy and measuring the relative positions of the aforementioned type of classes in the unperturbed origins of the adversarial examples. We find that $71\%$ of the adversarial examples that achieve model-to-model adversarial transferability are misclassified into one of the top-5 classes predicted for the underlying source images. We also find that a large subset of untargeted misclassifications are, in fact, misclassifications into semantically similar classes. Based on these findings, we discuss the need to take into account the ImageNet class hierarchy when evaluating untargeted adversarial successes. Furthermore, we advocate for future research efforts to incorporate categorical information.
Selection of Source Images Heavily Influences the Effectiveness of Adversarial Attacks
Jun 16, 2021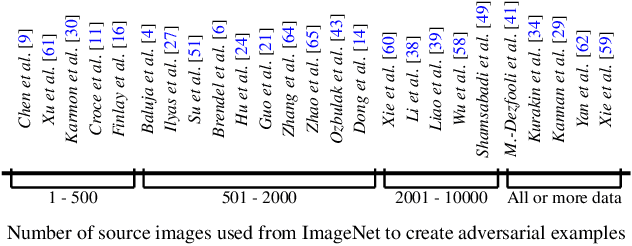
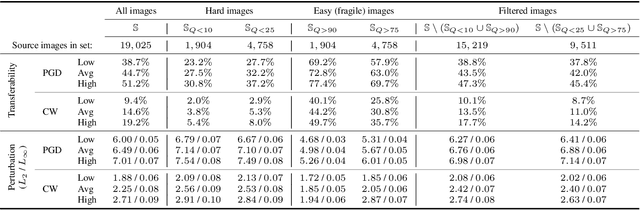
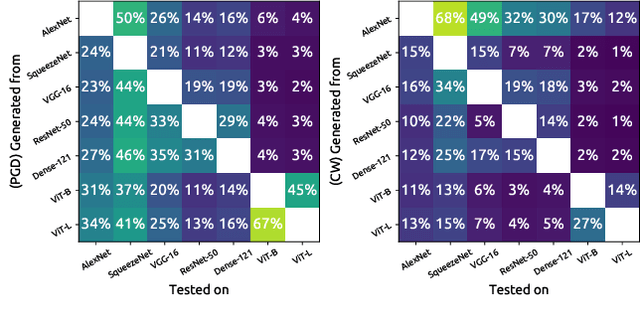
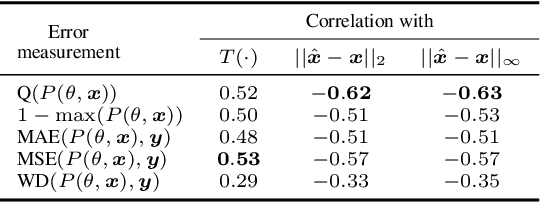
Although the adoption rate of deep neural networks (DNNs) has tremendously increased in recent years, a solution for their vulnerability against adversarial examples has not yet been found. As a result, substantial research efforts are dedicated to fix this weakness, with many studies typically using a subset of source images to generate adversarial examples, treating every image in this subset as equal. We demonstrate that, in fact, not every source image is equally suited for this kind of assessment. To do so, we devise a large-scale model-to-model transferability scenario for which we meticulously analyze the properties of adversarial examples, generated from every suitable source image in ImageNet by making use of two of the most frequently deployed attacks. In this transferability scenario, which involves seven distinct DNN models, including the recently proposed vision transformers, we reveal that it is possible to have a difference of up to $12.5\%$ in model-to-model transferability success, $1.01$ in average $L_2$ perturbation, and $0.03$ ($8/225$) in average $L_{\infty}$ perturbation when $1,000$ source images are sampled randomly among all suitable candidates. We then take one of the first steps in evaluating the robustness of images used to create adversarial examples, proposing a number of simple but effective methods to identify unsuitable source images, thus making it possible to mitigate extreme cases in experimentation and support high-quality benchmarking.
Investigating the significance of adversarial attacks and their relation to interpretability for radar-based human activity recognition systems
Jan 26, 2021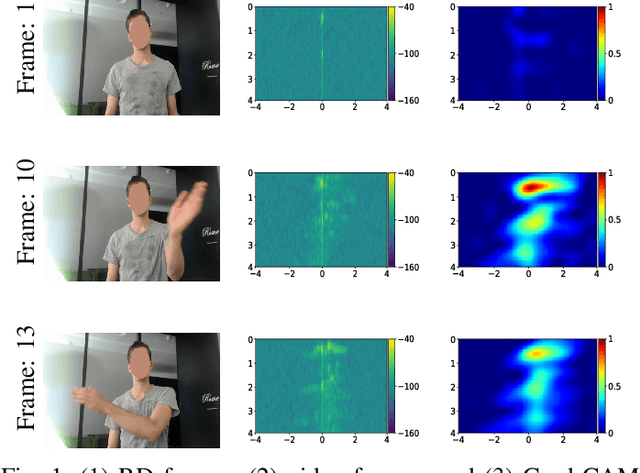
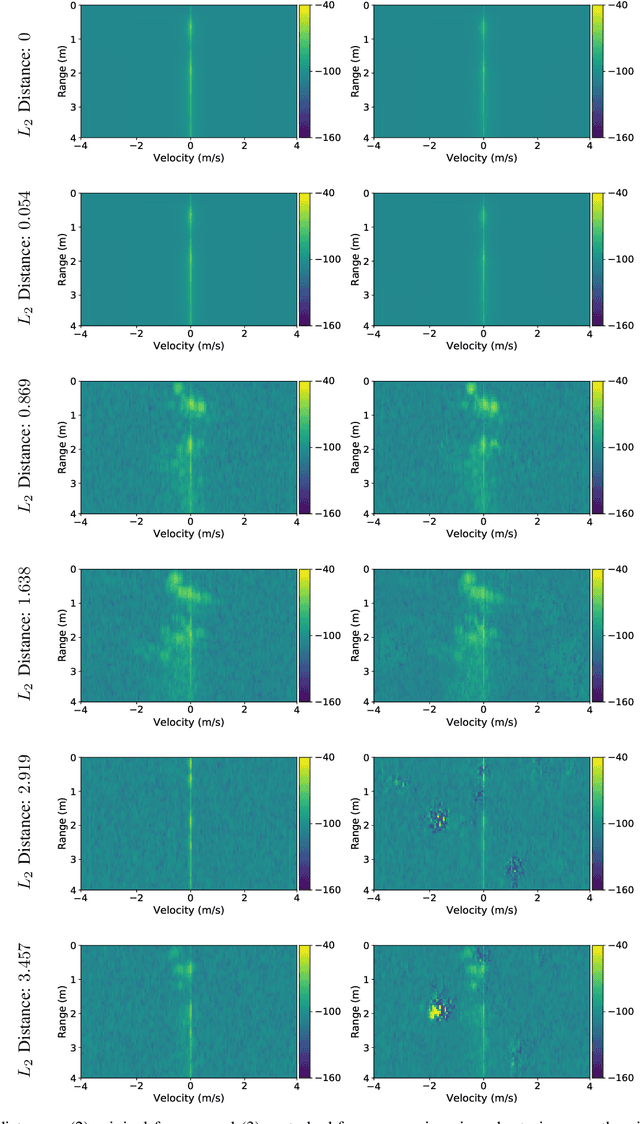
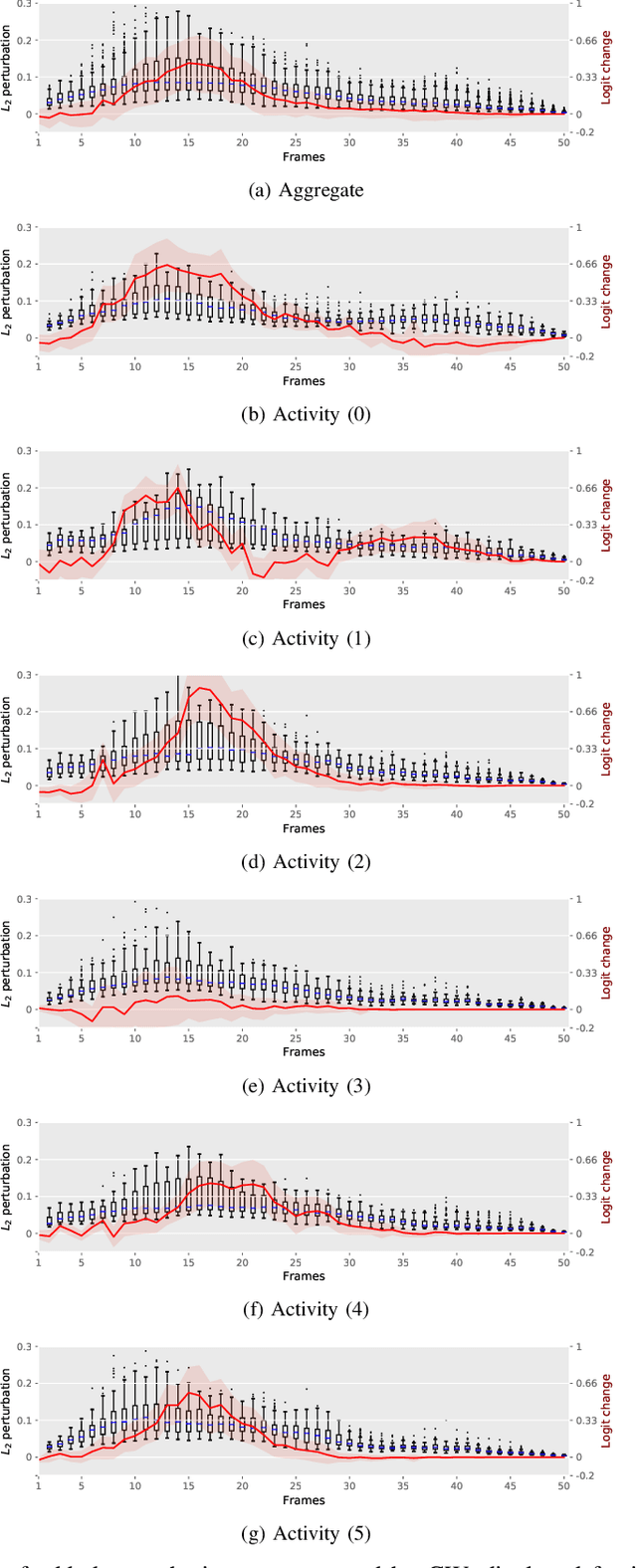
Given their substantial success in addressing a wide range of computer vision challenges, Convolutional Neural Networks (CNNs) are increasingly being used in smart home applications, with many of these applications relying on the automatic recognition of human activities. In this context, low-power radar devices have recently gained in popularity as recording sensors, given that the usage of these devices allows mitigating a number of privacy concerns, a key issue when making use of conventional video cameras. Another concern that is often cited when designing smart home applications is the resilience of these applications against cyberattacks. It is, for instance, well-known that the combination of images and CNNs is vulnerable against adversarial examples, mischievous data points that force machine learning models to generate wrong classifications during testing time. In this paper, we investigate the vulnerability of radar-based CNNs to adversarial attacks, and where these radar-based CNNs have been designed to recognize human gestures. Through experiments with four unique threat models, we show that radar-based CNNs are susceptible to both white- and black-box adversarial attacks. We also expose the existence of an extreme adversarial attack case, where it is possible to change the prediction made by the radar-based CNNs by only perturbing the padding of the inputs, without touching the frames where the action itself occurs. Moreover, we observe that gradient-based attacks exercise perturbation not randomly, but on important features of the input data. We highlight these important features by making use of Grad-CAM, a popular neural network interpretability method, hereby showing the connection between adversarial perturbation and prediction interpretability.
Regional Image Perturbation Reduces $L_p$ Norms of Adversarial Examples While Maintaining Model-to-model Transferability
Jul 07, 2020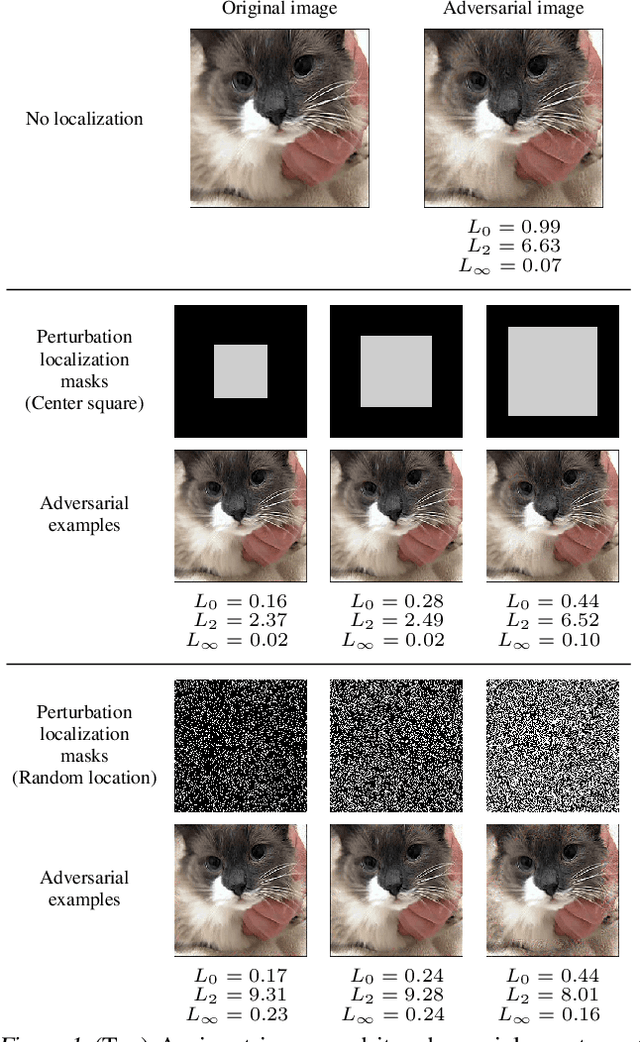
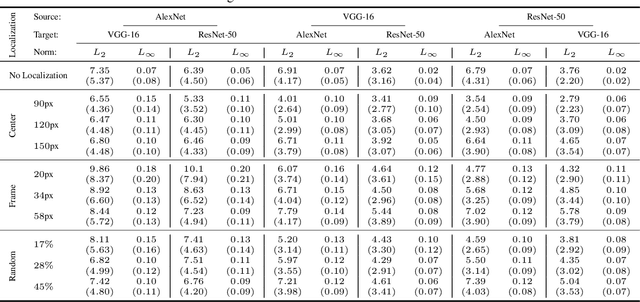

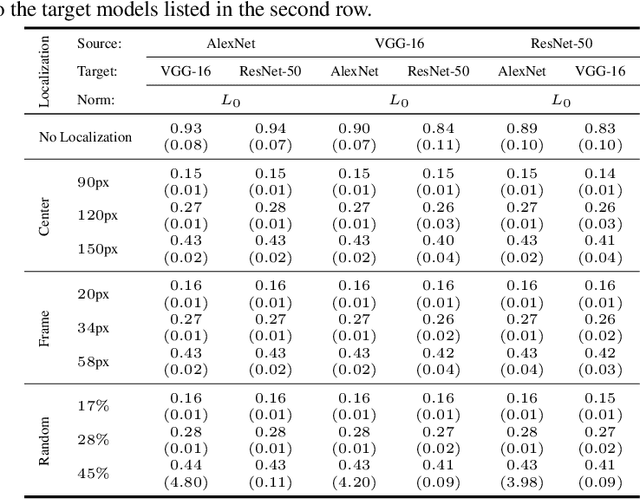
Regional adversarial attacks often rely on complicated methods for generating adversarial perturbations, making it hard to compare their efficacy against well-known attacks. In this study, we show that effective regional perturbations can be generated without resorting to complex methods. We develop a very simple regional adversarial perturbation attack method using cross-entropy sign, one of the most commonly used losses in adversarial machine learning. Our experiments on ImageNet with multiple models reveal that, on average, $76\%$ of the generated adversarial examples maintain model-to-model transferability when the perturbation is applied to local image regions. Depending on the selected region, these localized adversarial examples require significantly less $L_p$ norm distortion (for $p \in \{0, 2, \infty\}$) compared to their non-local counterparts. These localized attacks therefore have the potential to undermine defenses that claim robustness under the aforementioned norms.