 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Adversarial Attacks on ImageNet: A Reality Check on Misclassification Classes
Paper and Code
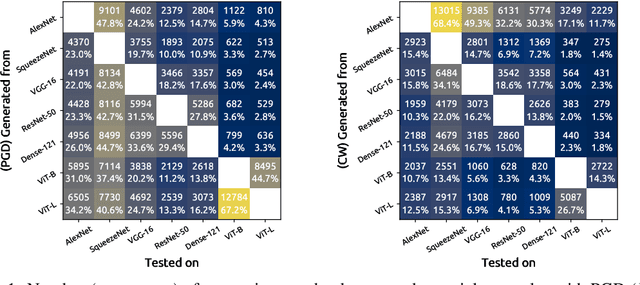


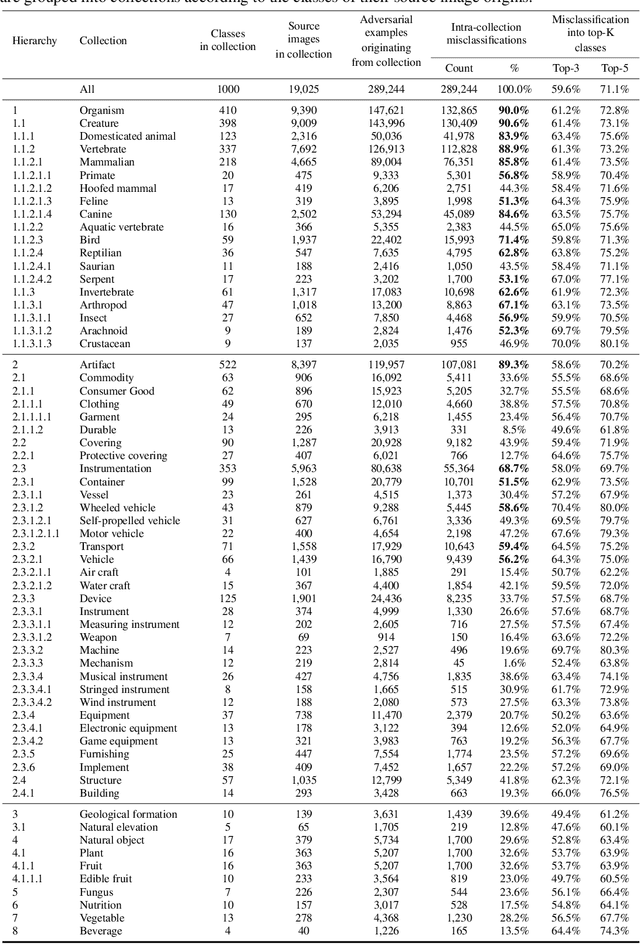
Although ImageNet was initially proposed as a dataset for performance benchmarking in the domain of computer vision, it also enabled a variety of other research efforts. Adversarial machine learning is one such research effort, employing deceptive inputs to fool models in making wrong predictions. To evaluate attacks and defenses in the field of adversarial machine learning, ImageNet remains one of the most frequently used datasets. However, a topic that is yet to be investigated is the nature of the classes into which adversarial examples are misclassified. In this paper, we perform a detailed analysis of these misclassification classes, leveraging the ImageNet class hierarchy and measuring the relative positions of the aforementioned type of classes in the unperturbed origins of the adversarial examples. We find that $71\%$ of the adversarial examples that achieve model-to-model adversarial transferability are misclassified into one of the top-5 classes predicted for the underlying source images. We also find that a large subset of untargeted misclassifications are, in fact, misclassifications into semantically similar classes. Based on these findings, we discuss the need to take into account the ImageNet class hierarchy when evaluating untargeted adversarial successes. Furthermore, we advocate for future research efforts to incorporate categorical information.