 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your Self-supervised Learning: A Survey on Image-based Generative and Discriminative Training
May 23, 2023

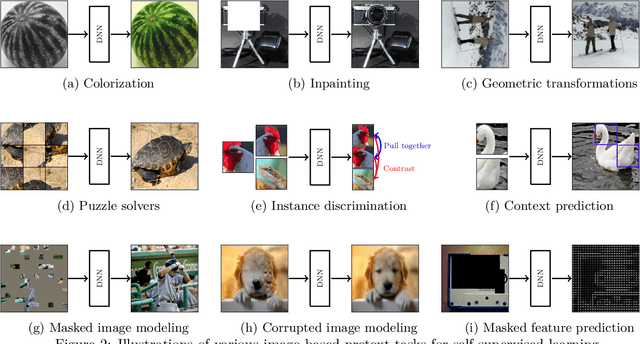
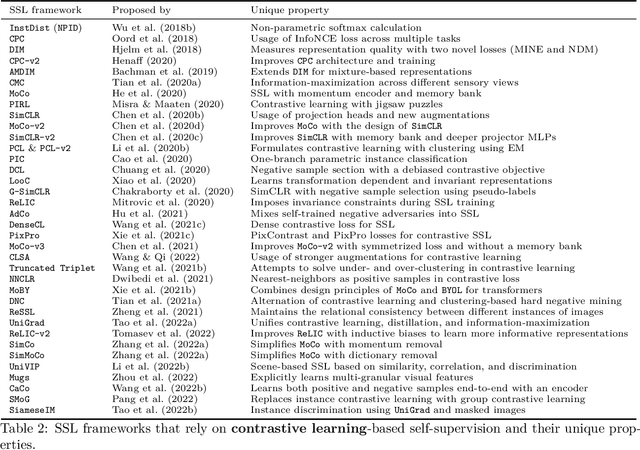
Although supervised learning has been highly successful in improving the state-of-the-art in the domain of image-based computer vision in the past, the margin of improvement has diminished significantly in recent years, indicating that a plateau is in sight. Meanwhile, the use of self-supervised learning (SSL) for the purpose of natural language processing (NLP) has seen tremendous successes during the past couple of years, with this new learning paradigm yielding powerful language models. Inspired by the excellent results obtained in the field of NLP, self-supervised methods that rely on clustering, contrastive learning, distillation, and information-maximization, which all fall under the banner of discriminative SSL, have experienced a swift uptake in the area of computer vision. Shortly afterwards, generative SSL frameworks that are mostly based on masked image modeling, complemented and surpassed the results obtained with discriminative SSL. Consequently, within a span of three years, over $100$ unique general-purpose frameworks for generative and discriminative SSL, with a focus on imaging, were proposed. In this survey, we review a plethora of research efforts conducted on image-oriented SSL, providing a historic view and paying attention to best practices as well as useful software packages. While doing so, we discuss pretext tasks for image-based SSL, as well as techniques that are commonly used in image-based SSL. Lastly, to aid researchers who aim at contributing to image-focused SSL, we outline a number of promising research directions.
* Published in Transactions on Machine Learning Research
SalienTrack: providing salient information for semi-automated self-tracking feedback with model explanations
Sep 21, 2021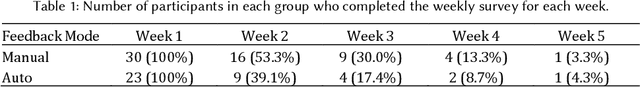
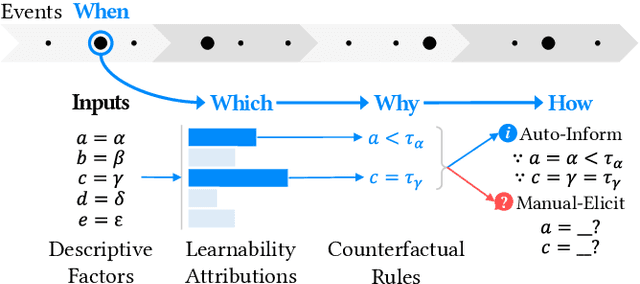
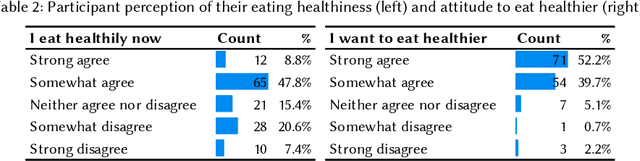
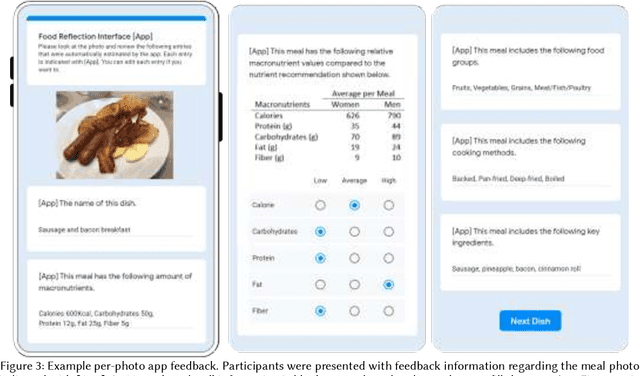
Self-tracking can improve people's awareness of their unhealthy behaviors to provide insights towards behavior change. Prior work has explored how self-trackers reflect on their logged data, but it remains unclear how much they learn from the tracking feedback, and which information is more useful. Indeed, the feedback can still be overwhelming, and making it concise can improve learning by increasing focus and reducing interpretation burden. We conducted a field study of mobile food logging with two feedback modes (manual journaling and automatic annotation of food images) and identified learning differences regarding nutrition, assessment, behavioral, and contextual information. We propose a Self-Tracking Feedback Saliency Framework to define when to provide feedback, on which specific information, why those details, and how to present them (as manual inquiry or automatic feedback). We propose SalienTrack to implement these requirements. Using the data collected from the user study, we trained a machine learning model to predict whether a user would learn from each tracked event. Using explainable AI (XAI) techniques, we identified the most salient features per instance and why they lead to positive learning outcomes. We discuss implications for learnability in self-tracking, and how adding model explainability expands opportunities for improving feedback experience.