 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalienTrack: providing salient information for semi-automated self-tracking feedback with model explanations
Sep 21, 2021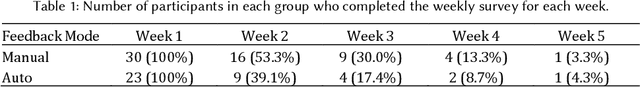
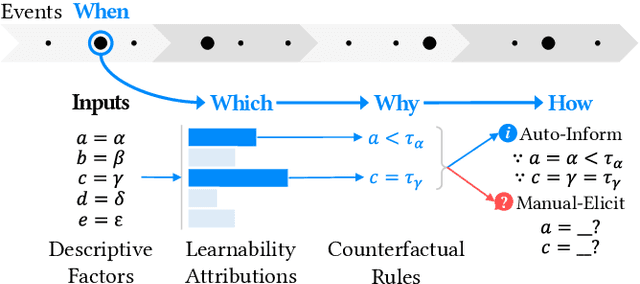
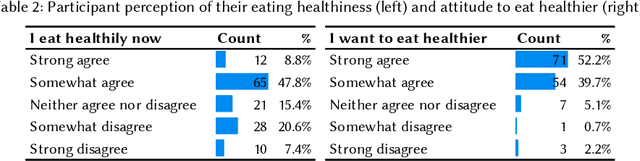
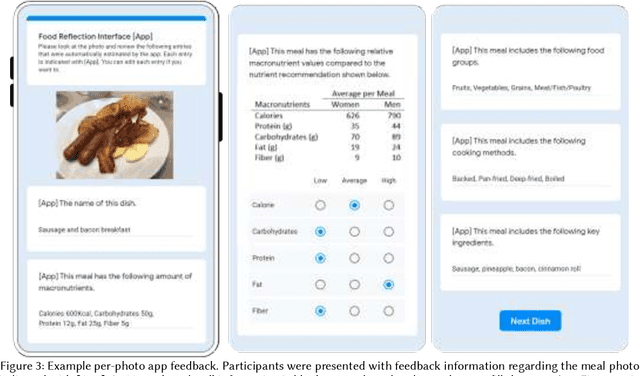
Self-tracking can improve people's awareness of their unhealthy behaviors to provide insights towards behavior change. Prior work has explored how self-trackers reflect on their logged data, but it remains unclear how much they learn from the tracking feedback, and which information is more useful. Indeed, the feedback can still be overwhelming, and making it concise can improve learning by increasing focus and reducing interpretation burden. We conducted a field study of mobile food logging with two feedback modes (manual journaling and automatic annotation of food images) and identified learning differences regarding nutrition, assessment, behavioral, and contextual information. We propose a Self-Tracking Feedback Saliency Framework to define when to provide feedback, on which specific information, why those details, and how to present them (as manual inquiry or automatic feedback). We propose SalienTrack to implement these requirements. Using the data collected from the user study, we trained a machine learning model to predict whether a user would learn from each tracked event. Using explainable AI (XAI) techniques, we identified the most salient features per instance and why they lead to positive learning outcomes. We discuss implications for learnability in self-tracking, and how adding model explainability expands opportunities for improving feedback experience.
Impact of Explanation on Trust of a Novel Mobile Robot
Jan 26, 2021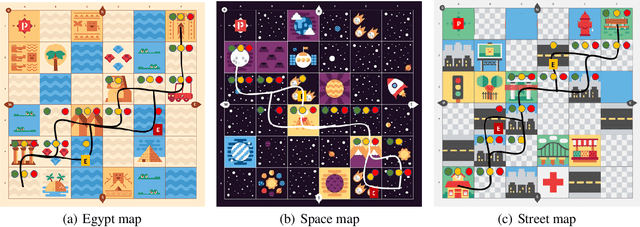

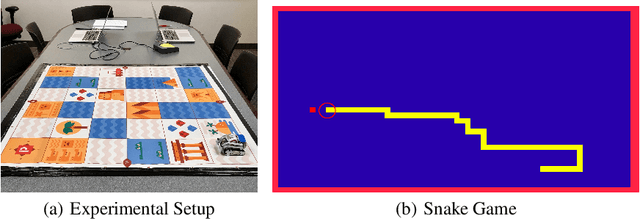
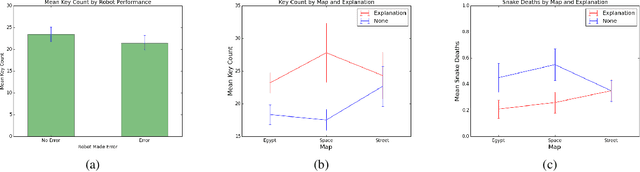
One challenge with introducing robots into novel environments is misalignment between supervisor expectations and reality, which can greatly affect a user's trust and continued use of the robot. We performed an experiment to test whether the presence of an explanation of expected robot behavior affected a supervisor's trust in an autonomous robot. We measured trust both subjectively through surveys and objectively through a dual-task experiment design to capture supervisors' neglect tolerance (i.e., their willingness to perform their own task while the robot is acting autonomously). Our objective results show that explanations can help counteract the novelty effect of seeing a new robot perform in an unknown environment. Participants who received an explanation of the robot's behavior were more likely to focus on their own task at the risk of neglecting their robot supervision task during the first trials of the robot's behavior compared to those who did not receive an explanation. However, this effect diminished after seeing multiple trials, and participants who received explanations were equally trusting of the robot's behavior as those who did not receive explanations. Interestingly, participants were not able to identify their own changes in trust through their survey responses, demonstrating that the dual-task design measured subtler changes in a supervisor's trust.
* 9 pages, 3 figures
Understanding Convolutional Networks with APPLE : Automatic Patch Pattern Labeling for Explanation
Feb 11, 2018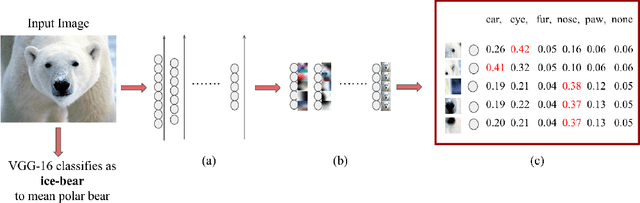
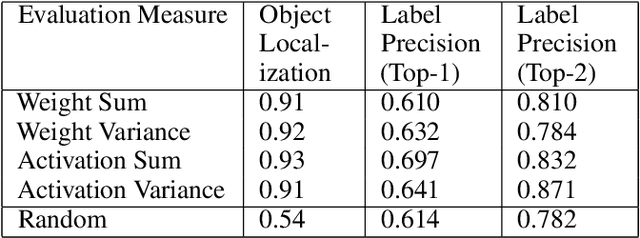


With the success of deep learning, recent efforts have been focused on analyzing how learned networks make their classifications. We are interested in analyzing the network output based on the network structure and information flow through the network layers. We contribute an algorithm for 1) analyzing a deep network to find neurons that are 'important' in terms of the network classification outcome, and 2)automatically labeling the patches of the input image that activate these important neurons. We propose several measures of importance for neurons and demonstrate that our technique can be used to gain insight into, and explain how a network decomposes an image to make its final classification.
UAV and Service Robot Coordination for Indoor Object Search Tasks
Sep 26, 2017



Our CoBot robots have successfully performed a variety of service tasks in our multi-building environment including accompanying people to meetings and delivering objects to offices due to its navigation and localization capabilities. However, they lack the capability to visually search over desks and other confined locations for an object of interest. Conversely, an inexpensive GPS-denied quadcopter platform such as the Parrot ARDrone 2.0 could perform this object search task if it had access to reasonable localization. In this paper, we propose the concept of coordination between CoBot and the Parrot ARDrone 2.0 to perform service-based object search tasks, in which CoBot localizes and navigates to the general search areas carrying the ARDrone and the ARDrone searches locally for objects. We propose a vision-based moving target navigation algorithm that enables the ARDrone to localize with respect to CoBot, search for objects, and return to the CoBot for future searches. We demonstrate our algorithm in indoor environments on several search trajectories.
Towards Visual Explanations for Convolutional Neural Networks via Input Resampling
Aug 16, 2017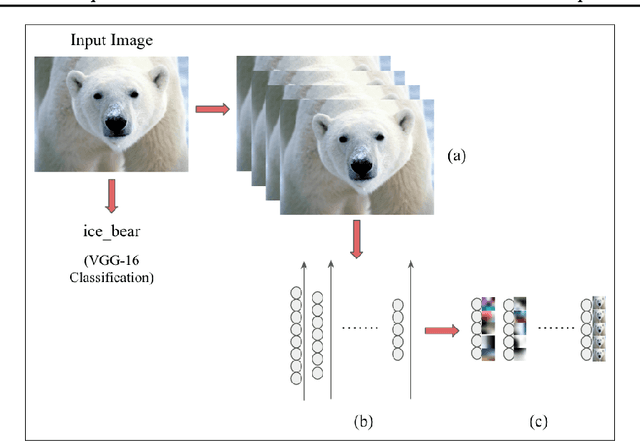
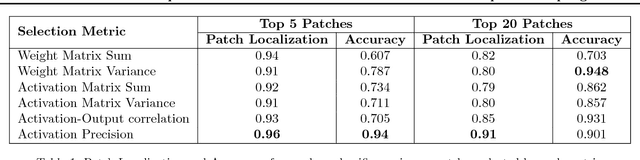
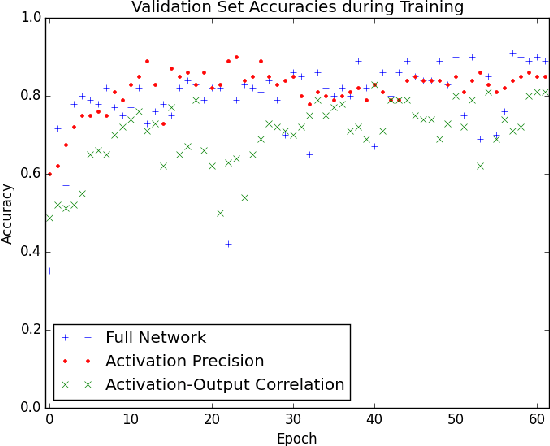
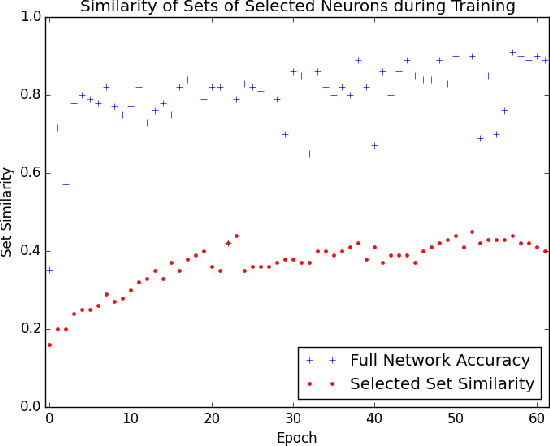
The predictive power of neural networks often costs model interpretability. Several techniques have been developed for explaining model outputs in terms of input features; however, it is difficult to translate such interpretations into actionable insight. Here, we propose a framework to analyze predictions in terms of the model's internal features by inspecting information flow through the network. Given a trained network and a test image, we select neurons by two metrics, both measured over a set of images created by perturbations to the input image: (1) magnitude of the correlation between the neuron activation and the network output and (2) precision of the neuron activation. We show that the former metric selects neurons that exert large influence over the network output while the latter metric selects neurons that activate on generalizable features. By comparing the sets of neurons selected by these two metrics, our framework suggests a way to investigate the internal attention mechanisms of convolutional neural networks.
Obstacle Avoidance through Deep Networks based Intermediate Perception
Apr 27, 2017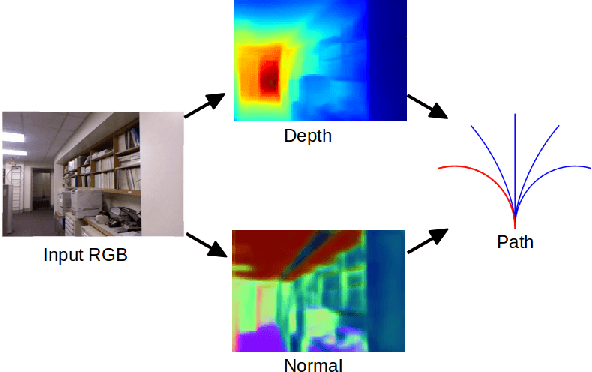

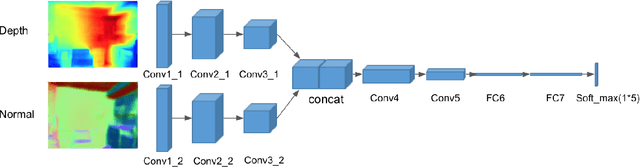
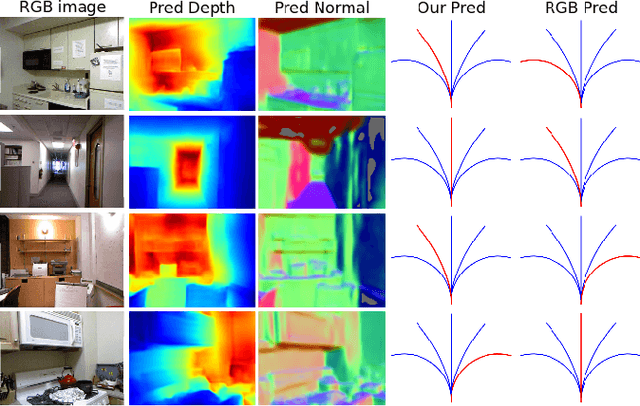
Obstacle avoidance from monocular images is a challenging problem for robots. Though multi-view structure-from-motion could build 3D maps, it is not robust in textureless environments. Some learning based methods exploit human demonstration to predict a steering command directly from a single image. However, this method is usually biased towards certain tasks or demonstration scenarios and also biased by human understanding. In this paper, we propose a new method to predict a trajectory from images. We train our system on more diverse NYUv2 dataset. The ground truth trajectory is computed from the designed cost functions automatically. The Convolutional Neural Network perception is divided into two stages: first, predict depth map and surface normal from RGB images, which are two important geometric properties related to 3D obstacle representation. Second, predict the trajectory from the depth and normal. Results show that our intermediate perception increases the accuracy by 20% than the direct prediction. Our model generalizes well to other public indoor datasets and is also demonstrated for robot flights in simulation and experiments.