 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObstacle Avoidance through Deep Networks based Intermediate Perception
Paper and Code
Apr 27, 2017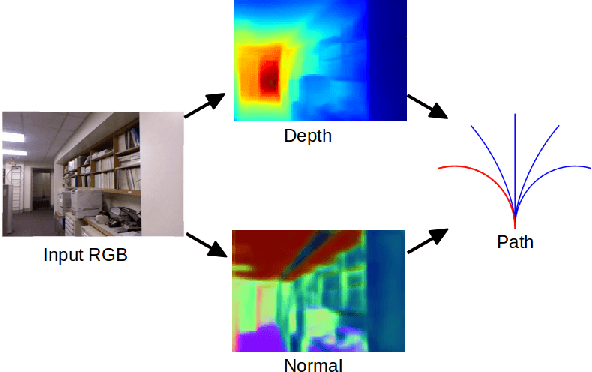

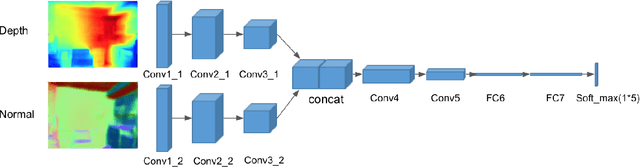
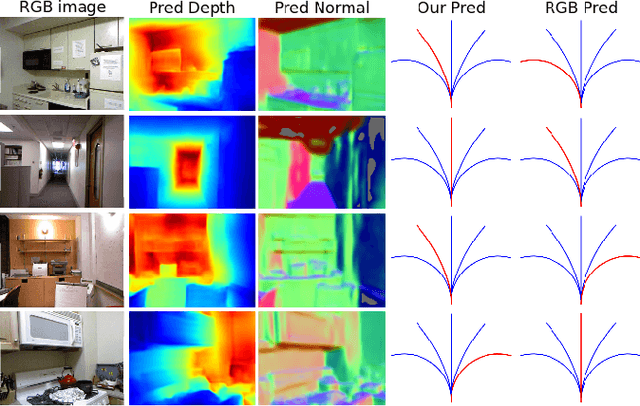
Obstacle avoidance from monocular images is a challenging problem for robots. Though multi-view structure-from-motion could build 3D maps, it is not robust in textureless environments. Some learning based methods exploit human demonstration to predict a steering command directly from a single image. However, this method is usually biased towards certain tasks or demonstration scenarios and also biased by human understanding. In this paper, we propose a new method to predict a trajectory from images. We train our system on more diverse NYUv2 dataset. The ground truth trajectory is computed from the designed cost functions automatically. The Convolutional Neural Network perception is divided into two stages: first, predict depth map and surface normal from RGB images, which are two important geometric properties related to 3D obstacle representation. Second, predict the trajectory from the depth and normal. Results show that our intermediate perception increases the accuracy by 20% than the direct prediction. Our model generalizes well to other public indoor datasets and is also demonstrated for robot flights in simulation and experiments.